 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Was Scrolling and Then I Saw a Pregnant Strawberry
Jun 08, 2026AI minidramas (also known as fruit dramas) are short, algorithmically distributed generative AI video series featuring anthropomorphized characters that have recently emerged as a widespread phenomenon on social media platforms. This paper argues that despite their seemingly innocuous aesthetic, these videos reproduce deeply gendered narrative structures in which female characters are systematically associated with moral transgression, sexual betrayal, and reproductive capacity, and that several plots also encode the logic of racialization, i.e., the process by which visible bodily difference is morally loaded. Drawing on feminist film theory, critical race theory, and platform studies, it further argues that the generative AI aesthetic of these videos, characterized by softness, roundness, and visual cuteness, functions as a mechanism of aesthetic laundering, neutralizing the ideological weight of these narratives and enabling their circulation despite content moderation systems. This paper approaches these questions through personal observation and close reading, reflecting on the specific affordances of generative AI that make this phenomenon both possible and culturally consequential for the field of computational creativity.
Gender Artifacts from Art History to Text-to-Image Generation
Jun 04, 2026Artistic styles are rooted in specific socio-historical contexts that encode social hierarchies, including distinct constructions of gender. Yet in AI research, style has long been treated as a surface-level visual property: a filter of color, brushstroke, and texture applied to otherwise content-neutral scenes. We introduce the first dataset to investigate the interplay between gender representation and style in both historical and generated images. StyleGender comprises 74k images spanning 19 artistic styles, comprising art historical images with style and gender annotations, T2I-generated images under controlled style and gender prompts, and a semantically aligned set enabling direct art history-to-generation comparison. By proposing two Set Gender Artifact (SGA) metrics (PixelSGA and MaskSGA), capturing gender signals at the pixel level and in compositional structure, we show that (1) gender representation shapes visual features across artistic styles, (2) style keywords carry these patterns into T2I generation, and (3) generative models tend to amplify gender artifacts beyond what is observed in historical sources.
ImageSet2Text: Describing Sets of Images through Text
Mar 25, 2025



We introduce ImageSet2Text, a novel approach that leverages vision-language foundation models to automatically create natural language descriptions of image sets. Inspired by concept bottleneck models (CBMs) and based on visual-question answering (VQA) chains, ImageSet2Text iteratively extracts key concepts from image subsets, encodes them into a structured graph, and refines insights using an external knowledge graph and CLIP-based validation. This iterative process enhances interpretability and enables accurate and detailed set-level summarization. Through extensive experiments, we evaluate ImageSet2Text's descriptions on accuracy, completeness, readability and overall quality, benchmarking it against existing vision-language models and introducing new datasets for large-scale group image captioning.
Racial Bias in the Beautyverse
Sep 28, 2022
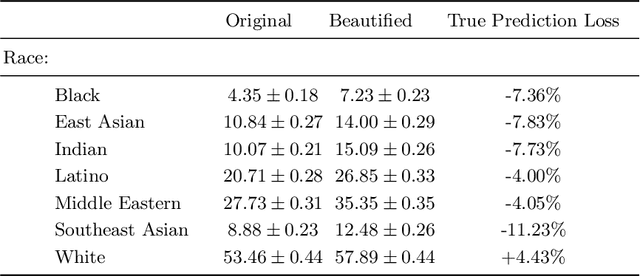
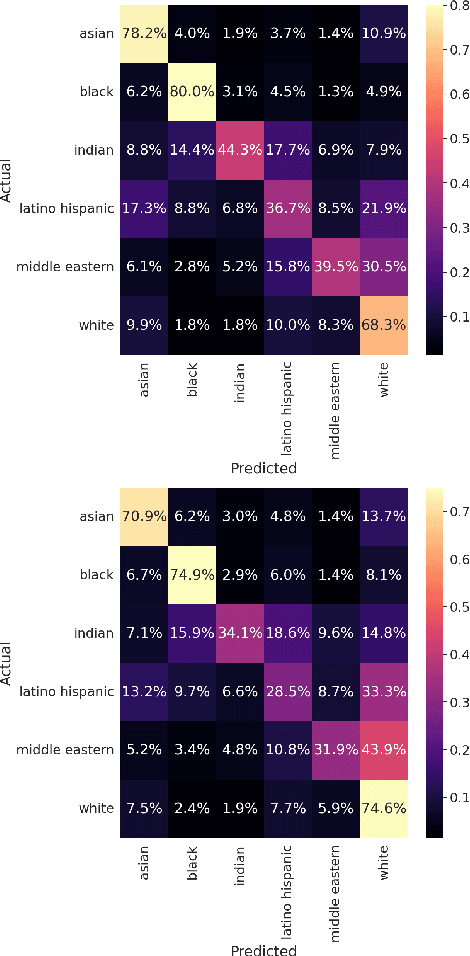
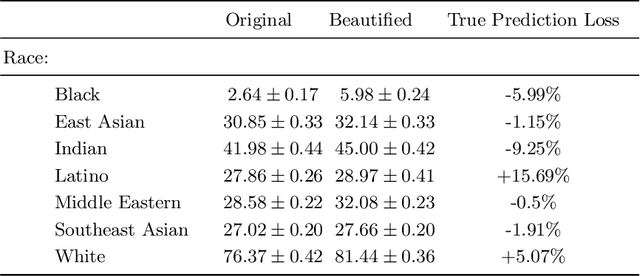
This short paper proposes a preliminary and yet insightful investigation of racial biases in beauty filters techniques currently used on social media. The obtained results are a call to action for researchers in Computer Vision: such biases risk being replicated and exaggerated in the Metaverse and, as a consequence, they deserve more attention from the community.
AI-based artistic representation of emotions from EEG signals: a discussion on fairness, inclusion, and aesthetics
Feb 07, 2022


While Artificial Intelligence (AI) technologies are being progressively developed, artists and researchers are investigating their role in artistic practices. In this work, we present an AI-based Brain-Computer Interface (BCI) in which humans and machines interact to express feelings artistically. This system and its production of images give opportunities to reflect on the complexities and range of human emotions and their expressions. In this discussion, we seek to understand the dynamics of this interaction to reach better co-existence in fairness, inclusion, and aesthetics.