 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered Evaluation of an LLM-Based Process Modeling Copilot: A Mixed-Methods Study with Domain Experts
Mar 13, 2026Integrating Large Language Models (LLMs) into business process management tools promises to democratize Business Process Model and Notation (BPMN) modeling for non-experts. While automated frameworks assess syntactic and semantic quality, they miss human factors like trust, usability, and professional alignment. We conducted a mixed-methods evaluation of our proposed solution, an LLM-powered BPMN copilot, with five process modeling experts using focus groups and standardized questionnaires. Our findings reveal a critical tension between acceptable perceived usability (mean CUQ score: 67.2/100) and notably lower trust (mean score: 48.8\%), with reliability rated as the most critical concern (M=1.8/5). Furthermore, we identified output-quality issues, prompting difficulties, and a need for the LLM to ask more in-depth clarifying questions about the process. We envision five use cases ranging from domain-expert support to enterprise quality assurance. We demonstrate the necessity of human-centered evaluation complementing automated benchmarking for LLM modeling agents.
* Human-centered Evaluation and Auditing of Language Models Workshop
Assessing the Business Process Modeling Competences of Large Language Models
Jan 29, 2026The creation of Business Process Model and Notation (BPMN) models is a complex and time-consuming task requiring both domain knowledge and proficiency in modeling conventions. Recent advances in large language models (LLMs) have significantly expanded the possibilities for generating BPMN models directly from natural language, building upon earlier text-to-process methods with enhanced capabilities in handling complex descriptions. However, there is a lack of systematic evaluations of LLM-generated process models. Current efforts either use LLM-as-a-judge approaches or do not consider established dimensions of model quality. To this end, we introduce BEF4LLM, a novel LLM evaluation framework comprising four perspectives: syntactic quality, pragmatic quality, semantic quality, and validity. Using BEF4LLM, we conduct a comprehensive analysis of open-source LLMs and benchmark their performance against human modeling experts. Results indicate that LLMs excel in syntactic and pragmatic quality, while humans outperform in semantic aspects; however, the differences in scores are relatively modest, highlighting LLMs' competitive potential despite challenges in validity and semantic quality. The insights highlight current strengths and limitations of using LLMs for BPMN modeling and guide future model development and fine-tuning. Addressing these areas is essential for advancing the practical deployment of LLMs in business process modeling.
From Theory to Practice: Real-World Use Cases on Trustworthy LLM-Driven Process Modeling, Prediction and Automation
Jun 04, 2025Traditional Business Process Management (BPM) struggles with rigidity, opacity, and scalability in dynamic environments while emerging Large Language Models (LLMs) present transformative opportunities alongside risks. This paper explores four real-world use cases that demonstrate how LLMs, augmented with trustworthy process intelligence, redefine process modeling, prediction, and automation. Grounded in early-stage research projects with industrial partners, the work spans manufacturing, modeling, life-science, and design processes, addressing domain-specific challenges through human-AI collaboration. In manufacturing, an LLM-driven framework integrates uncertainty-aware explainable Machine Learning (ML) with interactive dialogues, transforming opaque predictions into auditable workflows. For process modeling, conversational interfaces democratize BPMN design. Pharmacovigilance agents automate drug safety monitoring via knowledge-graph-augmented LLMs. Finally, sustainable textile design employs multi-agent systems to navigate regulatory and environmental trade-offs. We intend to examine tensions between transparency and efficiency, generalization and specialization, and human agency versus automation. By mapping these trade-offs, we advocate for context-sensitive integration prioritizing domain needs, stakeholder values, and iterative human-in-the-loop workflows over universal solutions. This work provides actionable insights for researchers and practitioners aiming to operationalize LLMs in critical BPM environments.
A Discussion on Generalization in Next-Activity Prediction
Sep 18, 2023



Next activity prediction aims to forecast the future behavior of running process instances. Recent publications in this field predominantly employ deep learning techniques and evaluate their prediction performance using publicly available event logs. This paper presents empirical evidence that calls into question the effectiveness of these current evaluation approaches. We show that there is an enormous amount of example leakage in all of the commonly used event logs, so that rather trivial prediction approaches perform almost as well as ones that leverage deep learning. We further argue that designing robust evaluations requires a more profound conceptual engagement with the topic of next-activity prediction, and specifically with the notion of generalization to new data. To this end, we present various prediction scenarios that necessitate different types of generalization to guide future research.
Multivariate Business Process Representation Learning utilizing Gramian Angular Fields and Convolutional Neural Networks
Jun 15, 2021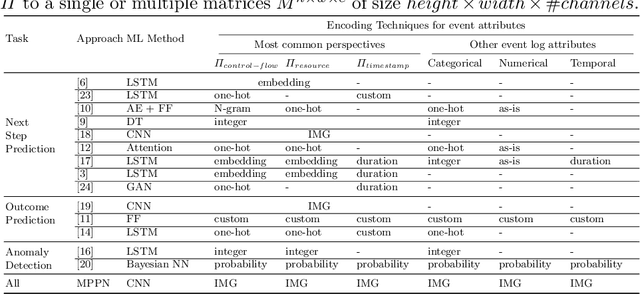
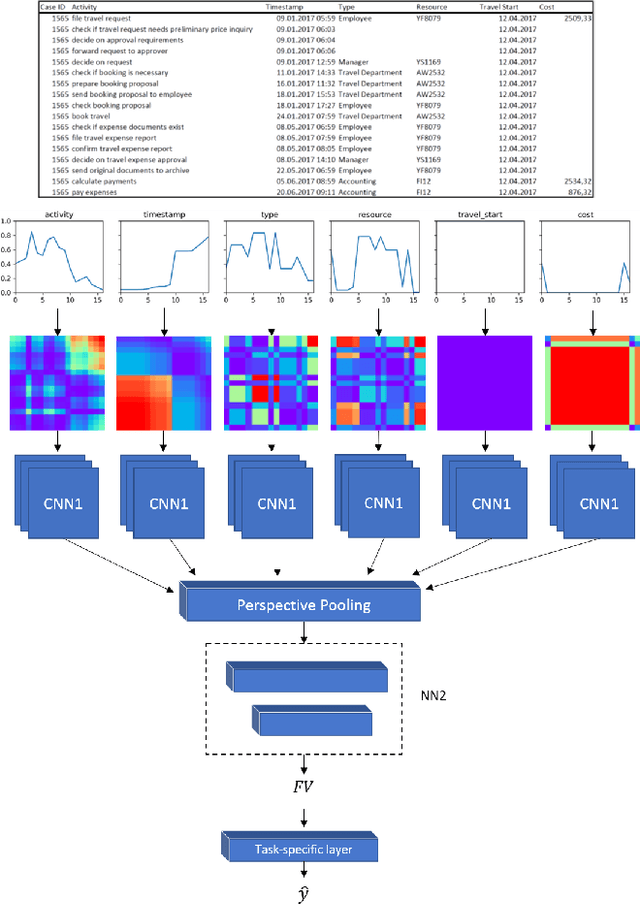
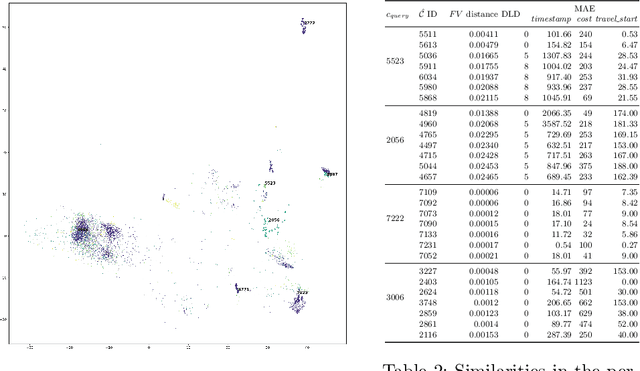
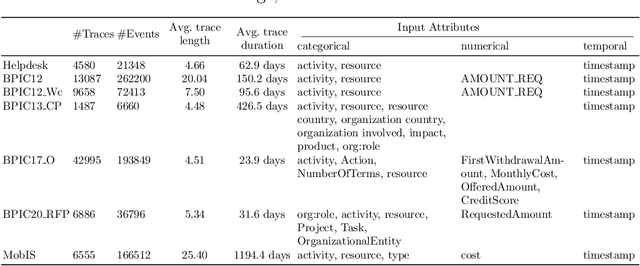
Learning meaningful representations of data is an important aspect of machine learning and has recently been successfully applied to many domains like language understanding or computer vision. Instead of training a model for one specific task, representation learning is about training a model to capture all useful information in the underlying data and make it accessible for a predictor. For predictive process analytics, it is essential to have all explanatory characteristics of a process instance available when making predictions about the future, as well as for clustering and anomaly detection. Due to the large variety of perspectives and types within business process data, generating a good representation is a challenging task. In this paper, we propose a novel approach for representation learning of business process instances which can process and combine most perspectives in an event log. In conjunction with a self-supervised pre-training method, we show the capabilities of the approach through a visualization of the representation space and case retrieval. Furthermore, the pre-trained model is fine-tuned to multiple process prediction tasks and demonstrates its effectiveness in comparison with existing approaches.