 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Local LLM Agents for Linux Privilege Escalation with Verifiable Rewards
Mar 18, 2026LLM agents are increasingly relevant to research domains such as vulnerability discovery. Yet, the strongest systems remain closed and cloud-only, making them resource-intensive, difficult to reproduce, and unsuitable for work involving proprietary code or sensitive data. Consequently, there is an urgent need for small, local models that can perform security tasks under strict resource budgets, but methods for developing them remain underexplored. In this paper, we address this gap by proposing a two-stage post-training pipeline. We focus on the problem of Linux privilege escalation, where success is automatically verifiable and the task requires multi-step interactive reasoning. Using an experimental setup that prevents data leakage, we post-train a 4B model in two stages: supervised fine-tuning on traces from procedurally generated privilege-escalation environments, followed by reinforcement learning with verifiable rewards. On a held-out benchmark of 12 Linux privilege-escalation scenarios, supervised fine-tuning alone more than doubles the baseline success rate at 20 rounds, and reinforcement learning further lifts our resulting model, PrivEsc-LLM, to 95.8%, nearly matching Claude Opus 4.6 at 97.5%. At the same time, the expected inference cost per successful escalation is reduced by over 100x.
Pareto Front Approximation for Multi-Objective Session-Based Recommender Systems
Jul 23, 2024

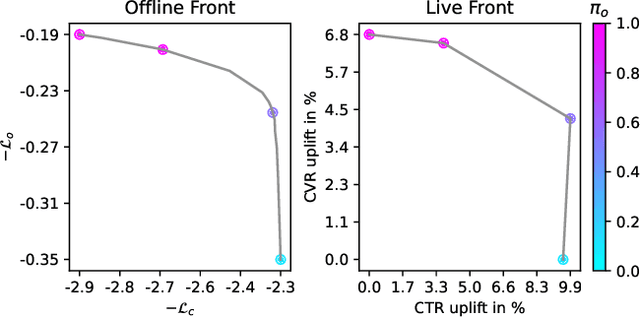

This work introduces MultiTRON, an approach that adapts Pareto front approximation techniques to multi-objective session-based recommender systems using a transformer neural network. Our approach optimizes trade-offs between key metrics such as click-through and conversion rates by training on sampled preference vectors. A significant advantage is that after training, a single model can access the entire Pareto front, allowing it to be tailored to meet the specific requirements of different stakeholders by adjusting an additional input vector that weights the objectives. We validate the model's performance through extensive offline and online evaluation. For broader application and research, the source code is made available at https://github.com/otto-de/MultiTRON . The results confirm the model's ability to manage multiple recommendation objectives effectively, offering a flexible tool for diverse business needs.
Scaling Session-Based Transformer Recommendations using Optimized Negative Sampling and Loss Functions
Jul 27, 2023This work introduces TRON, a scalable session-based Transformer Recommender using Optimized Negative-sampling. Motivated by the scalability and performance limitations of prevailing models such as SASRec and GRU4Rec+, TRON integrates top-k negative sampling and listwise loss functions to enhance its recommendation accuracy. Evaluations on relevant large-scale e-commerce datasets show that TRON improves upon the recommendation quality of current methods while maintaining training speeds similar to SASRec. A live A/B test yielded an 18.14% increase in click-through rate over SASRec, highlighting the potential of TRON in practical settings. For further research, we provide access to our source code at https://github.com/otto-de/TRON and an anonymized dataset at https://github.com/otto-de/recsys-dataset.