 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUser-in-the-loop Adaptive Intent Detection for Instructable Digital Assistant
Jan 16, 2020
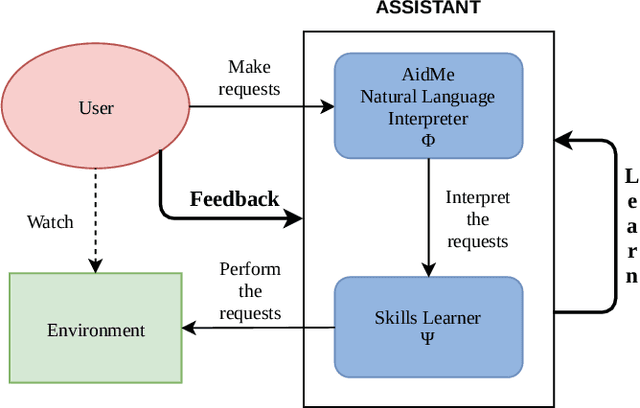
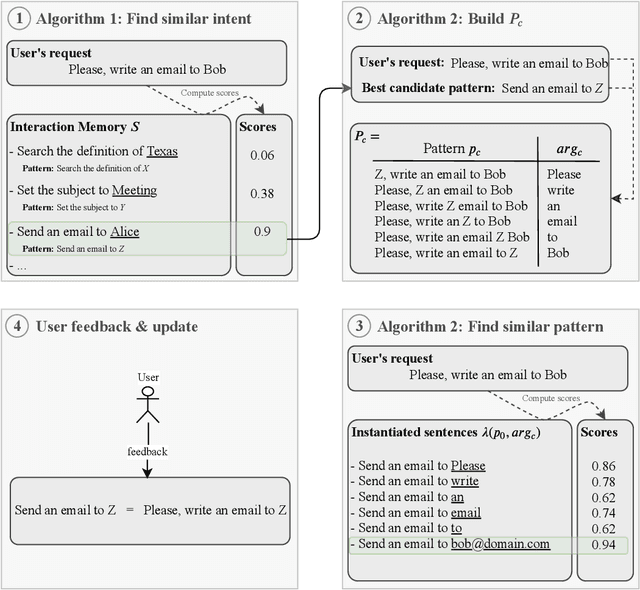

People are becoming increasingly comfortable using Digital Assistants (DAs) to interact with services or connected objects. However, for non-programming users, the available possibilities for customizing their DA are limited and do not include the possibility of teaching the assistant new tasks. To make the most of the potential of DAs, users should be able to customize assistants by instructing them through Natural Language (NL). To provide such functionalities, NL interpretation in traditional assistants should be improved: (1) The intent identification system should be able to recognize new forms of known intents, and to acquire new intents as they are expressed by the user. (2) In order to be adaptive to novel intents, the Natural Language Understanding module should be sample efficient, and should not rely on a pretrained model. Rather, the system should continuously collect the training data as it learns new intents from the user. In this work, we propose AidMe (Adaptive Intent Detection in Multi-Domain Environments), a user-in-the-loop adaptive intent detection framework that allows the assistant to adapt to its user by learning his intents as their interaction progresses. AidMe builds its repertoire of intents and collects data to train a model of semantic similarity evaluation that can discriminate between the learned intents and autonomously discover new forms of known intents. AidMe addresses two major issues - intent learning and user adaptation - for instructable digital assistants. We demonstrate the capabilities of AidMe as a standalone system by comparing it with a one-shot learning system and a pretrained NLU module through simulations of interactions with a user. We also show how AidMe can smoothly integrate to an existing instructable digital assistant.
* To be published as a conference paper in the proceedings of IUI'20
Language Grounding through Social Interactions and Curiosity-Driven Multi-Goal Learning
Nov 08, 2019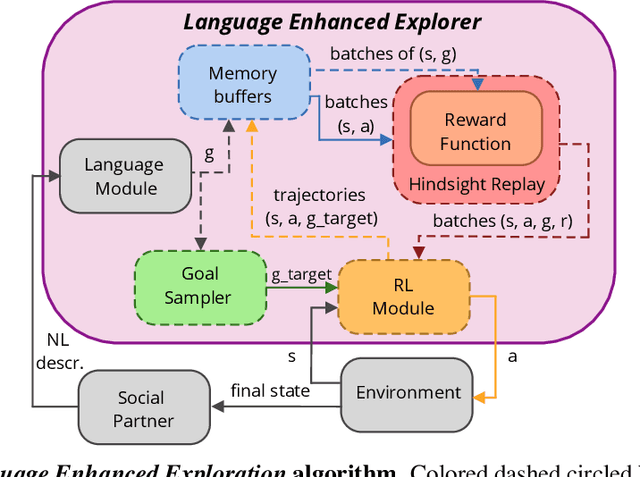
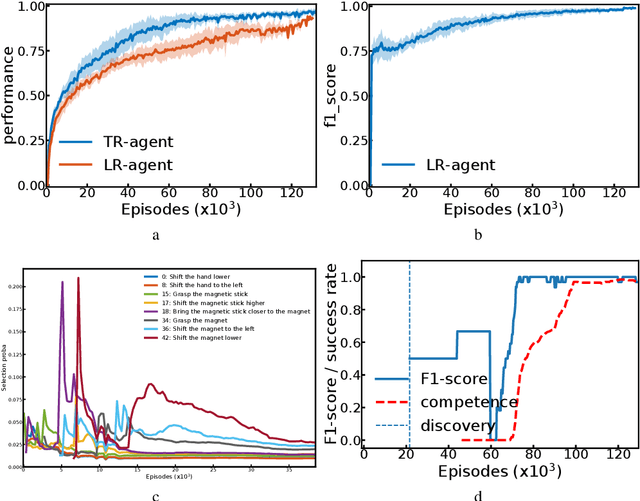
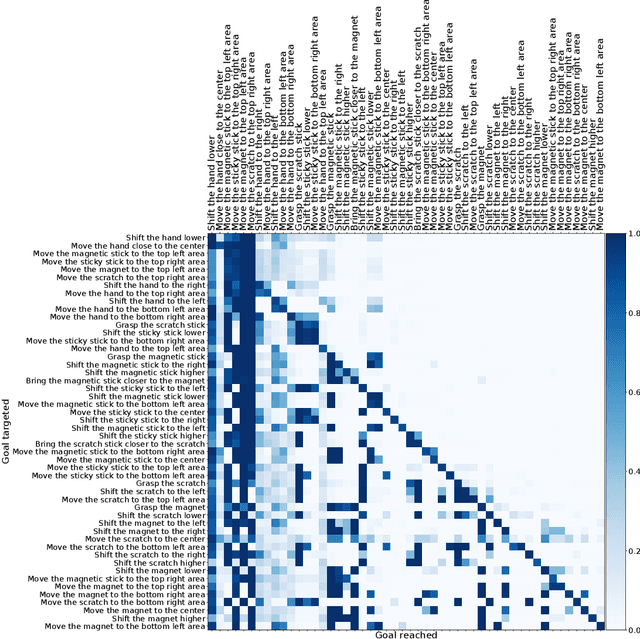
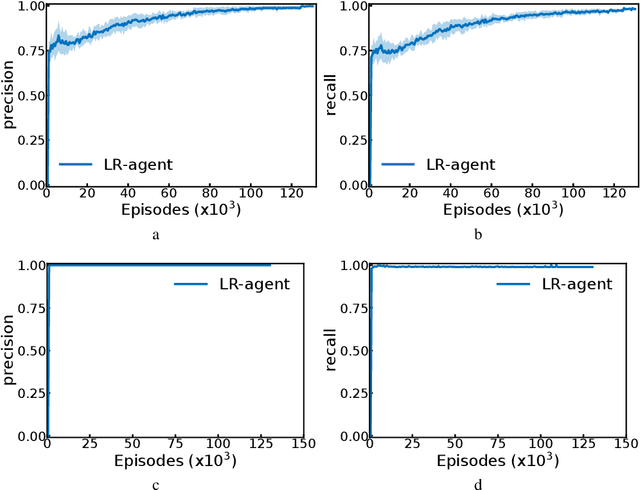
Autonomous reinforcement learning agents, like children, do not have access to predefined goals and reward functions. They must discover potential goals, learn their own reward functions and engage in their own learning trajectory. Children, however, benefit from exposure to language, helping to organize and mediate their thought. We propose LE2 (Language Enhanced Exploration), a learning algorithm leveraging intrinsic motivations and natural language (NL) interactions with a descriptive social partner (SP). Using NL descriptions from the SP, it can learn an NL-conditioned reward function to formulate goals for intrinsically motivated goal exploration and learn a goal-conditioned policy. By exploring, collecting descriptions from the SP and jointly learning the reward function and the policy, the agent grounds NL descriptions into real behavioral goals. From simple goals discovered early to more complex goals discovered by experimenting on simpler ones, our agent autonomously builds its own behavioral repertoire. This naturally occurring curriculum is supplemented by an active learning curriculum resulting from the agent's intrinsic motivations. Experiments are presented with a simulated robotic arm that interacts with several objects including tools.
Teacher algorithms for curriculum learning of Deep RL in continuously parameterized environments
Oct 16, 2019

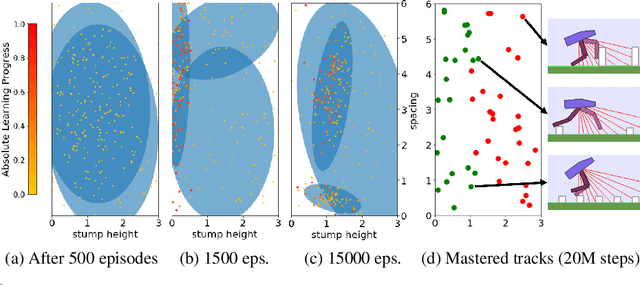
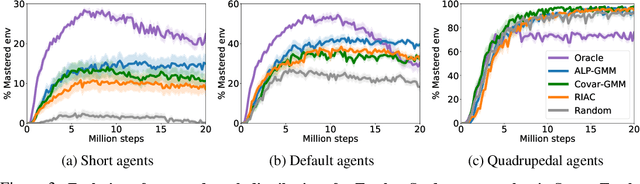
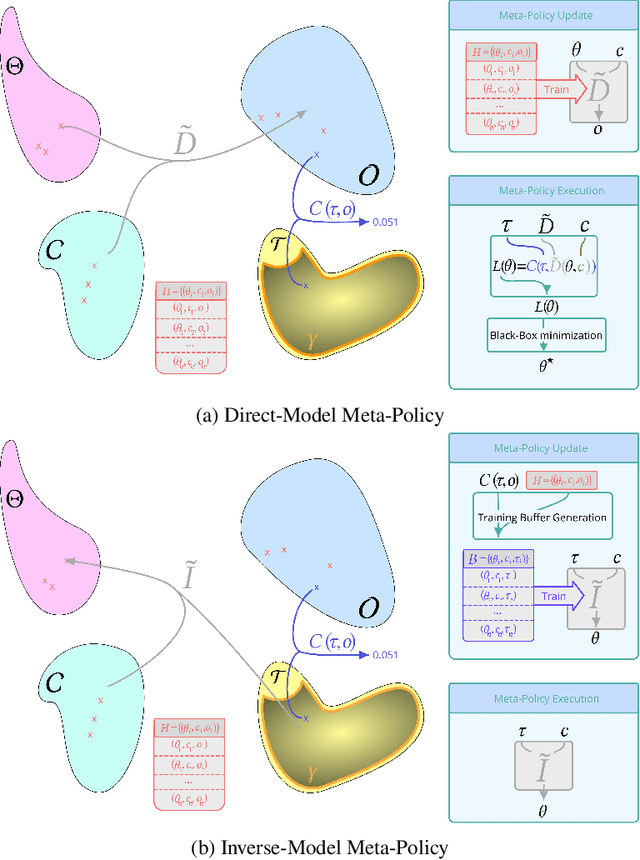
We consider the problem of how a teacher algorithm can enable an unknown Deep Reinforcement Learning (DRL) student to become good at a skill over a wide range of diverse environments. To do so, we study how a teacher algorithm can learn to generate a learning curriculum, whereby it sequentially samples parameters controlling a stochastic procedural generation of environments. Because it does not initially know the capacities of its student, a key challenge for the teacher is to discover which environments are easy, difficult or unlearnable, and in what order to propose them to maximize the efficiency of learning over the learnable ones. To achieve this, this problem is transformed into a surrogate continuous bandit problem where the teacher samples environments in order to maximize absolute learning progress of its student. We present a new algorithm modeling absolute learning progress with Gaussian mixture models (ALP-GMM). We also adapt existing algorithms and provide a complete study in the context of DRL. Using parameterized variants of the BipedalWalker environment, we study their efficiency to personalize a learning curriculum for different learners (embodiments), their robustness to the ratio of learnable/unlearnable environments, and their scalability to non-linear and high-dimensional parameter spaces. Videos and code are available at https://github.com/flowersteam/teachDeepRL.
Intrinsically Motivated Discovery of Diverse Patterns in Self-Organizing Systems
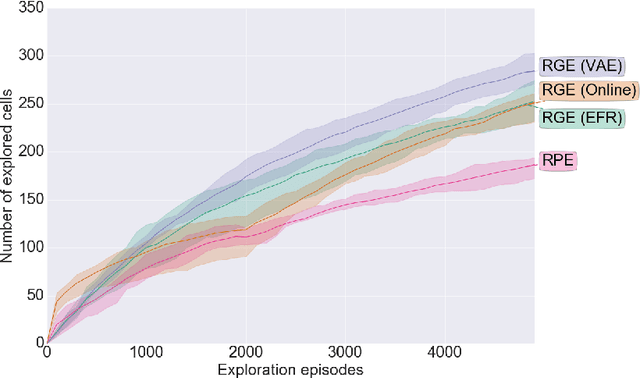
Sep 30, 2019In many complex dynamical systems, artificial or natural, one can observe self-organization of patterns emerging from local rules. Cellular automata, like the Game of Life (GOL), have been widely used as abstract models enabling the study of various aspects of self-organization and morphogenesis, such as the emergence of spatially localized patterns. However, findings of self-organized patterns in such models have so far relied on manual tuning of parameters and initial states, and on the human eye to identify interesting patterns. In this paper, we formulate the problem of automated discovery of diverse self-organized patterns in such high-dimensional complex dynamical systems, as well as a framework for experimentation and evaluation. Using a continuous GOL as a testbed, we show that recent intrinsically-motivated machine learning algorithms (POP-IMGEPs), initially developed for learning of inverse models in robotics, can be transposed and used in this novel application area. These algorithms combine intrinsically-motivated goal exploration and unsupervised learning of goal space representations. Goal space representations describe the interesting features of patterns for which diverse variations should be discovered. In particular, we compare various approaches to define and learn goal space representations from the perspective of discovering diverse spatially localized patterns. Moreover, we introduce an extension of a state-of-the-art POP-IMGEP algorithm which incrementally learns a goal representation using a deep auto-encoder, and the use of CPPN primitives for generating initialization parameters. We show that it is more efficient than several baselines and equally efficient as a system pre-trained on a hand-made database of patterns identified by human experts.
Autonomous Goal Exploration using Learned Goal Spaces for Visuomotor Skill Acquisition in Robots
Jun 10, 2019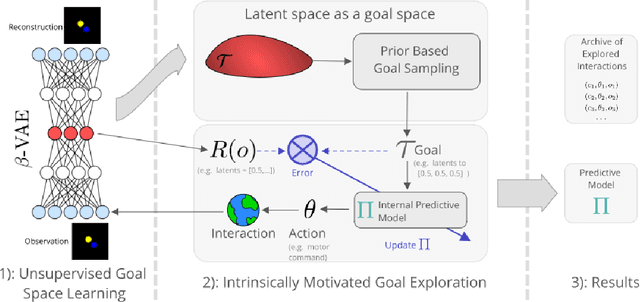

The automatic and efficient discovery of skills, without supervision, for long-living autonomous agents, remains a challenge of Artificial Intelligence. Intrinsically Motivated Goal Exploration Processes give learning agents a human-inspired mechanism to sequentially select goals to achieve. This approach gives a new perspective on the lifelong learning problem, with promising results on both simulated and real-world experiments. Until recently, those algorithms were restricted to domains with experimenter-knowledge, since the Goal Space used by the agents was built on engineered feature extractors. The recent advances of deep representation learning, enables new ways of designing those feature extractors, using directly the agent experience. Recent work has shown the potential of those methods on simple yet challenging simulated domains. In this paper, we present recent results showing the applicability of those principles on a real-world robotic setup, where a 6-joint robotic arm learns to manipulate a ball inside an arena, by choosing goals in a space learned from its past experience.
A Hitchhiker's Guide to Statistical Comparisons of Reinforcement Learning Algorithms
Apr 15, 2019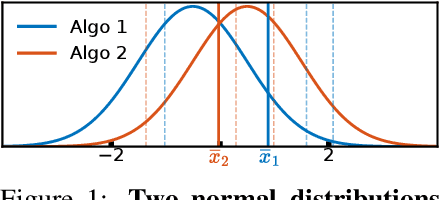
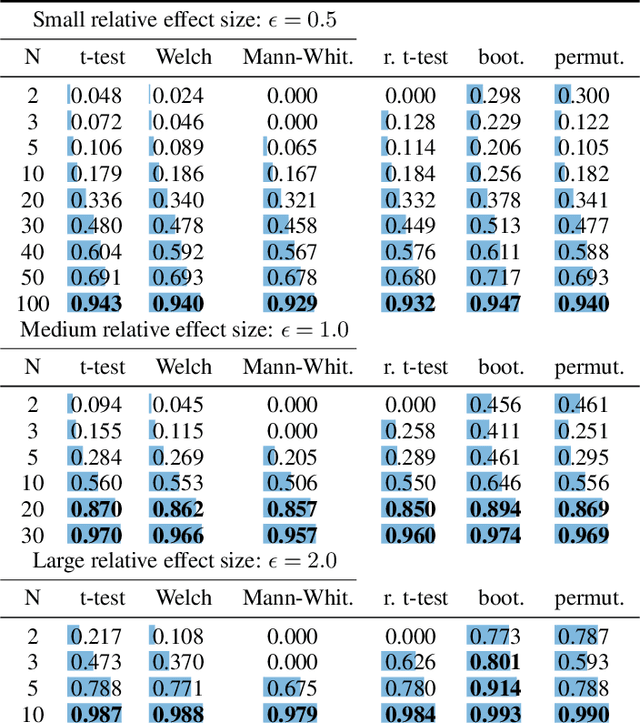
Consistently checking the statistical significance of experimental results is the first mandatory step towards reproducible science. This paper presents a hitchhiker's guide to rigorous comparisons of reinforcement learning algorithms. After introducing the concepts of statistical testing, we review the relevant statistical tests and compare them empirically in terms of false positive rate and statistical power as a function of the sample size (number of seeds) and effect size. We further investigate the robustness of these tests to violations of the most common hypotheses (normal distributions, same distributions, equal variances). Beside simulations, we compare empirical distributions obtained by running Soft-Actor Critic and Twin-Delayed Deep Deterministic Policy Gradient on Half-Cheetah. We conclude by providing guidelines and code to perform rigorous comparisons of RL algorithm performances.
Computational and Robotic Models of Early Language Development: A Review
Mar 25, 2019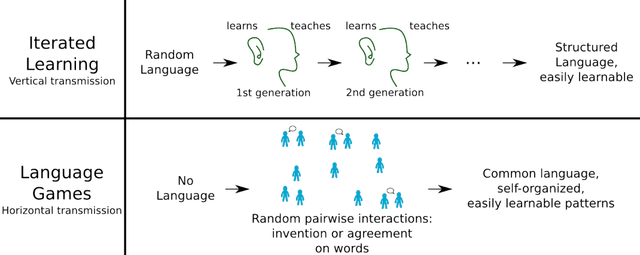
We review computational and robotics models of early language learning and development. We first explain why and how these models are used to understand better how children learn language. We argue that they provide concrete theories of language learning as a complex dynamic system, complementing traditional methods in psychology and linguistics. We review different modeling formalisms, grounded in techniques from machine learning and artificial intelligence such as Bayesian and neural network approaches. We then discuss their role in understanding several key mechanisms of language development: cross-situational statistical learning, embodiment, situated social interaction, intrinsically motivated learning, and cultural evolution. We conclude by discussing future challenges for research, including modeling of large-scale empirical data about language acquisition in real-world environments. Keywords: Early language learning, Computational and robotic models, machine learning, development, embodiment, social interaction, intrinsic motivation, self-organization, dynamical systems, complexity.
Curiosity Driven Exploration of Learned Disentangled Goal Spaces
Nov 04, 2018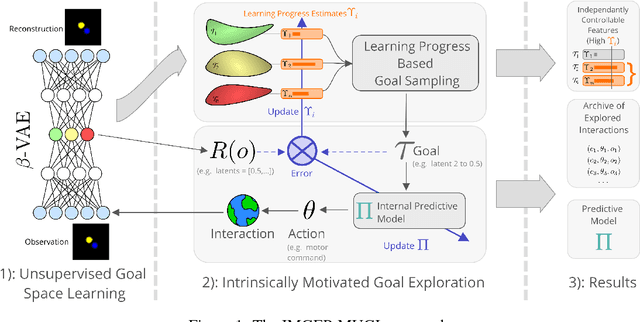
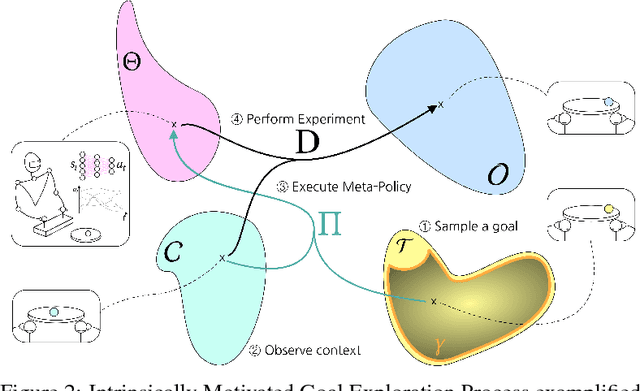
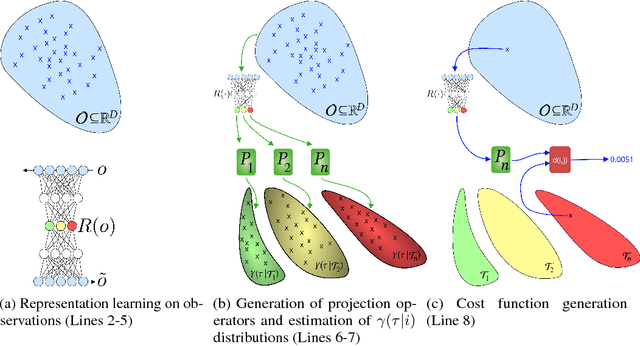

Intrinsically motivated goal exploration processes enable agents to autonomously sample goals to explore efficiently complex environments with high-dimensional continuous actions. They have been applied successfully to real world robots to discover repertoires of policies producing a wide diversity of effects. Often these algorithms relied on engineered goal spaces but it was recently shown that one can use deep representation learning algorithms to learn an adequate goal space in simple environments. However, in the case of more complex environments containing multiple objects or distractors, an efficient exploration requires that the structure of the goal space reflects the one of the environment. In this paper we show that using a disentangled goal space leads to better exploration performances than an entangled goal space. We further show that when the representation is disentangled, one can leverage it by sampling goals that maximize learning progress in a modular manner. Finally, we show that the measure of learning progress, used to drive curiosity-driven exploration, can be used simultaneously to discover abstract independently controllable features of the environment.
* The code used in the experiments is available at https://github.com/flowersteam/Curiosity_Driven_Goal_Exploration
CURIOUS: Intrinsically Motivated Modular Multi-Goal Reinforcement Learning
Oct 24, 2018

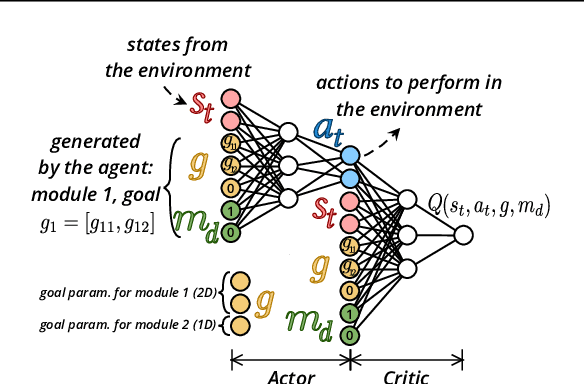
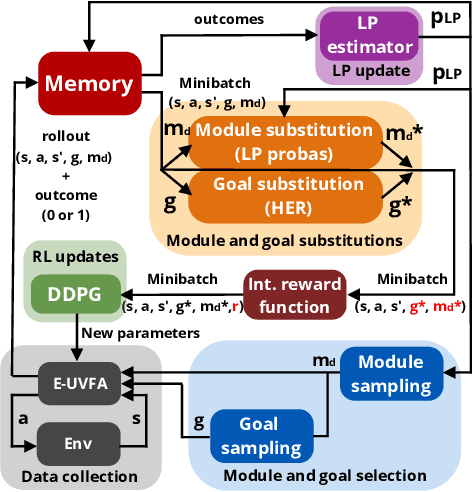
In open-ended and changing environments, agents face a wide range of potential tasks that may or may not come with associated reward functions. Such autonomous learning agents must be able to generate their own tasks through a process of intrinsically motivated exploration, some of which might prove easy, others impossible. For this reason, they should be able to actively select which task to practice at any given moment, to maximize their overall mastery on the set of learnable tasks. This paper proposes CURIOUS, an extension of Universal Value Function Approximators that enables intrinsically motivated agents to learn to achieve both multiple tasks and multiple goals within a unique policy, leveraging hindsight learning. Agents focus on achievable tasks first, using an automated curriculum learning mechanism that biases their attention towards tasks maximizing the absolute learning progress. This mechanism provides robustness to catastrophic forgetting (by refocusing on tasks where performance decreases) and distracting tasks (by avoiding tasks with no absolute learning progress). Furthermore, we show that having two levels of parameterization (tasks and goals within tasks) enables more efficient learning of skills in an environment with a modular physical structure (e.g. multiple objects) as compared to flat, goal-parameterized RL with hindsight experience replay.
Unsupervised Learning of Goal Spaces for Intrinsically Motivated Goal Exploration
Oct 09, 2018
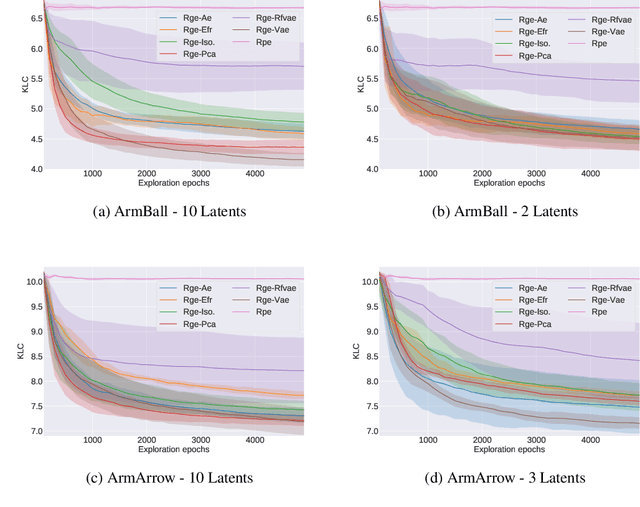
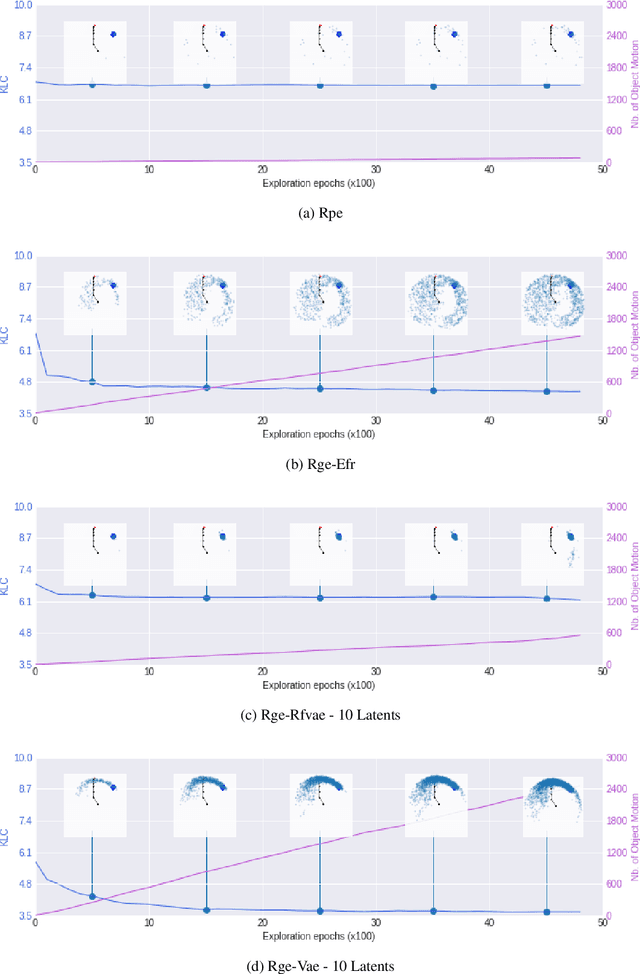
Intrinsically motivated goal exploration algorithms enable machines to discover repertoires of policies that produce a diversity of effects in complex environments. These exploration algorithms have been shown to allow real world robots to acquire skills such as tool use in high-dimensional continuous state and action spaces. However, they have so far assumed that self-generated goals are sampled in a specifically engineered feature space, limiting their autonomy. In this work, we propose to use deep representation learning algorithms to learn an adequate goal space. This is a developmental 2-stage approach: first, in a perceptual learning stage, deep learning algorithms use passive raw sensor observations of world changes to learn a corresponding latent space; then goal exploration happens in a second stage by sampling goals in this latent space. We present experiments where a simulated robot arm interacts with an object, and we show that exploration algorithms using such learned representations can match the performance obtained using engineered representations.