 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Learning-Based Kinematic Reconstruction for DUNE
Dec 14, 2020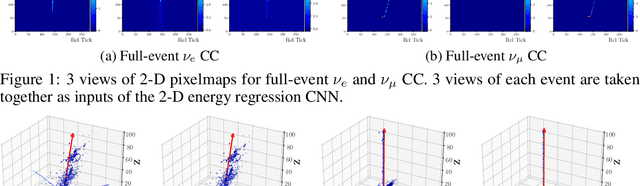
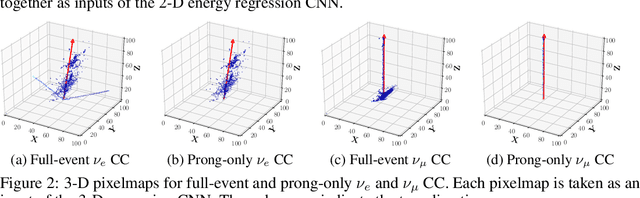
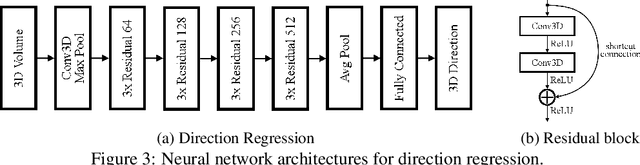
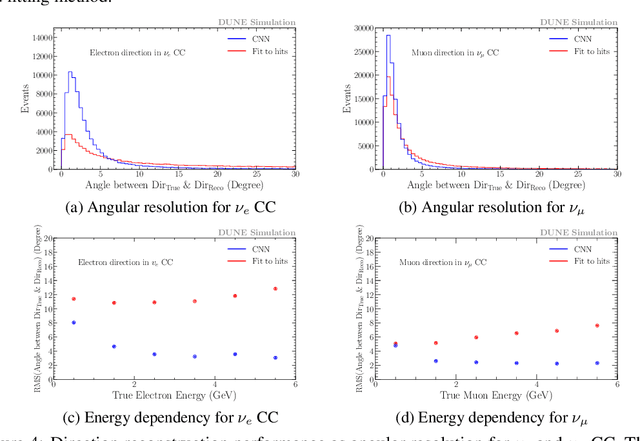
In the framework of three-active-neutrino mixing, the charge parity phase, the neutrino mass ordering, and the octant of $\theta_{23}$ remain unknown. The Deep Underground Neutrino Experiment (DUNE) is a next-generation long-baseline neutrino oscillation experiment, which aims to address these questions by measuring the oscillation patterns of $\nu_\mu/\nu_e$ and $\bar\nu_\mu/\bar\nu_e$ over a range of energies spanning the first and second oscillation maxima. DUNE far detector modules are based on liquid argon TPC (LArTPC) technology. A LArTPC offers excellent spatial resolution, high neutrino detection efficiency, and superb background rejection, while reconstruction in LArTPC is challenging. Deep learning methods, in particular, Convolutional Neural Networks (CNNs), have demonstrated success in classification problems such as particle identification in DUNE and other neutrino experiments. However, reconstruction of neutrino energy and final state particle momenta with deep learning methods is yet to be developed for a full AI-based reconstruction chain. To precisely reconstruct these kinematic characteristics of detected interactions at DUNE, we have developed and will present two CNN-based methods, 2-D and 3-D, for the reconstruction of final state particle direction and energy, as well as neutrino energy. Combining particle masses with the kinetic energy and the direction reconstructed by our work, the four-momentum of final state particles can be obtained. Our models show considerable improvements compared to the traditional methods for both scenarios.
Deep machine learning-assisted multiphoton microscopy to reduce light exposure and expedite imaging
Nov 10, 2020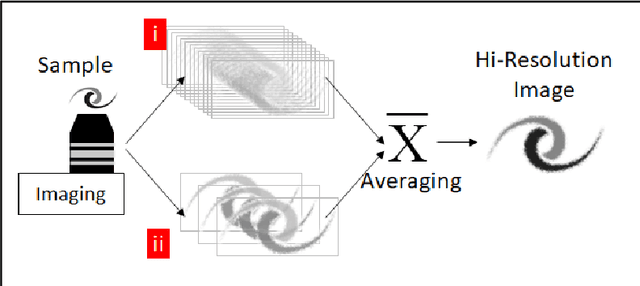
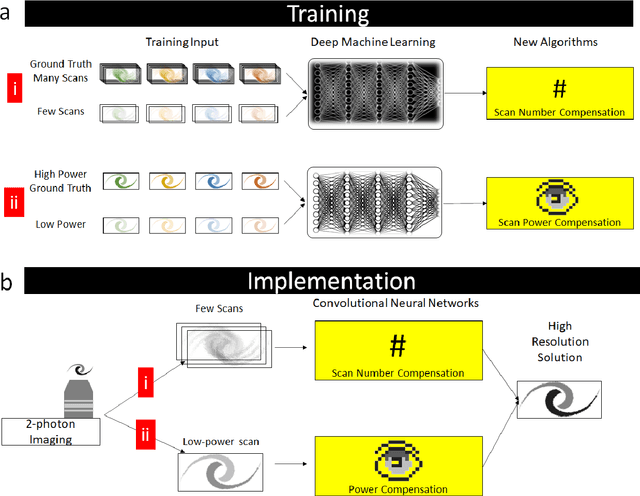
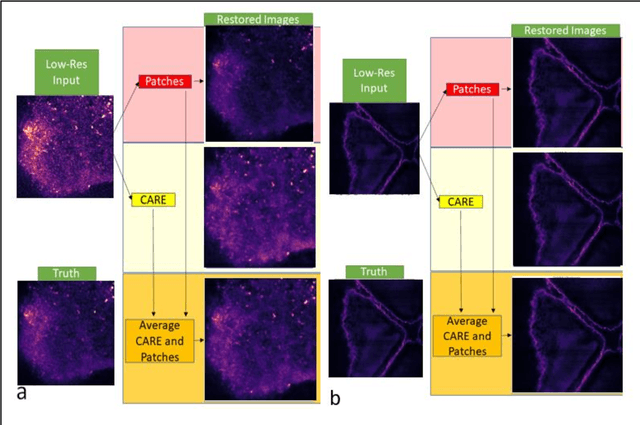
Two-photon excitation fluorescence (2PEF) allows imaging of tissue up to about one millimeter in thickness. Typically, reducing fluorescence excitation exposure reduces the quality of the image. However, using deep learning super resolution techniques, these low-resolution images can be converted to high-resolution images. This work explores improving human tissue imaging by applying deep learning to maximize image quality while reducing fluorescence excitation exposure. We analyze two methods: a method based on U-Net, and a patch-based regression method. Both methods are evaluated on a skin dataset and an eye dataset. The eye dataset includes 1200 paired high power and low power images of retinal organoids. The skin dataset contains multiple frames of each sample of human skin. High-resolution images were formed by averaging 70 frames for each sample and low-resolution images were formed by averaging the first 7 and 15 frames for each sample. The skin dataset includes 550 images for each of the resolution levels. We track two measures of performance for the two methods: mean squared error (MSE) and structural similarity index measure (SSIM). For the eye dataset, the patches method achieves an average MSE of 27,611 compared to 146,855 for the U-Net method, and an average SSIM of 0.636 compared to 0.607 for the U-Net method. For the skin dataset, the patches method achieves an average MSE of 3.768 compared to 4.032 for the U-Net method, and an average SSIM of 0.824 compared to 0.783 for the U-Net method. Despite better performance on image quality, the patches method is worse than the U-Net method when comparing the speed of prediction, taking 303 seconds to predict one image compared to less than one second for the U-Net method.
Permutationless Many-Jet Event Reconstruction with Symmetry Preserving Attention Networks
Nov 03, 2020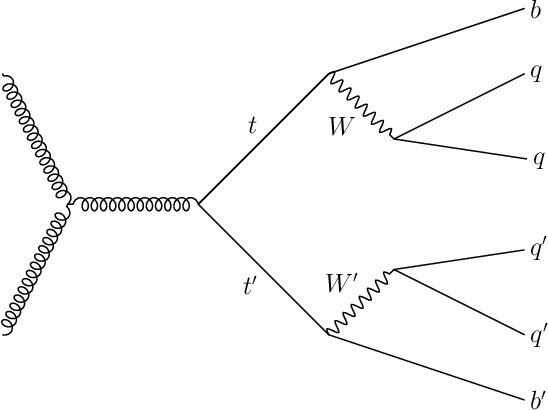
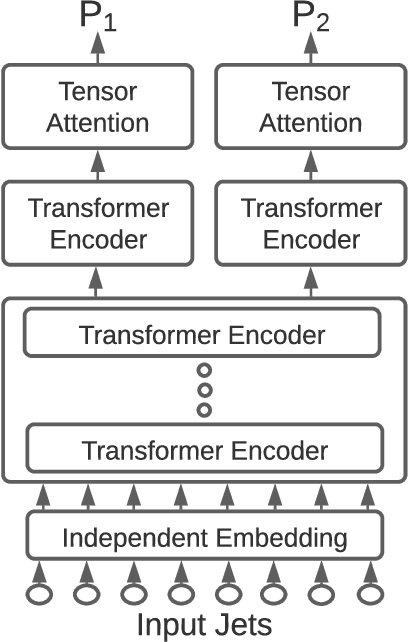
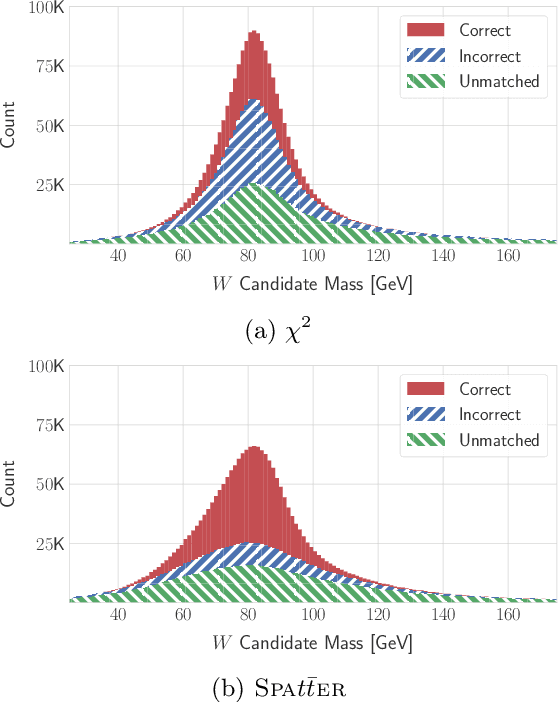
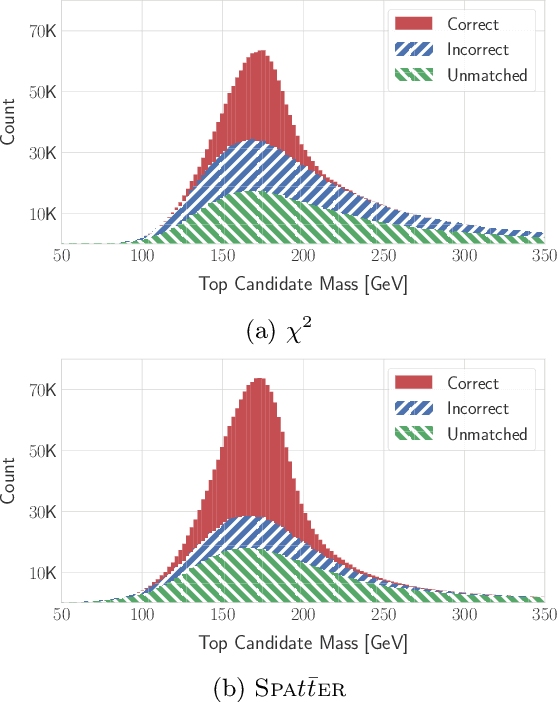
Top quarks, produced in large numbers at the Large Hadron Collider, have a complex detector signature and require special reconstruction techniques. The most common decay mode, the "all-jet" channel, results in a 6-jet final state which is particularly difficult to reconstruct in $pp$ collisions due to the large number of permutations possible. We present a novel approach to this class of problem, based on neural networks using a generalized attention mechanism, that we call Symmetry Preserving Attention Networks (SPA-Net). We train one such network to identify the decay products of each top quark unambiguously and without combinatorial explosion as an example of the power of this technique.This approach significantly outperforms existing state-of-the-art methods, correctly assigning all jets in $93.0%$ of $6$-jet, $87.8%$ of $7$-jet, and $82.6%$ of $\geq 8$-jet events respectively.
Quantity vs. Quality: On Hyperparameter Optimization for Deep Reinforcement Learning
Jul 30, 2020
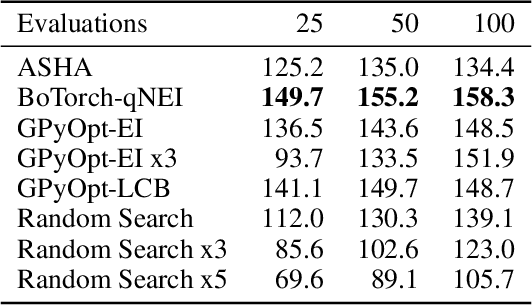
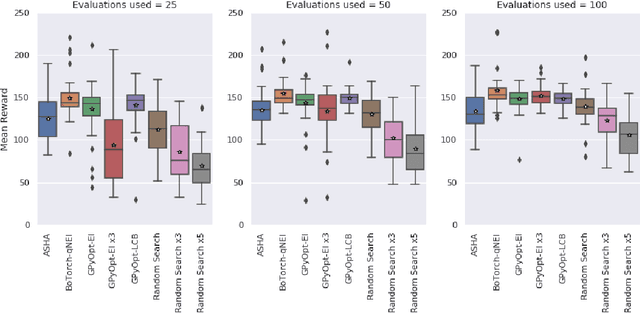
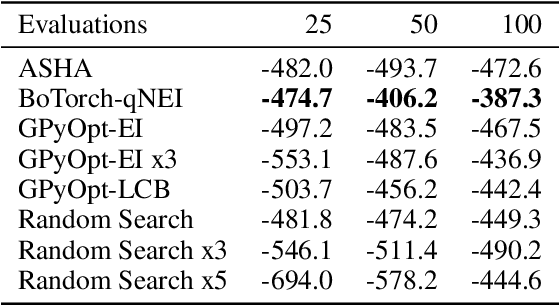
Reinforcement learning algorithms can show strong variation in performance between training runs with different random seeds. In this paper we explore how this affects hyperparameter optimization when the goal is to find hyperparameter settings that perform well across random seeds. In particular, we benchmark whether it is better to explore a large quantity of hyperparameter settings via pruning of bad performers, or if it is better to aim for quality of collected results by using repetitions. For this we consider the Successive Halving, Random Search, and Bayesian Optimization algorithms, the latter two with and without repetitions. We apply these to tuning the PPO2 algorithm on the Cartpole balancing task and the Inverted Pendulum Swing-up task. We demonstrate that pruning may negatively affect the optimization and that repeated sampling does not help in finding hyperparameter settings that perform better across random seeds. From our experiments we conclude that Bayesian optimization with a noise robust acquisition function is the best choice for hyperparameter optimization in reinforcement learning tasks.
SPLASH: Learnable Activation Functions for Improving Accuracy and Adversarial Robustness
Jun 16, 2020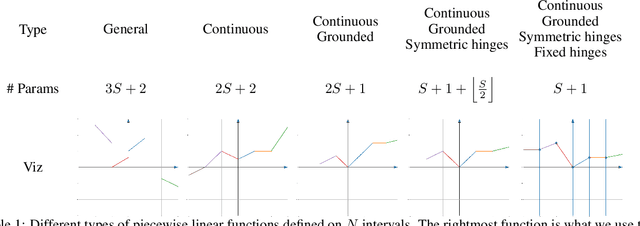
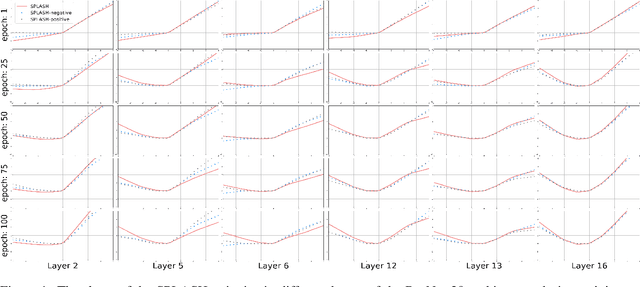
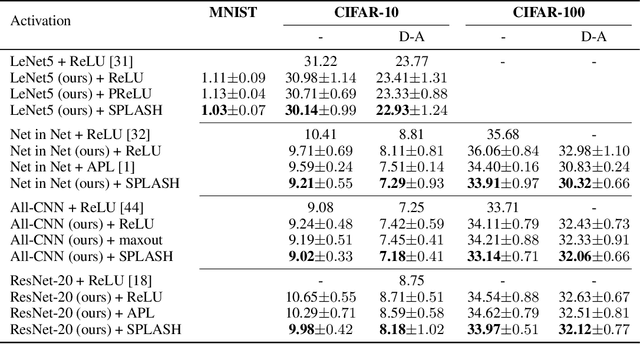
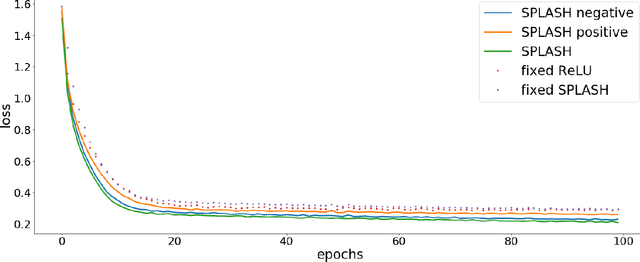
We introduce SPLASH units, a class of learnable activation functions shown to simultaneously improve the accuracy of deep neural networks while also improving their robustness to adversarial attacks. SPLASH units have both a simple parameterization and maintain the ability to approximate a wide range of non-linear functions. SPLASH units are: 1) continuous; 2) grounded (f(0) = 0); 3) use symmetric hinges; and 4) the locations of the hinges are derived directly from the data (i.e. no learning required). Compared to nine other learned and fixed activation functions, including ReLU and its variants, SPLASH units show superior performance across three datasets (MNIST, CIFAR-10, and CIFAR-100) and four architectures (LeNet5, All-CNN, ResNet-20, and Network-in-Network). Furthermore, we show that SPLASH units significantly increase the robustness of deep neural networks to adversarial attacks. Our experiments on both black-box and open-box adversarial attacks show that commonly-used architectures, namely LeNet5, All-CNN, ResNet-20, and Network-in-Network, can be up to 31% more robust to adversarial attacks by simply using SPLASH units instead of ReLUs.
Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games
Jun 15, 2020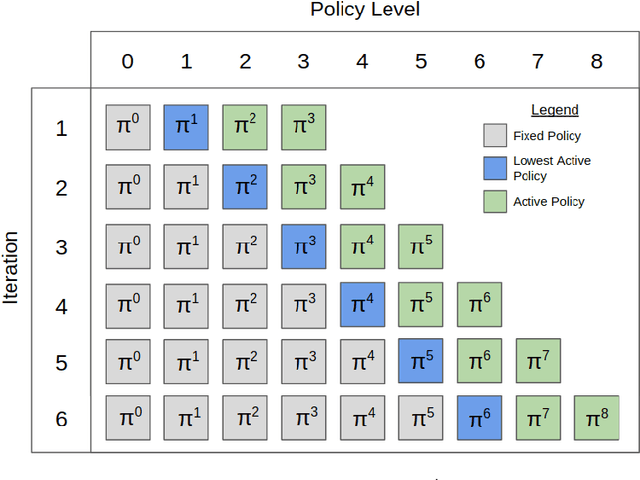
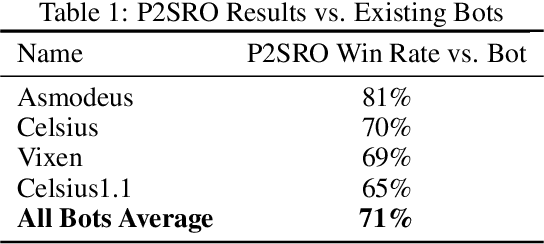
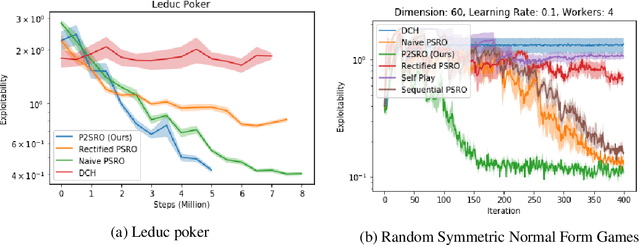
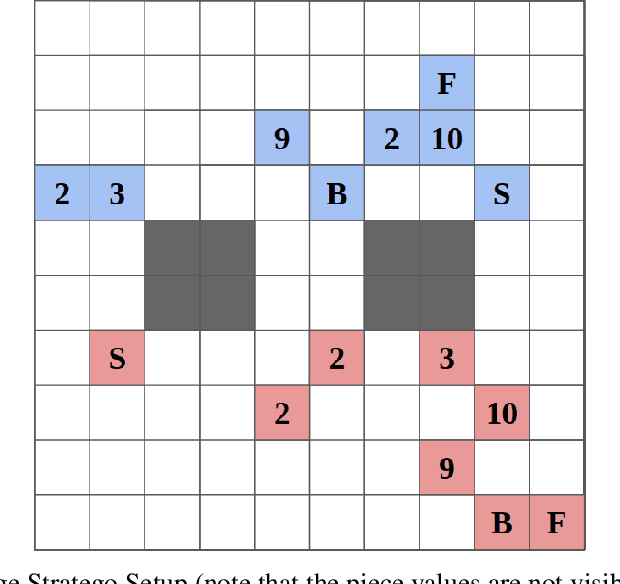
Finding approximate Nash equilibria in zero-sum imperfect-information games is challenging when the number of information states is large. Policy Space Response Oracles (PSRO) is a deep reinforcement learning algorithm grounded in game theory that is guaranteed to converge to an approximate Nash equilibrium. However, PSRO requires training a reinforcement learning policy at each iteration, making it too slow for large games. We show through counterexamples and experiments that DCH and Rectified PSRO, two existing approaches to scaling up PSRO, fail to converge even in small games. We introduce Pipeline PSRO (P2SRO), the first scalable general method for finding approximate Nash equilibria in large zero-sum imperfect-information games. P2SRO is able to parallelize PSRO with convergence guarantees by maintaining a hierarchical pipeline of reinforcement learning workers, each training against the policies generated by lower levels in the hierarchy. We show that unlike existing methods, P2SRO converges to an approximate Nash equilibrium, and does so faster as the number of parallel workers increases, across a variety of imperfect information games. We also introduce an open-source environment for Barrage Stratego, a variant of Stratego with an approximate game tree complexity of $10^{50}$. P2SRO is able to achieve state-of-the-art performance on Barrage Stratego and beats all existing bots.
Sherpa: Robust Hyperparameter Optimization for Machine Learning
May 08, 2020
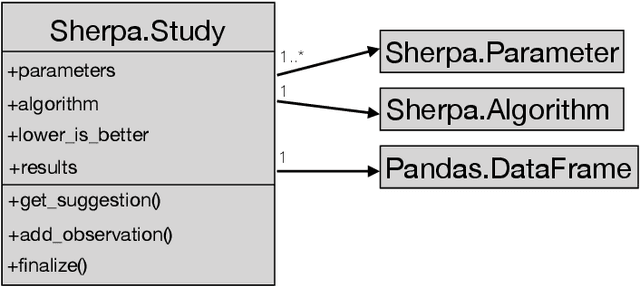
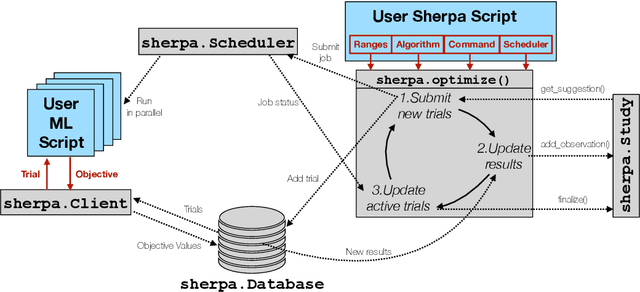
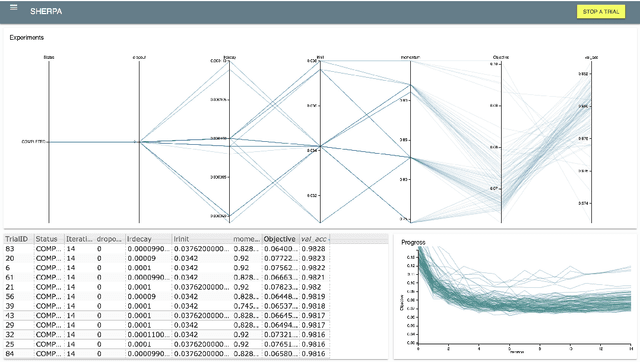
Sherpa is a hyperparameter optimization library for machine learning models. It is specifically designed for problems with computationally expensive, iterative function evaluations, such as the hyperparameter tuning of deep neural networks. With Sherpa, scientists can quickly optimize hyperparameters using a variety of powerful and interchangeable algorithms. Sherpa can be run on either a single machine or in parallel on a cluster. Finally, an interactive dashboard enables users to view the progress of models as they are trained, cancel trials, and explore which hyperparameter combinations are working best. Sherpa empowers machine learning practitioners by automating the more tedious aspects of model tuning. Its source code and documentation are available at https://github.com/sherpa-ai/sherpa.
Continuous Representation of Molecules Using Graph Variational Autoencoder
Apr 17, 2020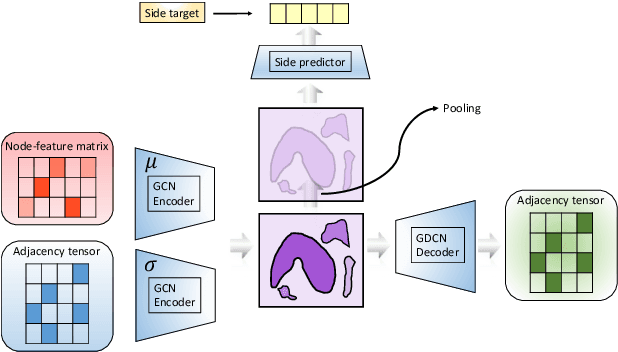
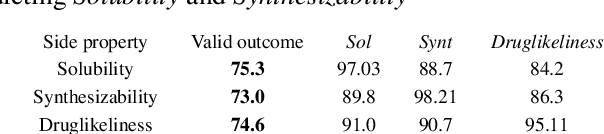
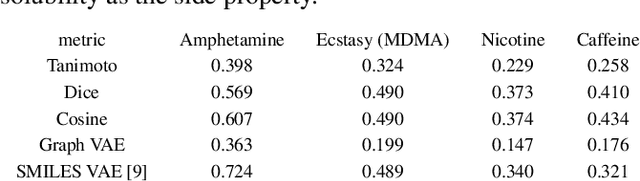
In order to continuously represent molecules, we propose a generative model in the form of a VAE which is operating on the 2D-graph structure of molecules. A side predictor is employed to prune the latent space and help the decoder in generating meaningful adjacency tensor of molecules. Other than the potential applicability in drug design and property prediction, we show the superior performance of this technique in comparison to other similar methods based on the SMILES representation of the molecules with RNN based encoder and decoder.
A Fortran-Keras Deep Learning Bridge for Scientific Computing
Apr 14, 2020

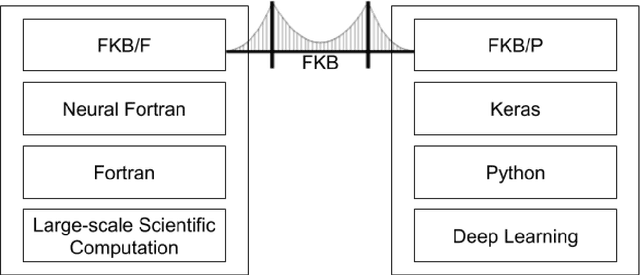
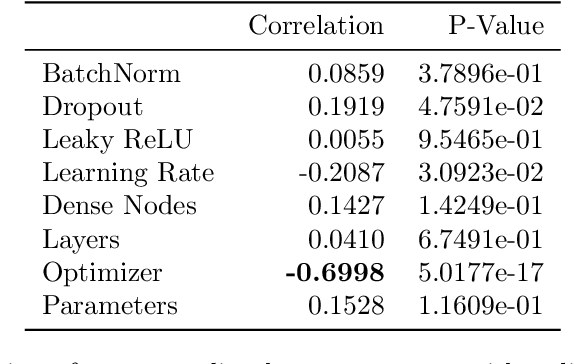
Implementing artificial neural networks is commonly achieved via high-level programming languages like Python, and easy-to-use deep learning libraries like Keras. These software libraries come pre-loaded with a variety of network architectures, provide autodifferentiation, and support GPUs for fast and efficient computation. As a result, a deep learning practitioner will favor training a neural network model in Python where these tools are readily available. However, many large-scale scientific computation projects are written in Fortran, which makes them difficult to integrate with modern deep learning methods. To alleviate this problem, we introduce a software library, the Fortran-Keras Bridge (FKB). This two-way bridge connects environments where deep learning resources are plentiful, with those where they are scarce. The paper describes a number of unique features offered by FKB, such as customizable layers, loss functions, and network ensembles. The paper concludes with a case study that applies FKB to address open questions about the robustness of an experimental approach to global climate simulation, in which subgrid physics are outsourced to deep neural network emulators. In this context, FKB enables a hyperparameter search of one hundred plus candidate models of subgrid cloud and radiation physics, initially implemented in Keras, to then be transferred and used in Fortran to assess their emergent behavior, i.e. when fit imperfections are coupled to explicit planetary scale fluid dynamics. The results reveal a previously unrecognized strong relationship between offline validation error and online performance, in which the choice of optimizer proves unexpectedly critical; this in turn helps identify a new optimized NN that demonstrates a 500 fold improvement of model stability compared to previously published results for this application.
Learning in the Machine: To Share or Not to Share?
Oct 04, 2019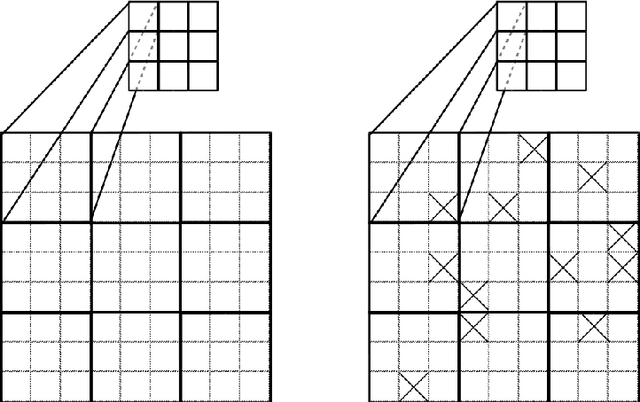
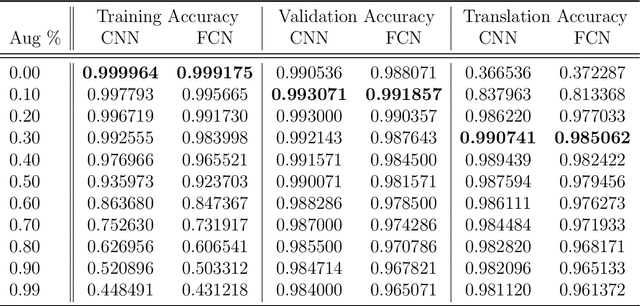
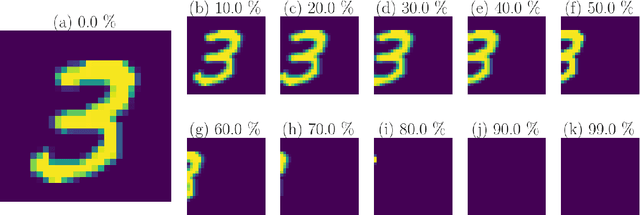
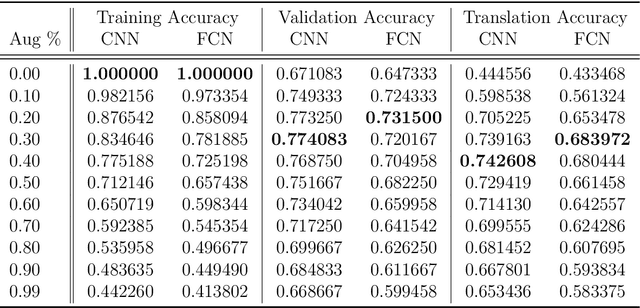
Weight-sharing is one of the pillars behind Convolutional Neural Networks and their successes. However, in physical neural systems such as the brain, weight-sharing is implausible. This discrepancy raises the fundamental question of whether weight-sharing is necessary. If so, to which degree of precision? If not, what are the alternatives? The goal of this study is to investigate these questions, primarily through simulations where the weight-sharing assumption is relaxed. Taking inspiration from neural circuitry, we explore the use of Free Convolutional Networks and neurons with variable connection patterns. Using Free Convolutional Networks, we show that while weight-sharing is a pragmatic optimization approach, it is not a necessity in computer vision applications. Furthermore, Free Convolutional Networks match the performance observed in standard architectures when trained using properly translated data (akin to video). Under the assumption of translationally augmented data, Free Convolutional Networks learn translationally invariant representations that yield an approximate form of weight sharing.