Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Shaping Ensembles in Reinforcement Learning
Paper and Code
May 21, 2014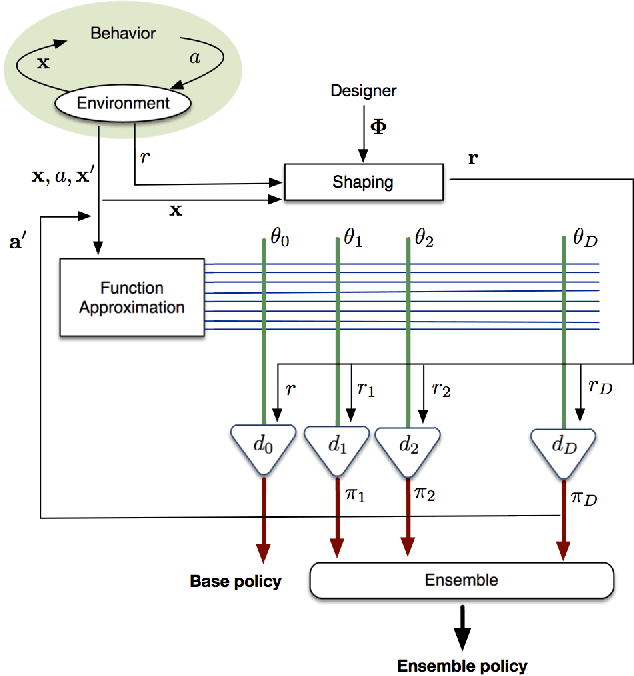
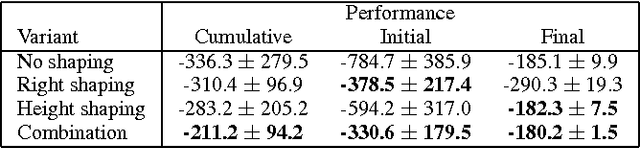
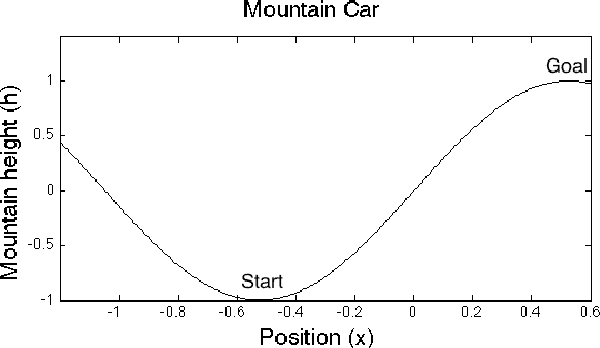

Recent advances of gradient temporal-difference methods allow to learn off-policy multiple value functions in parallel with- out sacrificing convergence guarantees or computational efficiency. This opens up new possibilities for sound ensemble techniques in reinforcement learning. In this work we propose learning an ensemble of policies related through potential-based shaping rewards. The ensemble induces a combination policy by using a voting mechanism on its components. Learning happens in real time, and we empirically show the combination policy to outperform the individual policies of the ensemble.
* Full version of the paper to appear in Proc. ECAI 2014
View paper on