 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing Congestion Problems in Multi-agent Reinforcement Learning
Mar 30, 2017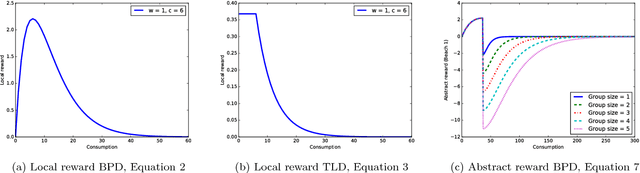

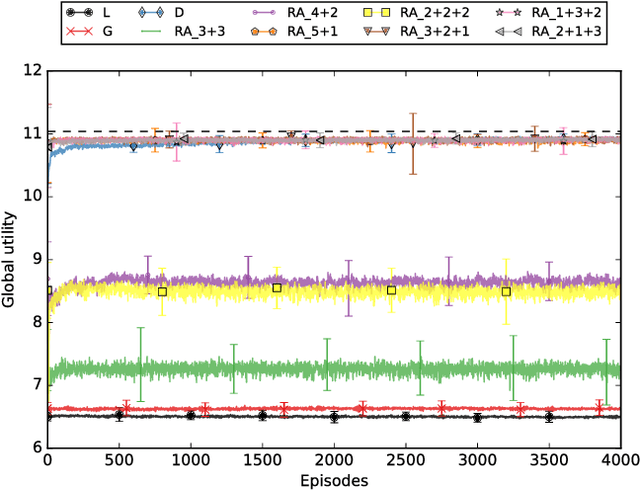
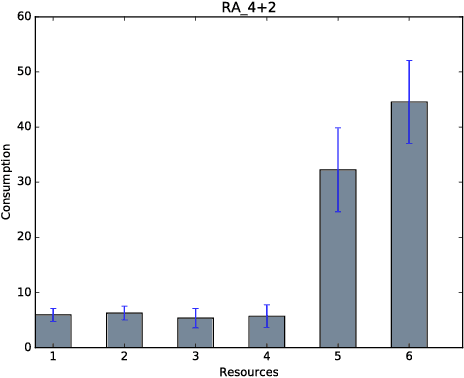
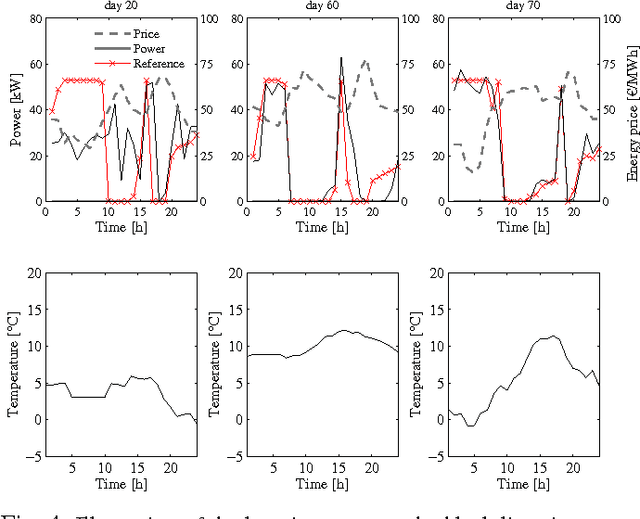
Congestion problems are omnipresent in today's complex networks and represent a challenge in many research domains. In the context of Multi-agent Reinforcement Learning (MARL), approaches like difference rewards and resource abstraction have shown promising results in tackling such problems. Resource abstraction was shown to be an ideal candidate for solving large-scale resource allocation problems in a fully decentralized manner. However, its performance and applicability strongly depends on some, until now, undocumented assumptions. Two of the main congestion benchmark problems considered in the literature are: the Beach Problem Domain and the Traffic Lane Domain. In both settings the highest system utility is achieved when overcrowding one resource and keeping the rest at optimum capacity. We analyse how abstract grouping can promote this behaviour and how feasible it is to apply this approach in a real-world domain (i.e., what assumptions need to be satisfied and what knowledge is necessary). We introduce a new test problem, the Road Network Domain (RND), where the resources are no longer independent, but rather part of a network (e.g., road network), thus choosing one path will also impact the load on other paths having common road segments. We demonstrate the application of state-of-the-art MARL methods for this new congestion model and analyse their performance. RND allows us to highlight an important limitation of resource abstraction and show that the difference rewards approach manages to better capture and inform the agents about the dynamics of the environment.
Convolutional Neural Networks For Automatic State-Time Feature Extraction in Reinforcement Learning Applied to Residential Load Control
Oct 11, 2016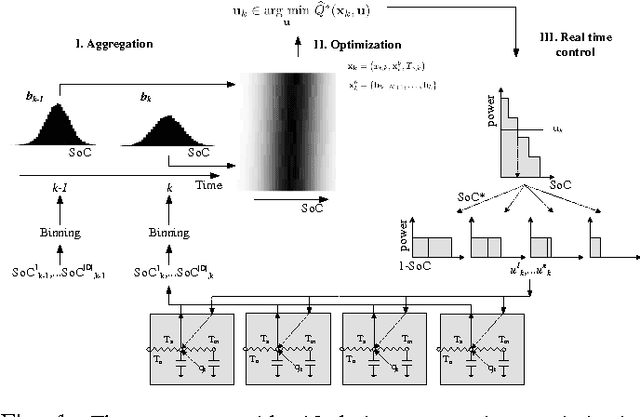
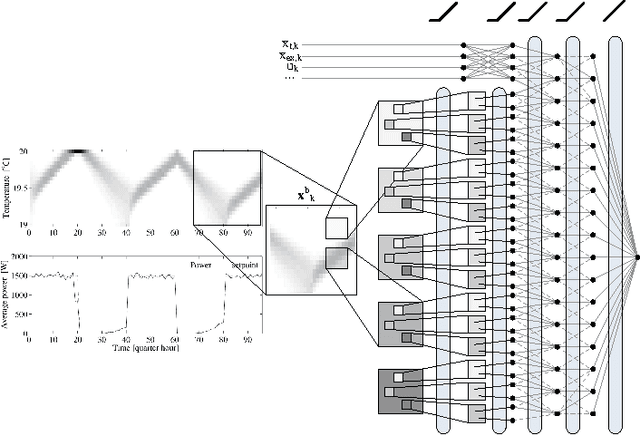
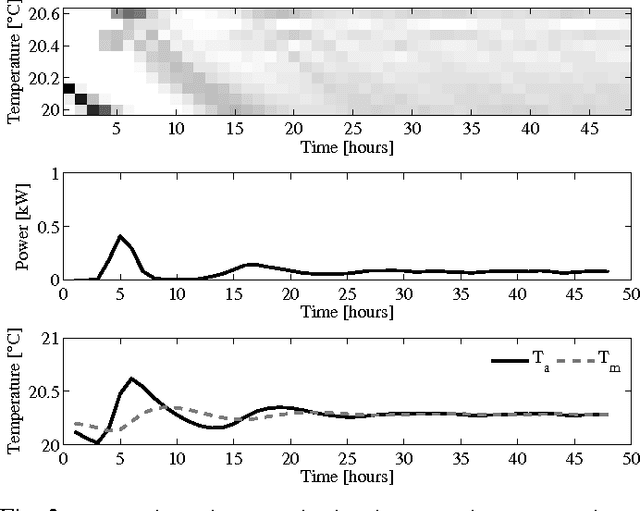
Direct load control of a heterogeneous cluster of residential demand flexibility sources is a high-dimensional control problem with partial observability. This work proposes a novel approach that uses a convolutional neural network to extract hidden state-time features to mitigate the curse of partial observability. More specific, a convolutional neural network is used as a function approximator to estimate the state-action value function or Q-function in the supervised learning step of fitted Q-iteration. The approach is evaluated in a qualitative simulation, comprising a cluster of thermostatically controlled loads that only share their air temperature, whilst their envelope temperature remains hidden. The simulation results show that the presented approach is able to capture the underlying hidden features and successfully reduce the electricity cost the cluster.
An Empirical Comparison of Neural Architectures for Reinforcement Learning in Partially Observable Environments
Dec 17, 2015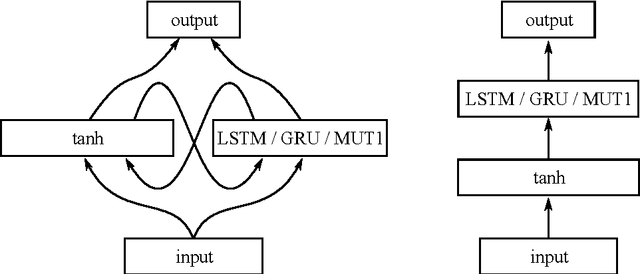
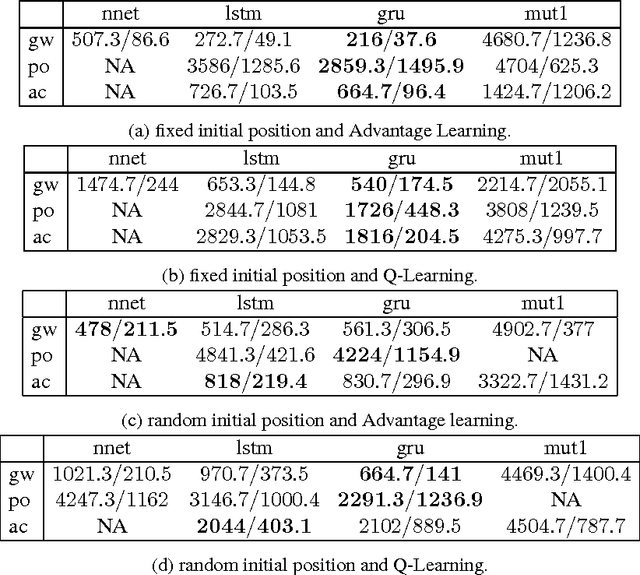

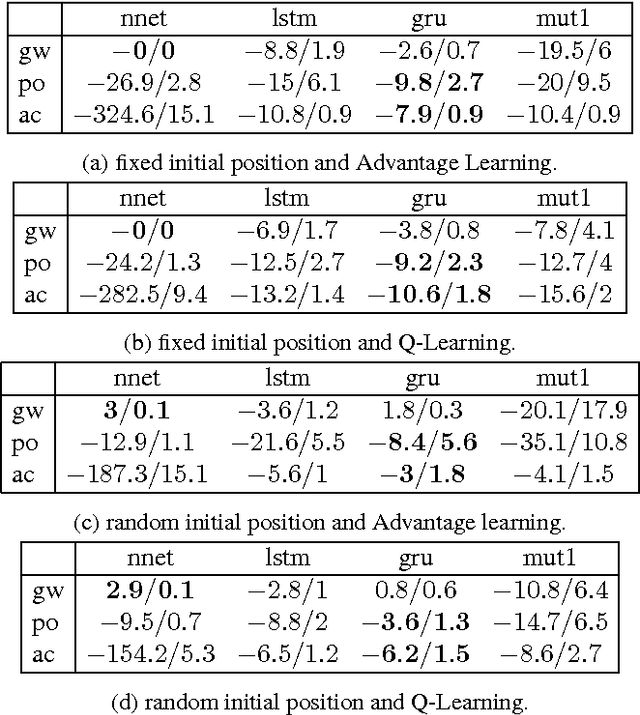
This paper explores the performance of fitted neural Q iteration for reinforcement learning in several partially observable environments, using three recurrent neural network architectures: Long Short-Term Memory, Gated Recurrent Unit and MUT1, a recurrent neural architecture evolved from a pool of several thousands candidate architectures. A variant of fitted Q iteration, based on Advantage values instead of Q values, is also explored. The results show that GRU performs significantly better than LSTM and MUT1 for most of the problems considered, requiring less training episodes and less CPU time before learning a very good policy. Advantage learning also tends to produce better results.
Off-Policy Reward Shaping with Ensembles
Mar 23, 2015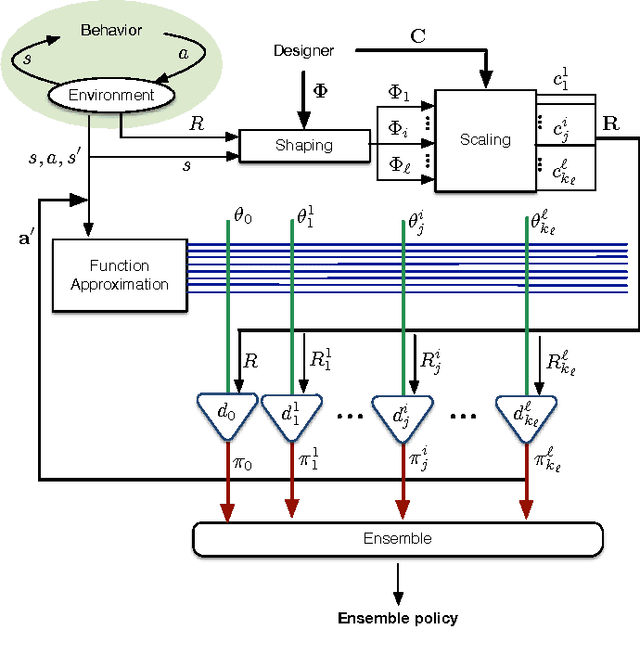
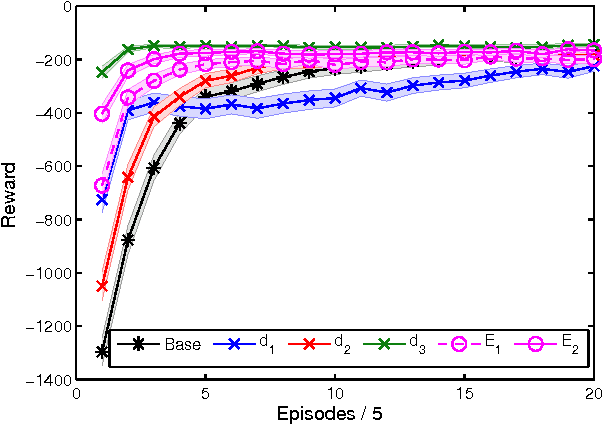
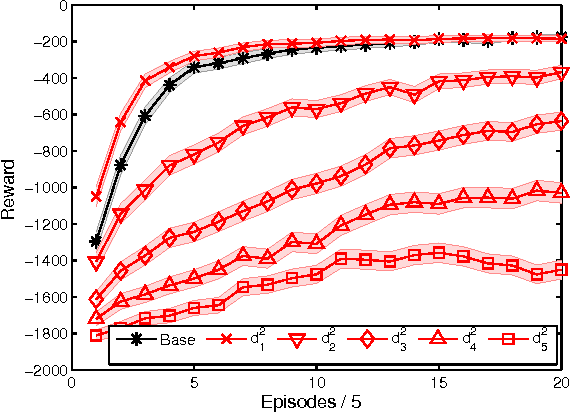
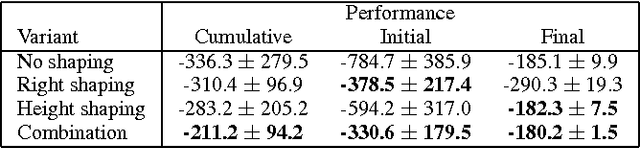
Potential-based reward shaping (PBRS) is an effective and popular technique to speed up reinforcement learning by leveraging domain knowledge. While PBRS is proven to always preserve optimal policies, its effect on learning speed is determined by the quality of its potential function, which, in turn, depends on both the underlying heuristic and the scale. Knowing which heuristic will prove effective requires testing the options beforehand, and determining the appropriate scale requires tuning, both of which introduce additional sample complexity. We formulate a PBRS framework that reduces learning speed, but does not incur extra sample complexity. For this, we propose to simultaneously learn an ensemble of policies, shaped w.r.t. many heuristics and on a range of scales. The target policy is then obtained by voting. The ensemble needs to be able to efficiently and reliably learn off-policy: requirements fulfilled by the recent Horde architecture, which we take as our basis. We demonstrate empirically that (1) our ensemble policy outperforms both the base policy, and its single-heuristic components, and (2) an ensemble over a general range of scales performs at least as well as one with optimally tuned components.
Off-Policy Shaping Ensembles in Reinforcement Learning
May 21, 2014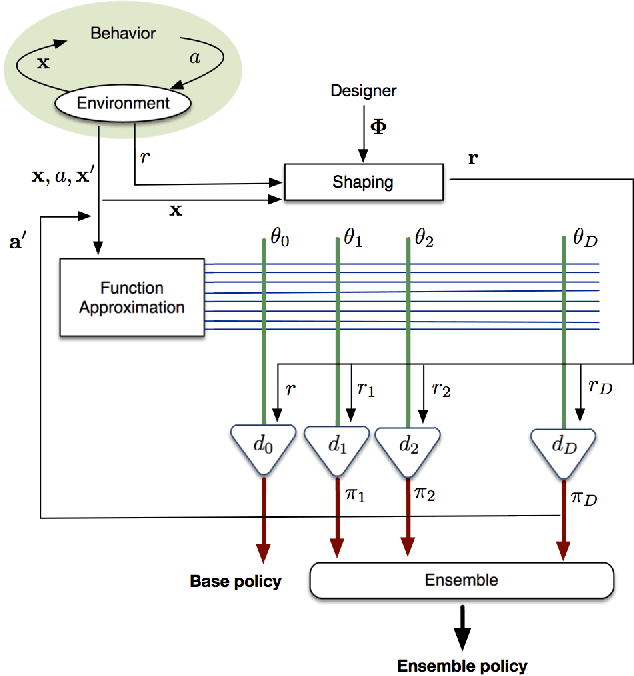

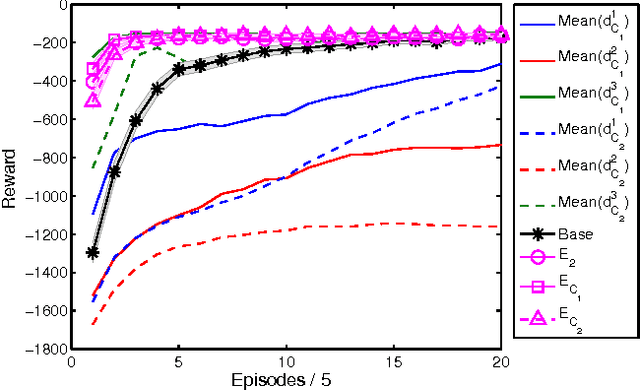
Recent advances of gradient temporal-difference methods allow to learn off-policy multiple value functions in parallel with- out sacrificing convergence guarantees or computational efficiency. This opens up new possibilities for sound ensemble techniques in reinforcement learning. In this work we propose learning an ensemble of policies related through potential-based shaping rewards. The ensemble induces a combination policy by using a voting mechanism on its components. Learning happens in real time, and we empirically show the combination policy to outperform the individual policies of the ensemble.