 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransflower: probabilistic autoregressive dance generation with multimodal attention
Jun 25, 2021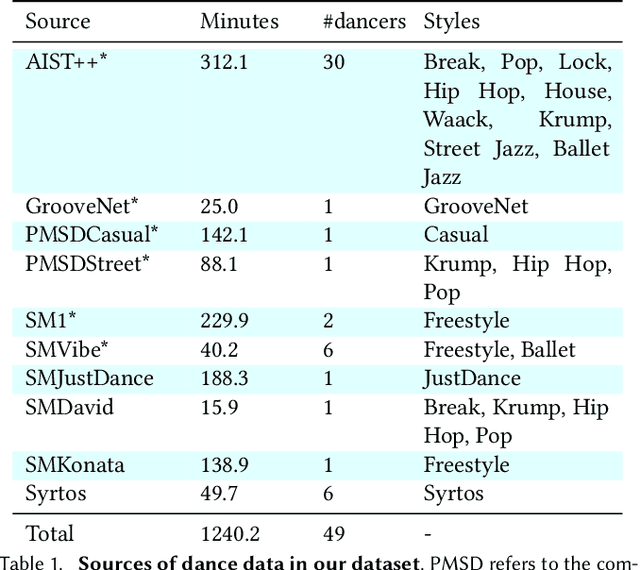
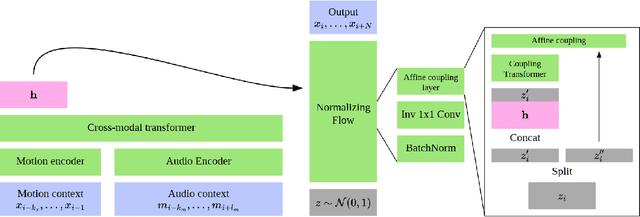
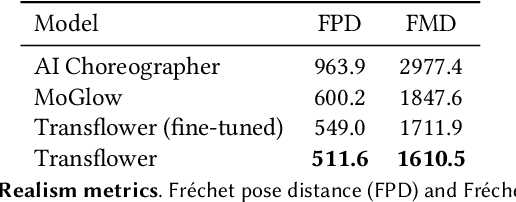

Dance requires skillful composition of complex movements that follow rhythmic, tonal and timbral features of music. Formally, generating dance conditioned on a piece of music can be expressed as a problem of modelling a high-dimensional continuous motion signal, conditioned on an audio signal. In this work we make two contributions to tackle this problem. First, we present a novel probabilistic autoregressive architecture that models the distribution over future poses with a normalizing flow conditioned on previous poses as well as music context, using a multimodal transformer encoder. Second, we introduce the currently largest 3D dance-motion dataset, obtained with a variety of motion-capture technologies, and including both professional and casual dancers. Using this dataset, we compare our new model against two baselines, via objective metrics and a user study, and show that both the ability to model a probability distribution, as well as being able to attend over a large motion and music context are necessary to produce interesting, diverse, and realistic dance that matches the music.
Grounding Spatio-Temporal Language with Transformers
Jun 16, 2021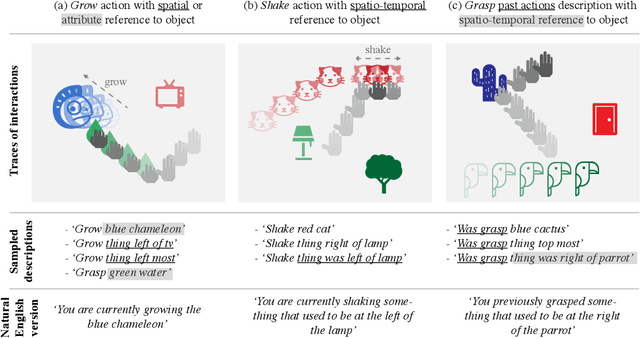
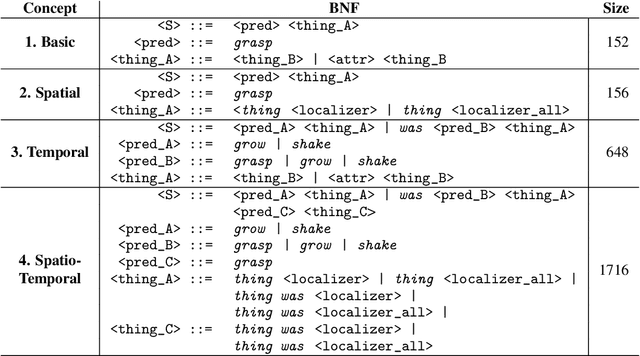
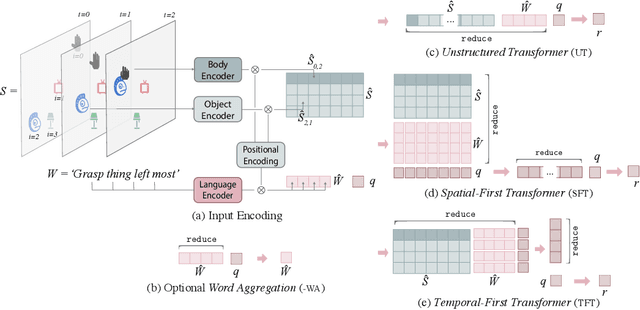
Language is an interface to the outside world. In order for embodied agents to use it, language must be grounded in other, sensorimotor modalities. While there is an extended literature studying how machines can learn grounded language, the topic of how to learn spatio-temporal linguistic concepts is still largely uncharted. To make progress in this direction, we here introduce a novel spatio-temporal language grounding task where the goal is to learn the meaning of spatio-temporal descriptions of behavioral traces of an embodied agent. This is achieved by training a truth function that predicts if a description matches a given history of observations. The descriptions involve time-extended predicates in past and present tense as well as spatio-temporal references to objects in the scene. To study the role of architectural biases in this task, we train several models including multimodal Transformer architectures; the latter implement different attention computations between words and objects across space and time. We test models on two classes of generalization: 1) generalization to randomly held-out sentences; 2) generalization to grammar primitives. We observe that maintaining object identity in the attention computation of our Transformers is instrumental to achieving good performance on generalization overall, and that summarizing object traces in a single token has little influence on performance. We then discuss how this opens new perspectives for language-guided autonomous embodied agents. We also release our code under open-source license as well as pretrained models and datasets to encourage the wider community to build upon and extend our work in the future.
Towards Teachable Autonomous Agents
May 25, 2021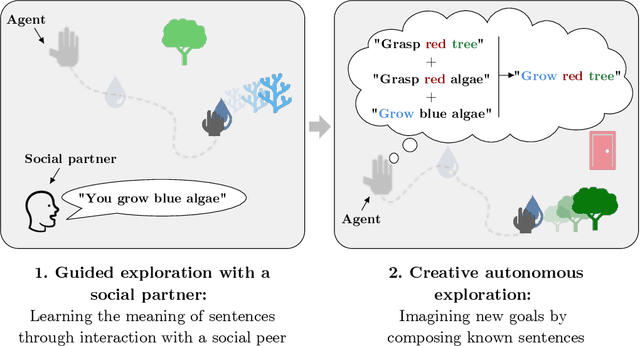
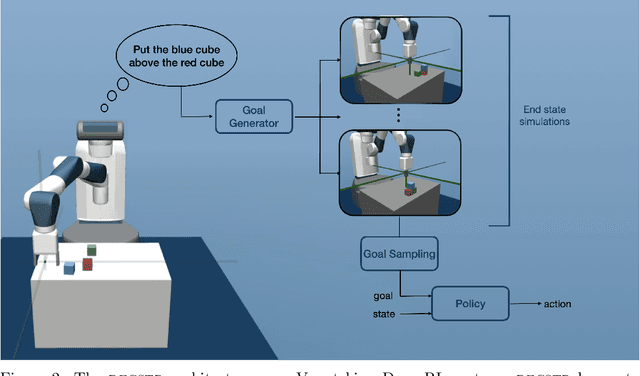
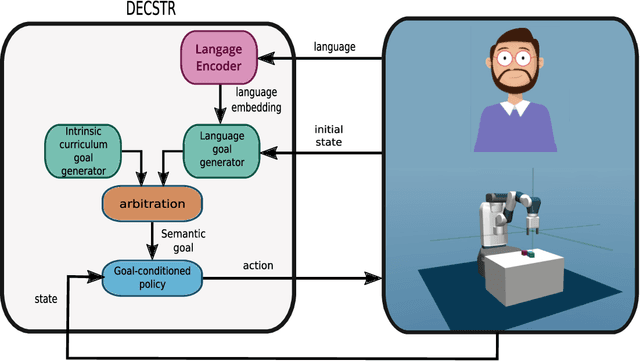
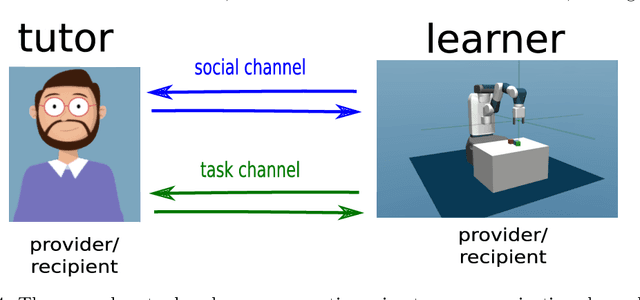
Autonomous discovery and direct instruction are two extreme sources of learning in children, but educational sciences have shown that intermediate approaches such as assisted discovery or guided play resulted in better acquisition of skills. When turning to Artificial Intelligence, the above dichotomy is translated into the distinction between autonomous agents which learn in isolation and interactive learning agents which can be taught by social partners but generally lack autonomy. In between should stand teachable autonomous agents: agents learning from both internal and teaching signals to benefit from the higher efficiency of assisted discovery. Such agents could learn on their own in the real world, but non-expert users could drive their learning behavior towards their expectations. More fundamentally, combining both capabilities might also be a key step towards general intelligence. In this paper we elucidate obstacles along this research line. First, we build on a seminal work of Bruner to extract relevant features of the assisted discovery processes. Second, we describe current research on autotelic agents, i.e. agents equipped with forms of intrinsic motivations that enable them to represent, self-generate and pursue their own goals. We argue that autotelic capabilities are paving the way towards teachable and autonomous agents. Finally, we adopt a social learning perspective on tutoring interactions and we highlight some components that are currently missing to autotelic agents before they can be taught by ordinary people using natural pedagogy, and we provide a list of specific research questions that emerge from this perspective.
SocialAI 0.1: Towards a Benchmark to Stimulate Research on Socio-Cognitive Abilities in Deep Reinforcement Learning Agents
Apr 27, 2021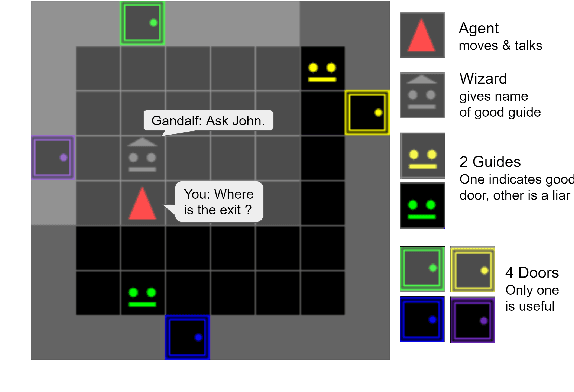

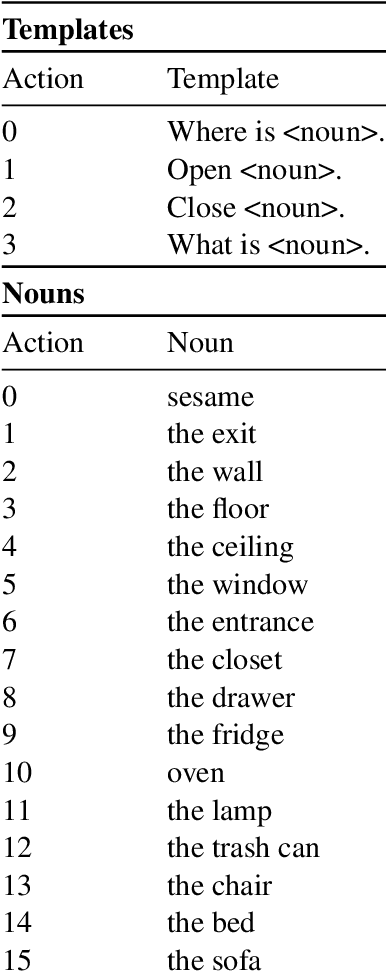
Building embodied autonomous agents capable of participating in social interactions with humans is one of the main challenges in AI. This problem motivated many research directions on embodied language use. Current approaches focus on language as a communication tool in very simplified and non diverse social situations: the "naturalness" of language is reduced to the concept of high vocabulary size and variability. In this paper, we argue that aiming towards human-level AI requires a broader set of key social skills: 1) language use in complex and variable social contexts; 2) beyond language, complex embodied communication in multimodal settings within constantly evolving social worlds. In this work we explain how concepts from cognitive sciences could help AI to draw a roadmap towards human-like intelligence, with a focus on its social dimensions. We then study the limits of a recent SOTA Deep RL approach when tested on a first grid-world environment from the upcoming SocialAI, a benchmark to assess the social skills of Deep RL agents. Videos and code are available at https://sites.google.com/view/socialai01 .
TeachMyAgent: a Benchmark for Automatic Curriculum Learning in Deep RL
Mar 17, 2021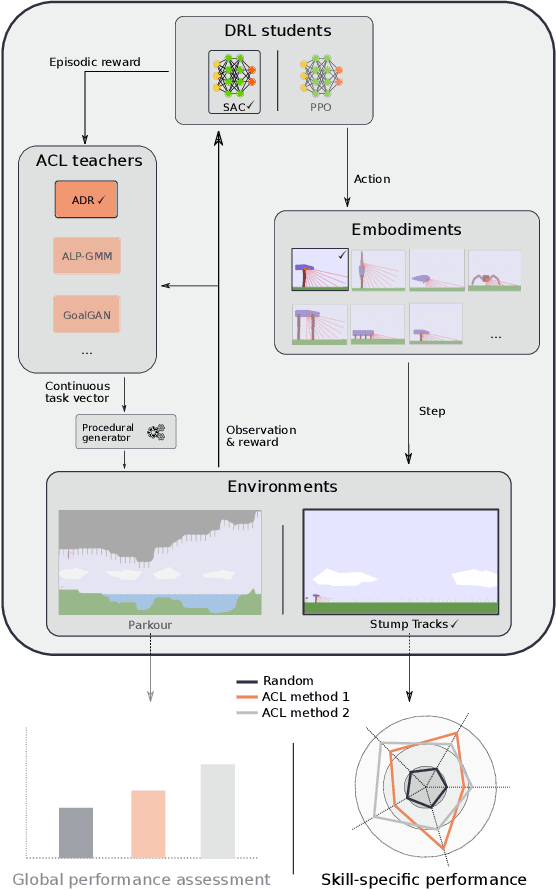

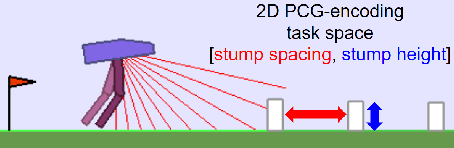
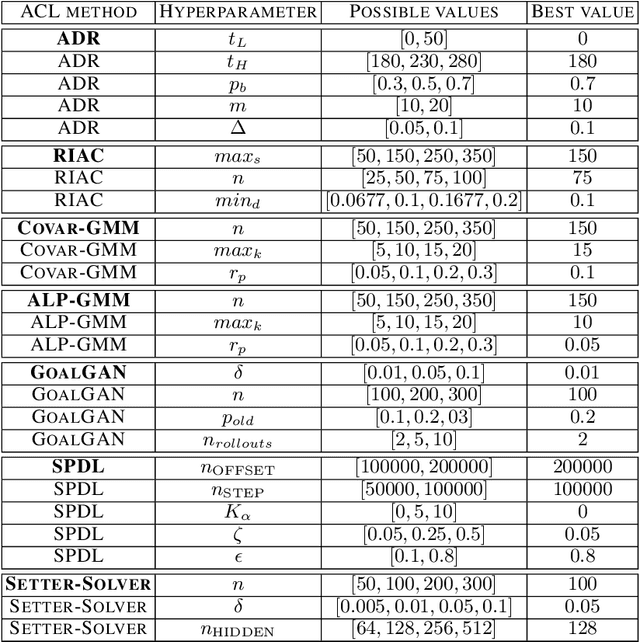
Training autonomous agents able to generalize to multiple tasks is a key target of Deep Reinforcement Learning (DRL) research. In parallel to improving DRL algorithms themselves, Automatic Curriculum Learning (ACL) study how teacher algorithms can train DRL agents more efficiently by adapting task selection to their evolving abilities. While multiple standard benchmarks exist to compare DRL agents, there is currently no such thing for ACL algorithms. Thus, comparing existing approaches is difficult, as too many experimental parameters differ from paper to paper. In this work, we identify several key challenges faced by ACL algorithms. Based on these, we present TeachMyAgent (TA), a benchmark of current ACL algorithms leveraging procedural task generation. It includes 1) challenge-specific unit-tests using variants of a procedural Box2D bipedal walker environment, and 2) a new procedural Parkour environment combining most ACL challenges, making it ideal for global performance assessment. We then use TeachMyAgent to conduct a comparative study of representative existing approaches, showcasing the competitiveness of some ACL algorithms that do not use expert knowledge. We also show that the Parkour environment remains an open problem. We open-source our environments, all studied ACL algorithms (collected from open-source code or re-implemented), and DRL students in a Python package available at https://github.com/flowersteam/TeachMyAgent.
Intelligent behavior depends on the ecological niche: Scaling up AI to human-like intelligence in socio-cultural environments
Mar 11, 2021This paper outlines a perspective on the future of AI, discussing directions for machines models of human-like intelligence. We explain how developmental and evolutionary theories of human cognition should further inform artificial intelligence. We emphasize the role of ecological niches in sculpting intelligent behavior, and in particular that human intelligence was fundamentally shaped to adapt to a constantly changing socio-cultural environment. We argue that a major limit of current work in AI is that it is missing this perspective, both theoretically and experimentally. Finally, we discuss the promising approach of developmental artificial intelligence, modeling infant development through multi-scale interaction between intrinsically motivated learning, embodiment and a fastly changing socio-cultural environment. This paper takes the form of an interview of Pierre-Yves Oudeyer by Mandred Eppe, organized within the context of a KI - K{\"{u}}nstliche Intelligenz special issue in developmental robotics.
* Keywords: developmental AI, general artificial intelligence, human-like AI, embodiment, cultural evolution, language, socio-cultural skills
Intrinsically Motivated Goal-Conditioned Reinforcement Learning: a Short Survey
Dec 17, 2020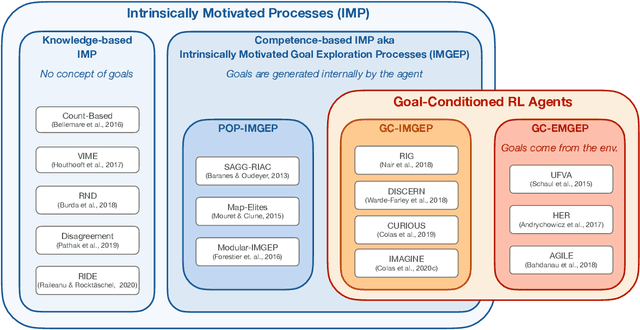
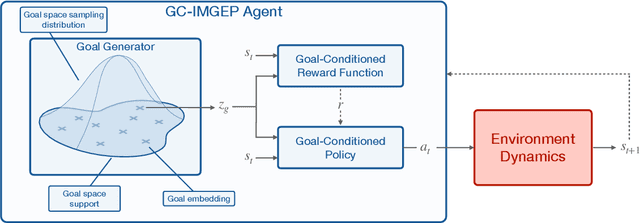
Building autonomous machines that can explore open-ended environments, discover possible interactions and autonomously build repertoires of skills is a general objective of artificial intelligence. Developmental approaches argue that this can only be achieved by autonomous and intrinsically motivated learning agents that can generate, select and learn to solve their own problems. In recent years, we have seen a convergence of developmental approaches, and developmental robotics in particular, with deep reinforcement learning (RL) methods, forming the new domain of developmental machine learning. Within this new domain, we review here a set of methods where deep RL algorithms are trained to tackle the developmental robotics problem of the autonomous acquisition of open-ended repertoires of skills. Intrinsically motivated goal-conditioned RL algorithms train agents to learn to represent, generate and pursue their own goals. The self-generation of goals requires the learning of compact goal encodings as well as their associated goal-achievement functions, which results in new challenges compared to traditional RL algorithms designed to tackle pre-defined sets of goals using external reward signals. This paper proposes a typology of these methods at the intersection of deep RL and developmental approaches, surveys recent approaches and discusses future avenues.
Meta Automatic Curriculum Learning
Nov 16, 2020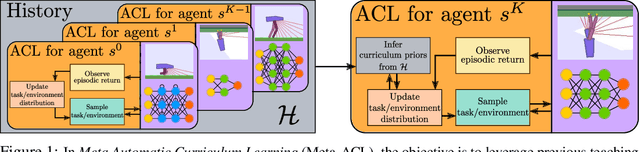

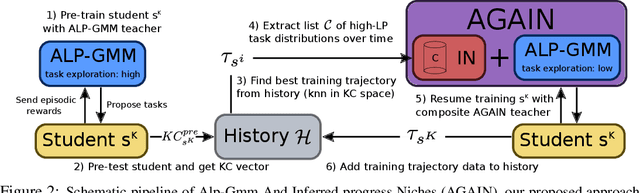
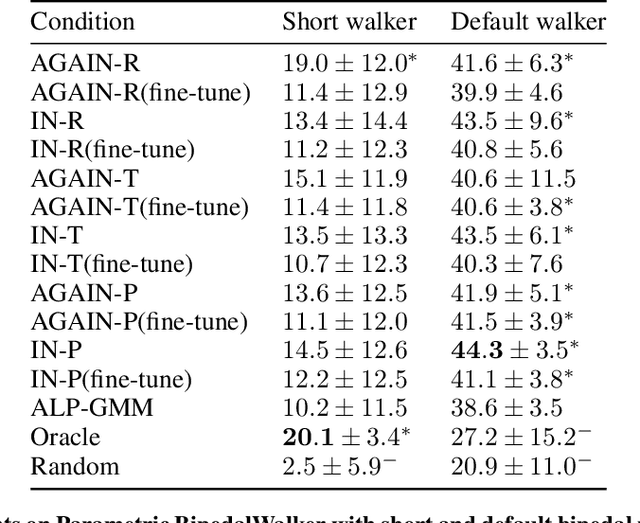
A major challenge in the Deep RL (DRL) community is to train agents able to generalize their control policy over situations never seen in training. Training on diverse tasks has been identified as a key ingredient for good generalization, which pushed researchers towards using rich procedural task generation systems controlled through complex continuous parameter spaces. In such complex task spaces, it is essential to rely on some form of Automatic Curriculum Learning (ACL) to adapt the task sampling distribution to a given learning agent, instead of randomly sampling tasks, as many could end up being either trivial or unfeasible. Since it is hard to get prior knowledge on such task spaces, many ACL algorithms explore the task space to detect progress niches over time, a costly tabula-rasa process that needs to be performed for each new learning agents, although they might have similarities in their capabilities profiles. To address this limitation, we introduce the concept of Meta-ACL, and formalize it in the context of black-box RL learners, i.e. algorithms seeking to generalize curriculum generation to an (unknown) distribution of learners. In this work, we present AGAIN, a first instantiation of Meta-ACL, and showcase its benefits for curriculum generation over classical ACL in multiple simulated environments including procedurally generated parkour environments with learners of varying morphologies. Videos and code are available at https://sites.google.com/view/meta-acl .
EpidemiOptim: A Toolbox for the Optimization of Control Policies in Epidemiological Models
Oct 09, 2020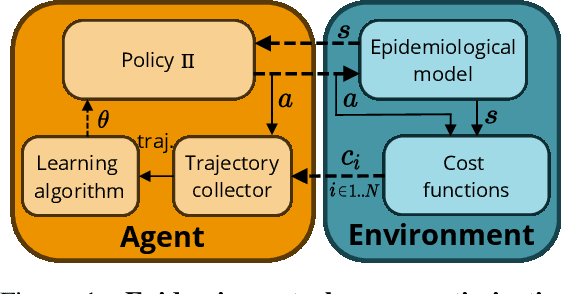
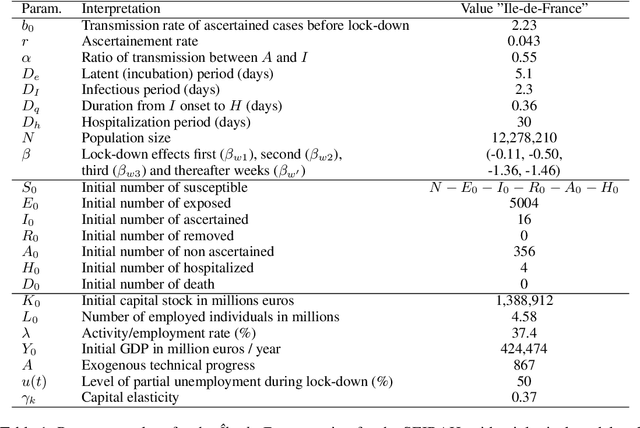
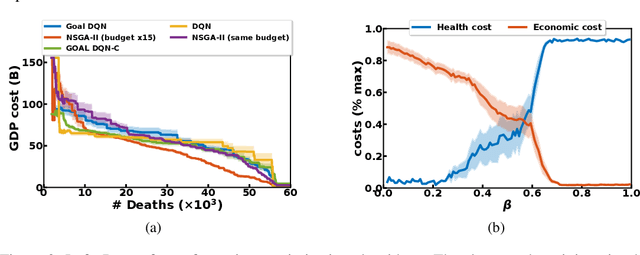

Epidemiologists model the dynamics of epidemics in order to propose control strategies based on pharmaceutical and non-pharmaceutical interventions (contact limitation, lock down, vaccination, etc). Hand-designing such strategies is not trivial because of the number of possible interventions and the difficulty to predict long-term effects. This task can be cast as an optimization problem where state-of-the-art machine learning algorithms such as deep reinforcement learning, might bring significant value. However, the specificity of each domain -- epidemic modelling or solving optimization problem -- requires strong collaborations between researchers from different fields of expertise. This is why we introduce EpidemiOptim, a Python toolbox that facilitates collaborations between researchers in epidemiology and optimization. EpidemiOptim turns epidemiological models and cost functions into optimization problems via a standard interface commonly used by optimization practitioners (OpenAI Gym). Reinforcement learning algorithms based on Q-Learning with deep neural networks (DQN) and evolutionary algorithms (NSGA-II) are already implemented. We illustrate the use of EpidemiOptim to find optimal policies for dynamical on-off lock-down control under the optimization of death toll and economic recess using a Susceptible-Exposed-Infectious-Removed (SEIR) model for COVID-19. Using EpidemiOptim and its interactive visualization platform in Jupyter notebooks, epidemiologists, optimization practitioners and others (e.g. economists) can easily compare epidemiological models, costs functions and optimization algorithms to address important choices to be made by health decision-makers.
GRIMGEP: Learning Progress for Robust Goal Sampling in Visual Deep Reinforcement Learning
Aug 10, 2020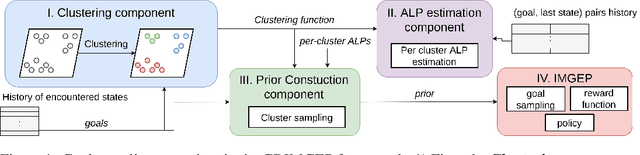


Autonomous agents using novelty based goal exploration are often efficient in environments that require exploration. However, they get attracted to various forms of distracting unlearnable regions. To solve this problem, absolute learning progress (ALP) has been used in reinforcement learning agents with predefined goal features and access to expert knowledge. This work extends those concepts to unsupervised image-based goal exploration. We present the GRIMGEP framework: it provides a learned robust goal sampling prior that can be used on top of current state-of-the-art novelty seeking goal exploration approaches, enabling them to ignore noisy distracting regions while searching for novelty in the learnable regions. It clusters the goal space and estimates ALP for each cluster. These ALP estimates can then be used to detect the distracting regions, and build a prior that enables further goal sampling mechanisms to ignore them. We construct an image based environment with distractors, on which we show that wrapping current state-of-the-art goal exploration algorithms with our framework allows them to concentrate on interesting regions of the environment and drastically improve performances. The source code is available at https://sites.google.com/view/grimgep.