 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputer-aided mechanism design: designing revenue-optimal mechanisms via neural networks
May 09, 2018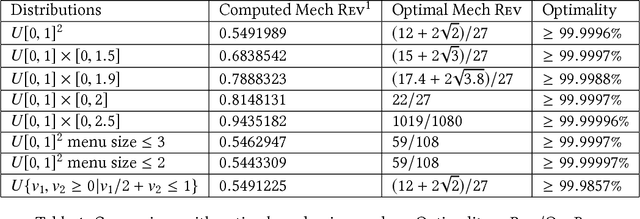
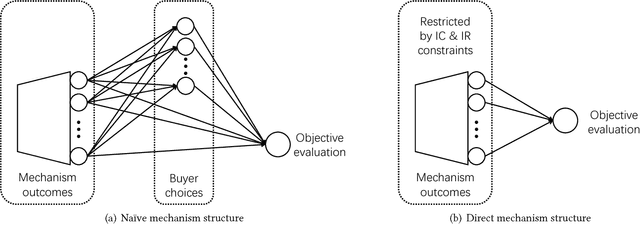
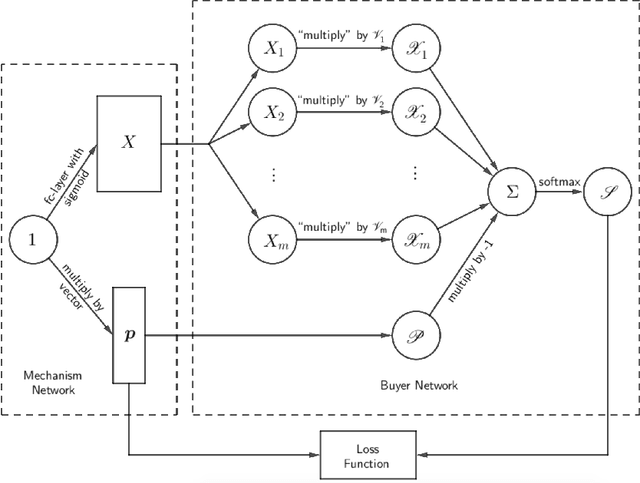
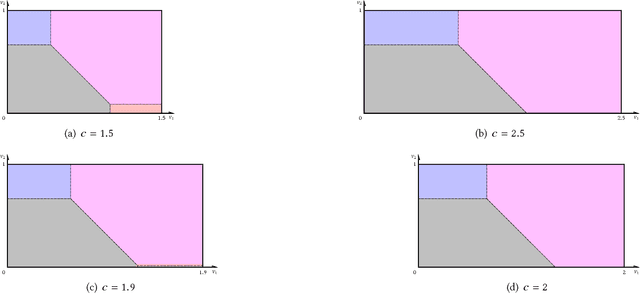
Using AI approaches to automatically design mechanisms has been a central research mission at the interface of AI and economics [Conitzer and Sandholm, 2002]. Previous approaches that a empt to design revenue optimal auctions for the multi-dimensional settings fall short in at least one of the three aspects: 1) representation --- search in a space that probably does not even contain the optimal mechanism; 2) exactness --- finding a mechanism that is either not truthful or far from optimal; 3) domain dependence --- need a different design for different environment settings. To resolve the three difficulties, in this paper, we put forward a uni ed neural network based framework that automatically learns to design revenue optimal mechanisms. Our framework consists of a mechanism network that takes an input distribution for training and outputs a mechanism, as well as a buyer network that takes a mechanism as input and output an action. Such a separation in design mitigates the difficulty to impose incentive compatibility constraints on the mechanism, by making it a rational choice of the buyer. As a result, our framework easily overcomes the previously mentioned difficulty in incorporating IC constraints and always returns exactly incentive compatible mechanisms. We then applied our framework to a number of multi-item revenue optimal design settings, for a few of which the theoretically optimal mechanisms are unknown. We then go on to theoretically prove that the mechanisms found by our framework are indeed optimal.
Optimal Vehicle Dispatching Schemes via Dynamic Pricing
Mar 01, 2018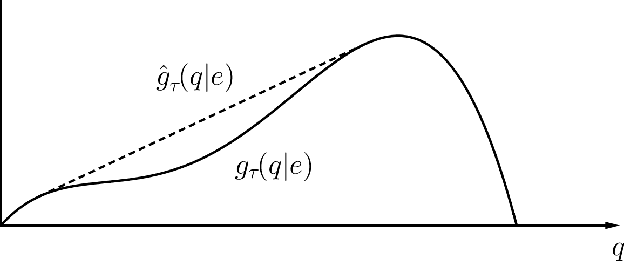

Over the past few years, ride-sharing has emerged as an effective way to relieve traffic congestion. A key problem for these platforms is to come up with a revenue-optimal (or GMV-optimal) pricing scheme and an induced vehicle dispatching policy that incorporate geographic and temporal information. In this paper, we aim to tackle this problem via an economic approach. Modeled naively, the underlying optimization problem may be non-convex and thus hard to compute. To this end, we use a so-called "ironing" technique to convert the problem into an equivalent convex optimization one via a clean Markov decision process (MDP) formulation, where the states are the driver distributions and the decision variables are the prices for each pair of locations. Our main finding is an efficient algorithm that computes the exact revenue-optimal (or GMV-optimal) randomized pricing schemes. We characterize the optimal solution of the MDP by a primal-dual analysis of a corresponding convex program. We also conduct empirical evaluations of our solution through real data of a major ride-sharing platform and show its advantages over fixed pricing schemes as well as several prevalent surge-based pricing schemes.
Reinforcement Mechanism Design for e-commerce
Feb 27, 2018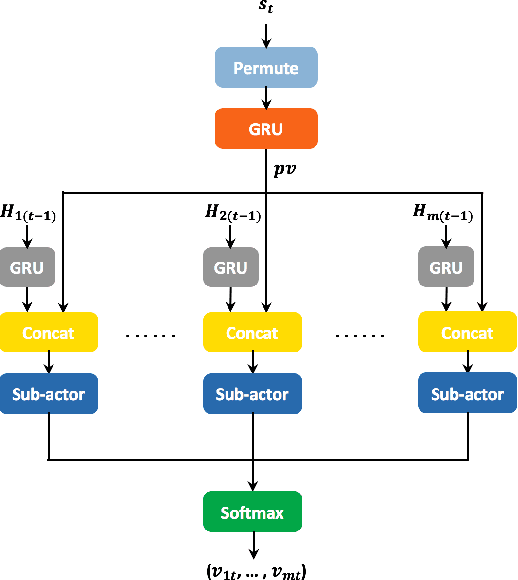
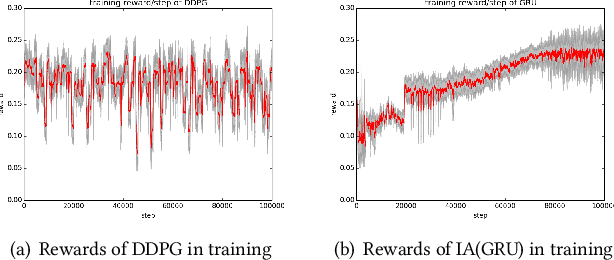
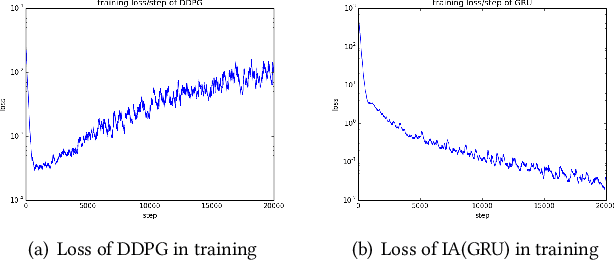
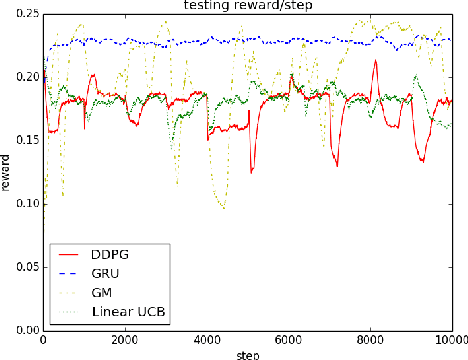
We study the problem of allocating impressions to sellers in e-commerce websites, such as Amazon, eBay or Taobao, aiming to maximize the total revenue generated by the platform. We employ a general framework of reinforcement mechanism design, which uses deep reinforcement learning to design efficient algorithms, taking the strategic behaviour of the sellers into account. Specifically, we model the impression allocation problem as a Markov decision process, where the states encode the history of impressions, prices, transactions and generated revenue and the actions are the possible impression allocations in each round. To tackle the problem of continuity and high-dimensionality of states and actions, we adopt the ideas of the DDPG algorithm to design an actor-critic policy gradient algorithm which takes advantage of the problem domain in order to achieve convergence and stability. We evaluate our proposed algorithm, coined IA(GRU), by comparing it against DDPG, as well as several natural heuristics, under different rationality models for the sellers - we assume that sellers follow well-known no-regret type strategies which may vary in their degree of sophistication. We find that IA(GRU) outperforms all algorithms in terms of the total revenue.