 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Reward Shaping with Ensembles
Paper and Code
Mar 23, 2015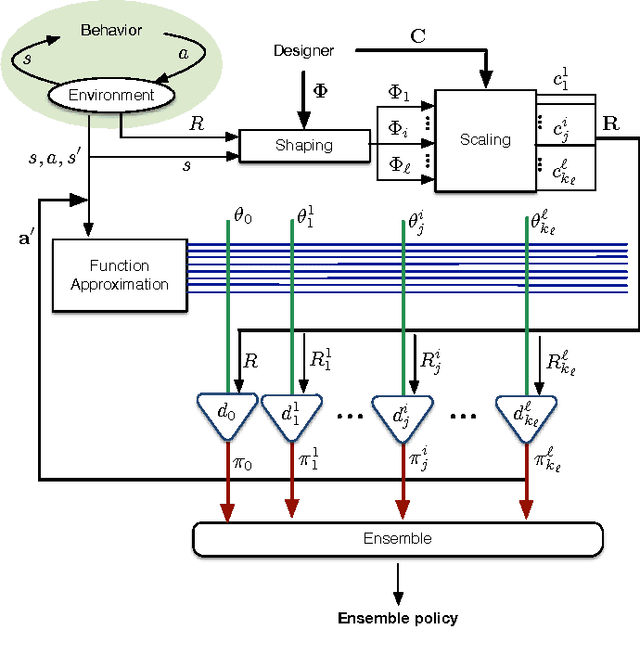
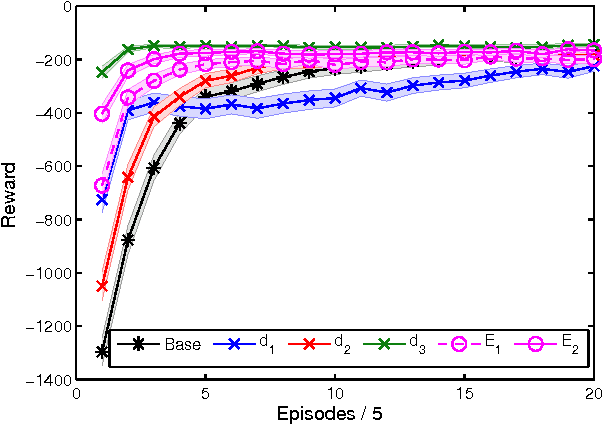
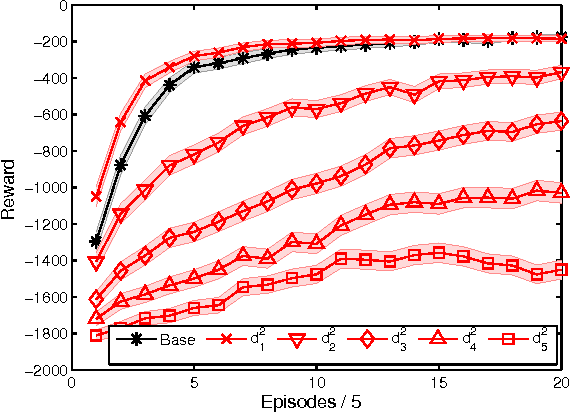
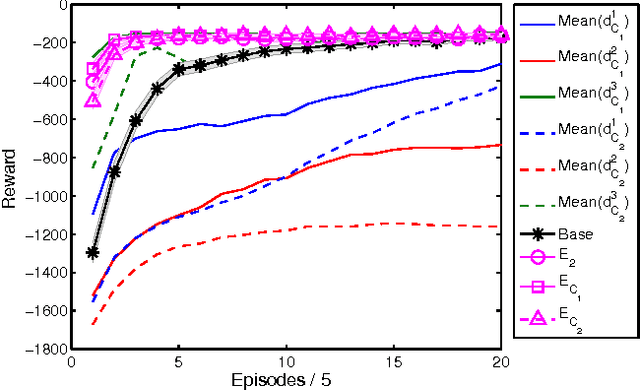
Potential-based reward shaping (PBRS) is an effective and popular technique to speed up reinforcement learning by leveraging domain knowledge. While PBRS is proven to always preserve optimal policies, its effect on learning speed is determined by the quality of its potential function, which, in turn, depends on both the underlying heuristic and the scale. Knowing which heuristic will prove effective requires testing the options beforehand, and determining the appropriate scale requires tuning, both of which introduce additional sample complexity. We formulate a PBRS framework that reduces learning speed, but does not incur extra sample complexity. For this, we propose to simultaneously learn an ensemble of policies, shaped w.r.t. many heuristics and on a range of scales. The target policy is then obtained by voting. The ensemble needs to be able to efficiently and reliably learn off-policy: requirements fulfilled by the recent Horde architecture, which we take as our basis. We demonstrate empirically that (1) our ensemble policy outperforms both the base policy, and its single-heuristic components, and (2) an ensemble over a general range of scales performs at least as well as one with optimally tuned components.