 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Transduce with Unbounded Memory
Nov 03, 2015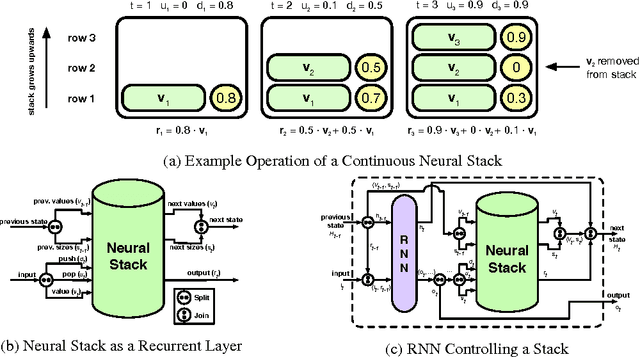

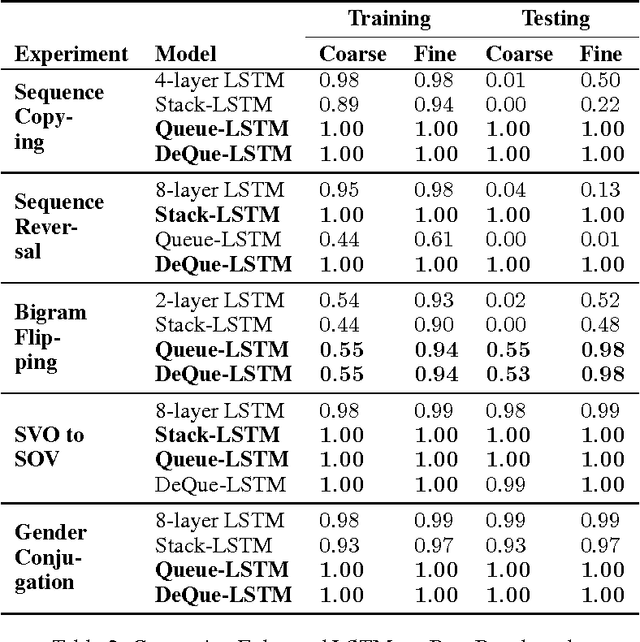
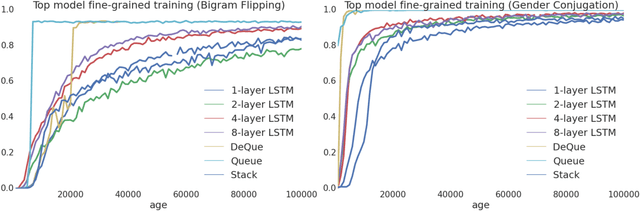
Recently, strong results have been demonstrated by Deep Recurrent Neural Networks on natural language transduction problems. In this paper we explore the representational power of these models using synthetic grammars designed to exhibit phenomena similar to those found in real transduction problems such as machine translation. These experiments lead us to propose new memory-based recurrent networks that implement continuously differentiable analogues of traditional data structures such as Stacks, Queues, and DeQues. We show that these architectures exhibit superior generalisation performance to Deep RNNs and are often able to learn the underlying generating algorithms in our transduction experiments.
A Bayesian Model for Generative Transition-based Dependency Parsing
Jun 28, 2015
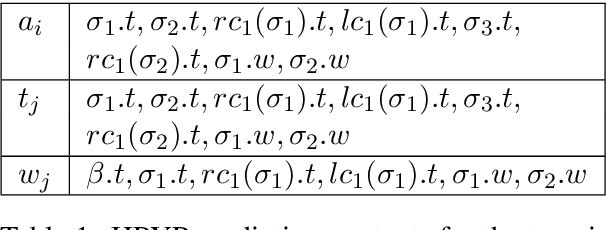
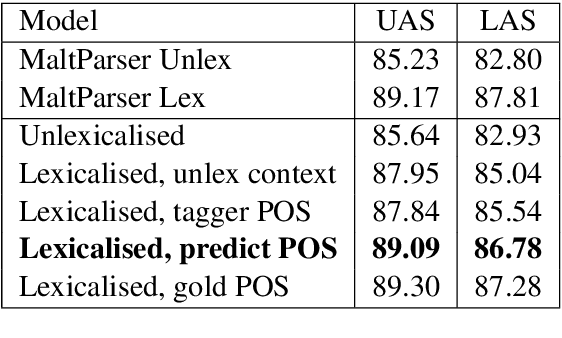
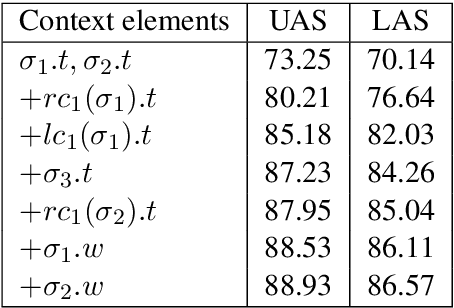
We propose a simple, scalable, fully generative model for transition-based dependency parsing with high accuracy. The model, parameterized by Hierarchical Pitman-Yor Processes, overcomes the limitations of previous generative models by allowing fast and accurate inference. We propose an efficient decoding algorithm based on particle filtering that can adapt the beam size to the uncertainty in the model while jointly predicting POS tags and parse trees. The UAS of the parser is on par with that of a greedy discriminative baseline. As a language model, it obtains better perplexity than a n-gram model by performing semi-supervised learning over a large unlabelled corpus. We show that the model is able to generate locally and syntactically coherent sentences, opening the door to further applications in language generation.
Pragmatic Neural Language Modelling in Machine Translation
Mar 20, 2015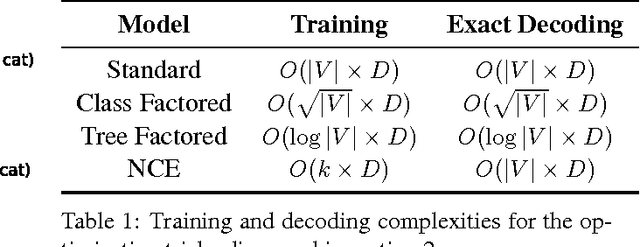
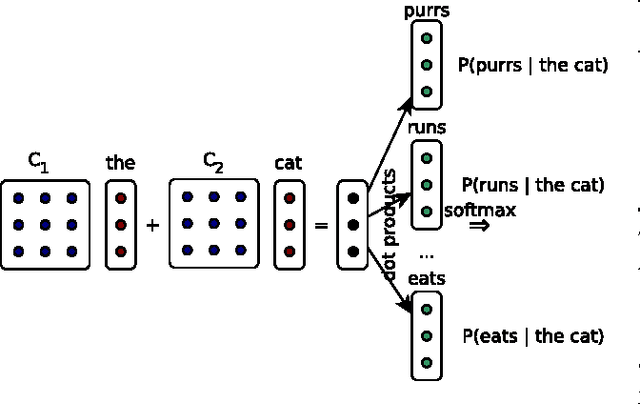

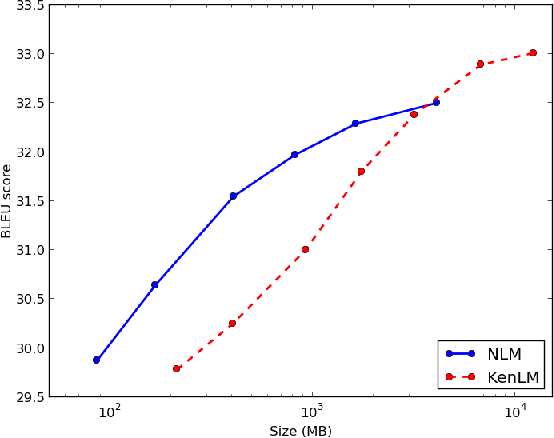
This paper presents an in-depth investigation on integrating neural language models in translation systems. Scaling neural language models is a difficult task, but crucial for real-world applications. This paper evaluates the impact on end-to-end MT quality of both new and existing scaling techniques. We show when explicitly normalising neural models is necessary and what optimisation tricks one should use in such scenarios. We also focus on scalable training algorithms and investigate noise contrastive estimation and diagonal contexts as sources for further speed improvements. We explore the trade-offs between neural models and back-off n-gram models and find that neural models make strong candidates for natural language applications in memory constrained environments, yet still lag behind traditional models in raw translation quality. We conclude with a set of recommendations one should follow to build a scalable neural language model for MT.
Bayesian Optimisation for Machine Translation
Dec 22, 2014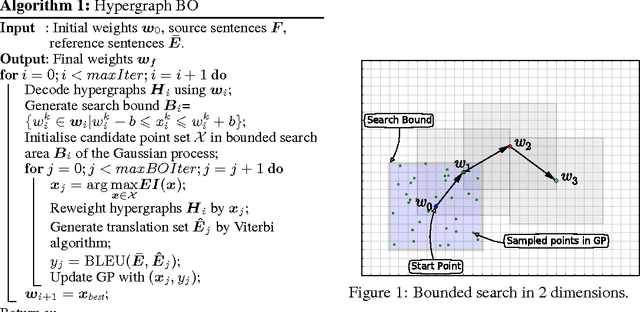
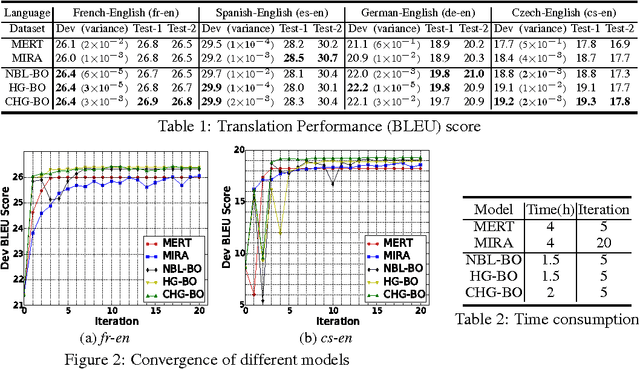
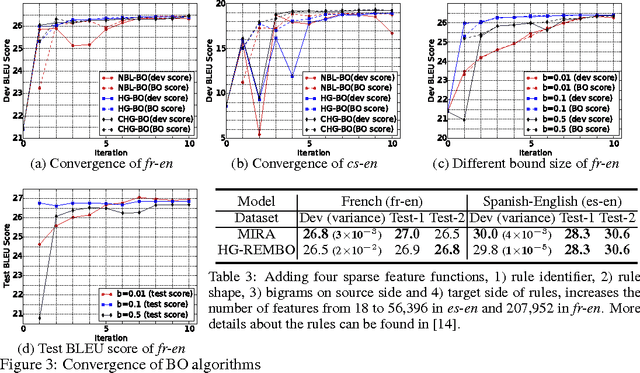
This paper presents novel Bayesian optimisation algorithms for minimum error rate training of statistical machine translation systems. We explore two classes of algorithms for efficiently exploring the translation space, with the first based on N-best lists and the second based on a hypergraph representation that compactly represents an exponential number of translation options. Our algorithms exhibit faster convergence and are capable of obtaining lower error rates than the existing translation model specific approaches, all within a generic Bayesian optimisation framework. Further more, we also introduce a random embedding algorithm to scale our approach to sparse high dimensional feature sets.
Deep Multi-Instance Transfer Learning
Dec 10, 2014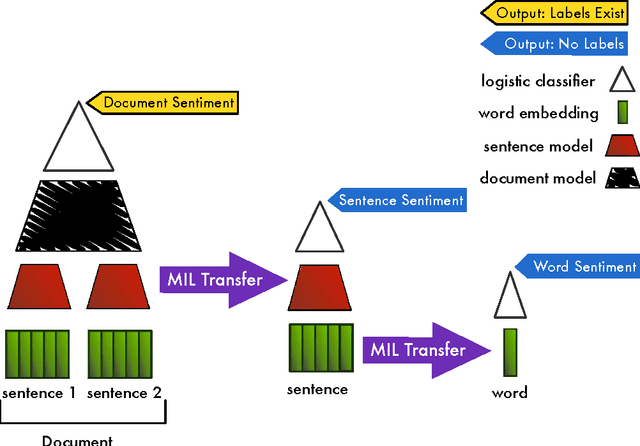


We present a new approach for transferring knowledge from groups to individuals that comprise them. We evaluate our method in text, by inferring the ratings of individual sentences using full-review ratings. This approach, which combines ideas from transfer learning, deep learning and multi-instance learning, reduces the need for laborious human labelling of fine-grained data when abundant labels are available at the group level.
Deep Learning for Answer Sentence Selection
Dec 04, 2014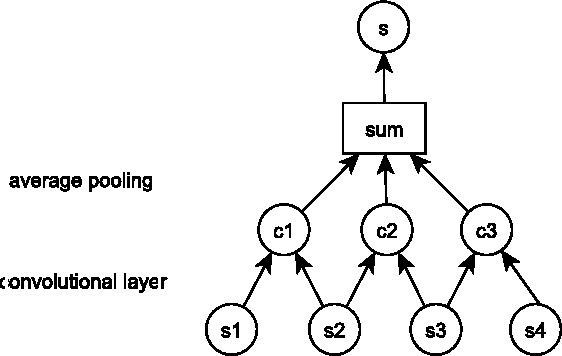
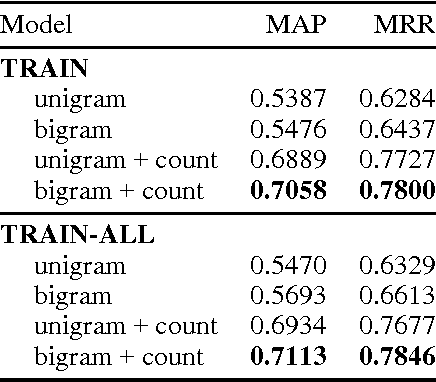
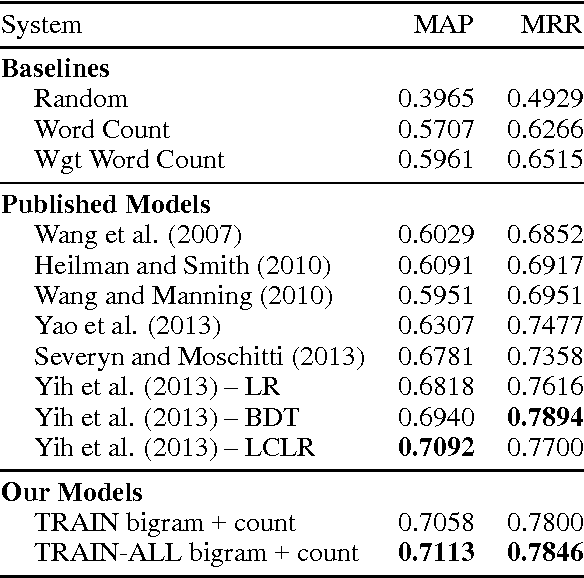
Answer sentence selection is the task of identifying sentences that contain the answer to a given question. This is an important problem in its own right as well as in the larger context of open domain question answering. We propose a novel approach to solving this task via means of distributed representations, and learn to match questions with answers by considering their semantic encoding. This contrasts prior work on this task, which typically relies on classifiers with large numbers of hand-crafted syntactic and semantic features and various external resources. Our approach does not require any feature engineering nor does it involve specialist linguistic data, making this model easily applicable to a wide range of domains and languages. Experimental results on a standard benchmark dataset from TREC demonstrate that---despite its simplicity---our model matches state of the art performance on the answer sentence selection task.
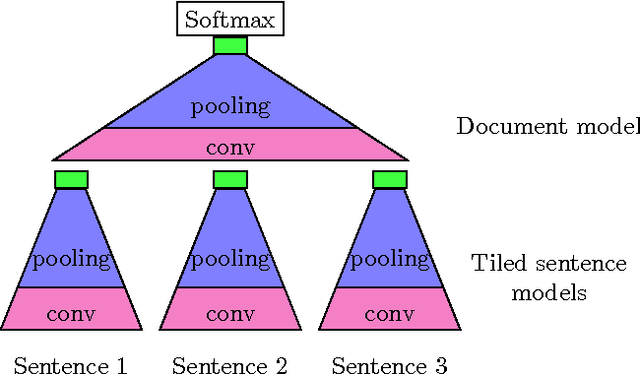
Modelling, Visualising and Summarising Documents with a Single Convolutional Neural Network
Jun 15, 2014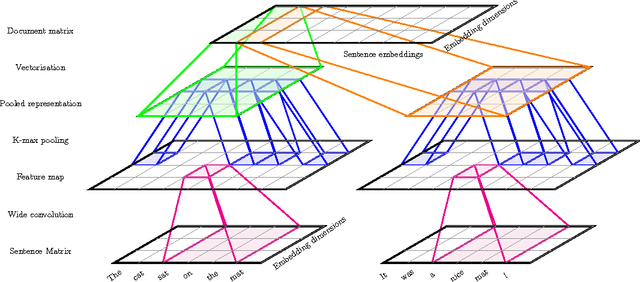

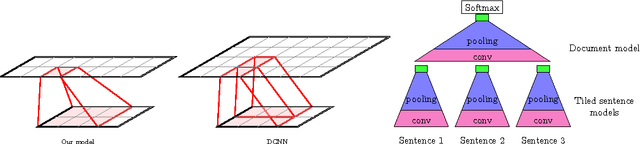
Capturing the compositional process which maps the meaning of words to that of documents is a central challenge for researchers in Natural Language Processing and Information Retrieval. We introduce a model that is able to represent the meaning of documents by embedding them in a low dimensional vector space, while preserving distinctions of word and sentence order crucial for capturing nuanced semantics. Our model is based on an extended Dynamic Convolution Neural Network, which learns convolution filters at both the sentence and document level, hierarchically learning to capture and compose low level lexical features into high level semantic concepts. We demonstrate the effectiveness of this model on a range of document modelling tasks, achieving strong results with no feature engineering and with a more compact model. Inspired by recent advances in visualising deep convolution networks for computer vision, we present a novel visualisation technique for our document networks which not only provides insight into their learning process, but also can be interpreted to produce a compelling automatic summarisation system for texts.
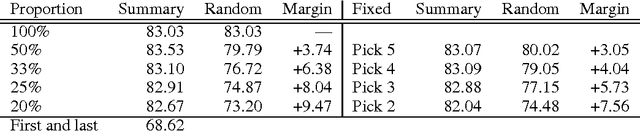
Compositional Morphology for Word Representations and Language Modelling
May 16, 2014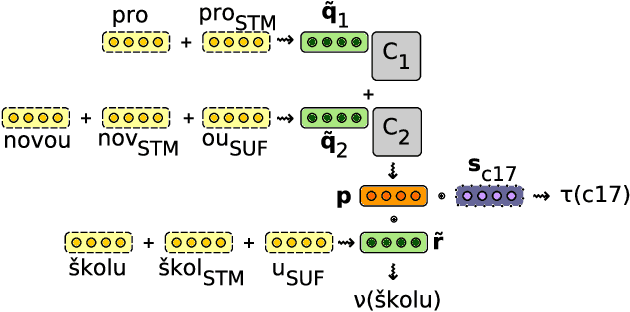
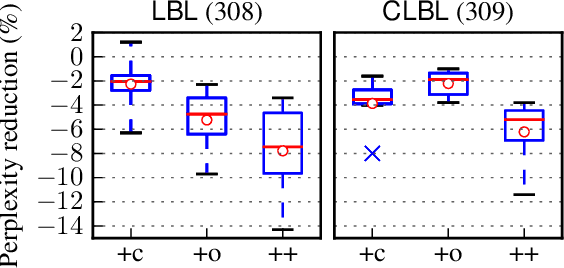
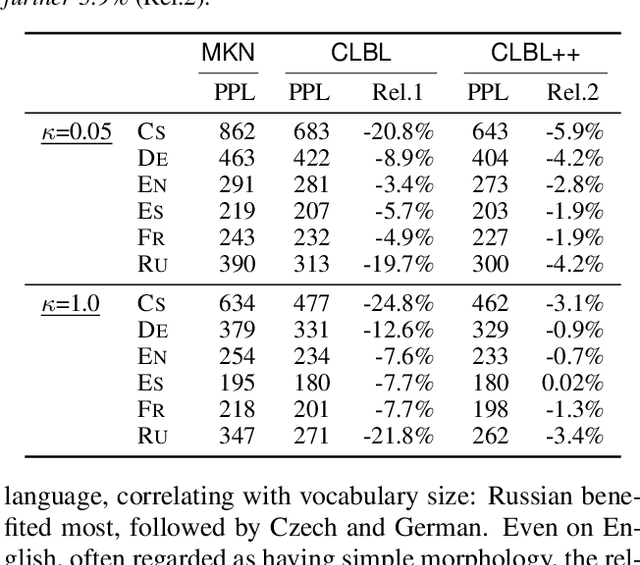
This paper presents a scalable method for integrating compositional morphological representations into a vector-based probabilistic language model. Our approach is evaluated in the context of log-bilinear language models, rendered suitably efficient for implementation inside a machine translation decoder by factoring the vocabulary. We perform both intrinsic and extrinsic evaluations, presenting results on a range of languages which demonstrate that our model learns morphological representations that both perform well on word similarity tasks and lead to substantial reductions in perplexity. When used for translation into morphologically rich languages with large vocabularies, our models obtain improvements of up to 1.2 BLEU points relative to a baseline system using back-off n-gram models.
Learning Bilingual Word Representations by Marginalizing Alignments
May 05, 2014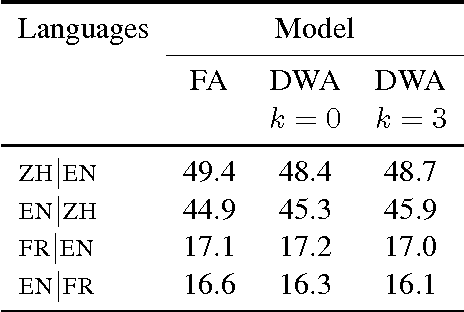

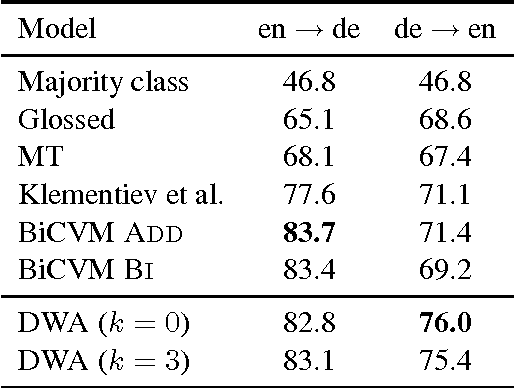

We present a probabilistic model that simultaneously learns alignments and distributed representations for bilingual data. By marginalizing over word alignments the model captures a larger semantic context than prior work relying on hard alignments. The advantage of this approach is demonstrated in a cross-lingual classification task, where we outperform the prior published state of the art.
A Deep Architecture for Semantic Parsing
Apr 29, 2014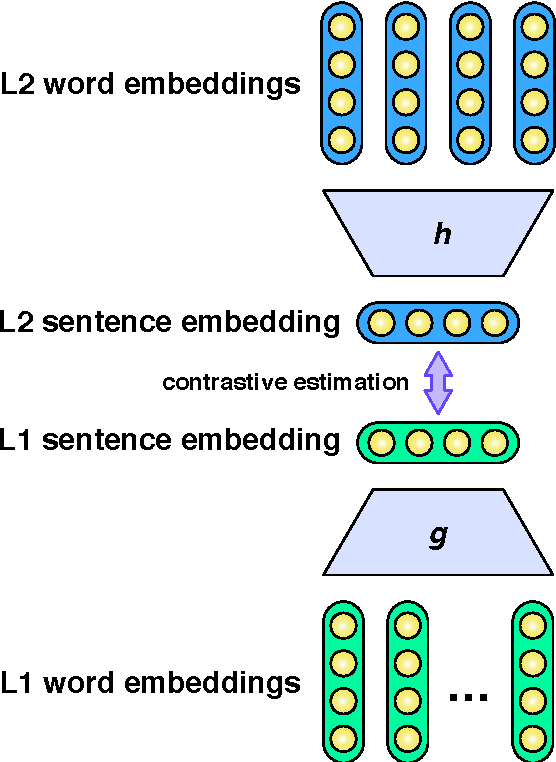
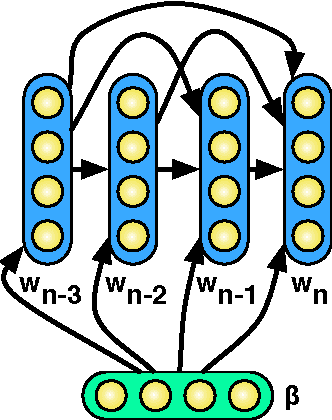
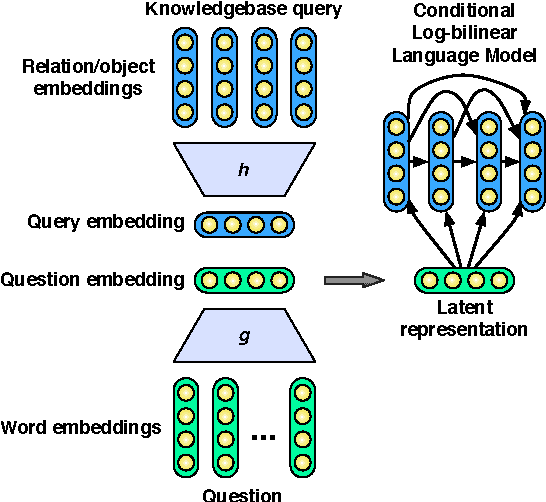
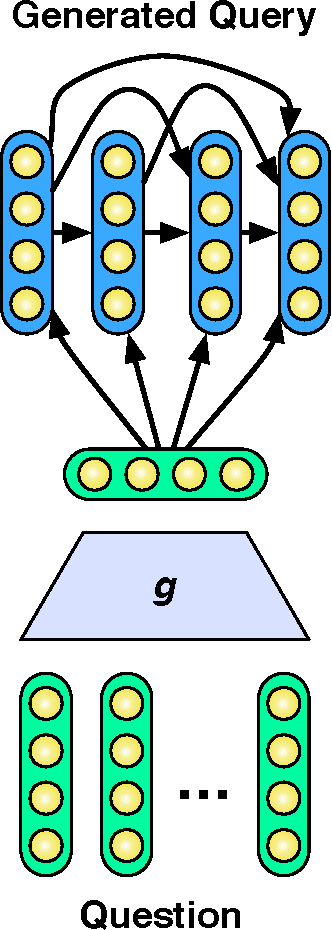
Many successful approaches to semantic parsing build on top of the syntactic analysis of text, and make use of distributional representations or statistical models to match parses to ontology-specific queries. This paper presents a novel deep learning architecture which provides a semantic parsing system through the union of two neural models of language semantics. It allows for the generation of ontology-specific queries from natural language statements and questions without the need for parsing, which makes it especially suitable to grammatically malformed or syntactically atypical text, such as tweets, as well as permitting the development of semantic parsers for resource-poor languages.