 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-VTON: Context-Driven Image-Based Virtual Try-On Network
Dec 08, 2022



Image-based virtual try-on techniques have shown great promise for enhancing the user-experience and improving customer satisfaction on fashion-oriented e-commerce platforms. However, existing techniques are currently still limited in the quality of the try-on results they are able to produce from input images of diverse characteristics. In this work, we propose a Context-Driven Virtual Try-On Network (C-VTON) that addresses these limitations and convincingly transfers selected clothing items to the target subjects even under challenging pose configurations and in the presence of self-occlusions. At the core of the C-VTON pipeline are: (i) a geometric matching procedure that efficiently aligns the target clothing with the pose of the person in the input images, and (ii) a powerful image generator that utilizes various types of contextual information when synthesizing the final try-on result. C-VTON is evaluated in rigorous experiments on the VITON and MPV datasets and in comparison to state-of-the-art techniques from the literature. Experimental results show that the proposed approach is able to produce photo-realistic and visually convincing results and significantly improves on the existing state-of-the-art.
FaceQAN: Face Image Quality Assessment Through Adversarial Noise Exploration
Dec 05, 2022



Recent state-of-the-art face recognition (FR) approaches have achieved impressive performance, yet unconstrained face recognition still represents an open problem. Face image quality assessment (FIQA) approaches aim to estimate the quality of the input samples that can help provide information on the confidence of the recognition decision and eventually lead to improved results in challenging scenarios. While much progress has been made in face image quality assessment in recent years, computing reliable quality scores for diverse facial images and FR models remains challenging. In this paper, we propose a novel approach to face image quality assessment, called FaceQAN, that is based on adversarial examples and relies on the analysis of adversarial noise which can be calculated with any FR model learned by using some form of gradient descent. As such, the proposed approach is the first to link image quality to adversarial attacks. Comprehensive (cross-model as well as model-specific) experiments are conducted with four benchmark datasets, i.e., LFW, CFP-FP, XQLFW and IJB-C, four FR models, i.e., CosFace, ArcFace, CurricularFace and ElasticFace, and in comparison to seven state-of-the-art FIQA methods to demonstrate the performance of FaceQAN. Experimental results show that FaceQAN achieves competitive results, while exhibiting several desirable characteristics.
PrivacyProber: Assessment and Detection of Soft-Biometric Privacy-Enhancing Techniques
Nov 22, 2022Soft-biometric privacy-enhancing techniques represent machine learning methods that aim to: (i) mitigate privacy concerns associated with face recognition technology by suppressing selected soft-biometric attributes in facial images (e.g., gender, age, ethnicity) and (ii) make unsolicited extraction of sensitive personal information infeasible. Because such techniques are increasingly used in real-world applications, it is imperative to understand to what extent the privacy enhancement can be inverted and how much attribute information can be recovered from privacy-enhanced images. While these aspects are critical, they have not been investigated in the literature. We, therefore, study the robustness of several state-of-the-art soft-biometric privacy-enhancing techniques to attribute recovery attempts. We propose PrivacyProber, a high-level framework for restoring soft-biometric information from privacy-enhanced facial images, and apply it for attribute recovery in comprehensive experiments on three public face datasets, i.e., LFW, MUCT and Adience. Our experiments show that the proposed framework is able to restore a considerable amount of suppressed information, regardless of the privacy-enhancing technique used, but also that there are significant differences between the considered privacy models. These results point to the need for novel mechanisms that can improve the robustness of existing privacy-enhancing techniques and secure them against potential adversaries trying to restore suppressed information.
SeeABLE: Soft Discrepancies and Bounded Contrastive Learning for Exposing Deepfakes
Nov 21, 2022Modern deepfake detectors have achieved encouraging results, when training and test images are drawn from the same collection. However, when applying these detectors to faces manipulated using an unknown technique, considerable performance drops are typically observed. In this work, we propose a novel deepfake detector, called SeeABLE, that formalizes the detection problem as a (one-class) out-of-distribution detection task and generalizes better to unseen deepfakes. Specifically, SeeABLE uses a novel data augmentation strategy to synthesize fine-grained local image anomalies (referred to as soft-discrepancies) and pushes those pristine disrupted faces towards predefined prototypes using a novel regression-based bounded contrastive loss. To strengthen the generalization performance of SeeABLE to unknown deepfake types, we generate a rich set of soft discrepancies and train the detector: (i) to localize, which part of the face was modified, and (ii) to identify the alteration type. Using extensive experiments on widely used datasets, SeeABLE considerably outperforms existing detectors, with gains of up to +10\% on the DFDC-preview dataset in term of detection accuracy over SoTA methods while using a simpler model. Code will be made publicly available.
GlassesGAN: Eyewear Personalization using Synthetic Appearance Discovery and Targeted Subspace Modeling
Oct 24, 2022



We present GlassesGAN, a novel image editing framework for custom design of glasses, that sets a new standard in terms of image quality, edit realism, and continuous multi-style edit capability. To facilitate the editing process with GlassesGAN, we propose a Targeted Subspace Modelling (TSM) procedure that, based on a novel mechanism for (synthetic) appearance discovery in the latent space of a pre-trained GAN generator, constructs an eyeglasses-specific (latent) subspace that the editing framework can utilize. To improve the reliability of our learned edits, we also introduce an appearance-constrained subspace initialization (SI) technique able to center the latent representation of a given input image in the well-defined part of the constructed subspace. We test GlassesGAN on three diverse datasets (CelebA-HQ, SiblingsDB-HQf, and MetFaces) and compare it against three state-of-the-art competitors, i.e., InterfaceGAN, GANSpace, and MaskGAN. Our experimental results show that GlassesGAN achieves photo-realistic, multi-style edits to eyeglasses while comparing favorably to its competitors. The source code is made freely available.
Hierarchical Superquadric Decomposition with Implicit Space Separation
Sep 15, 2022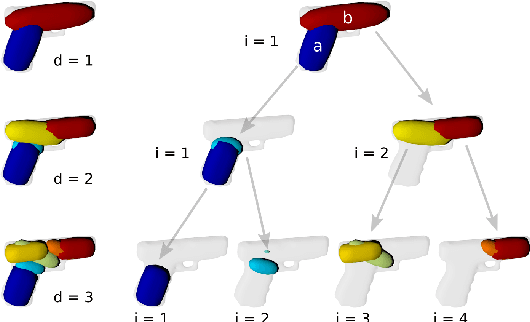
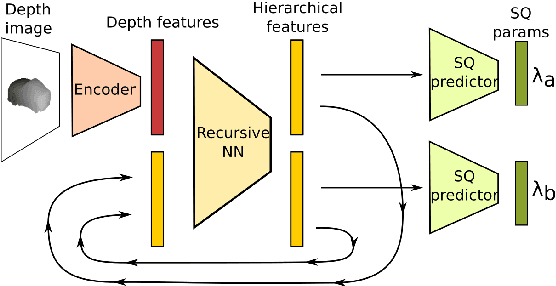
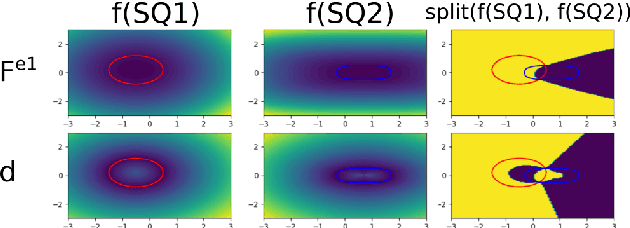
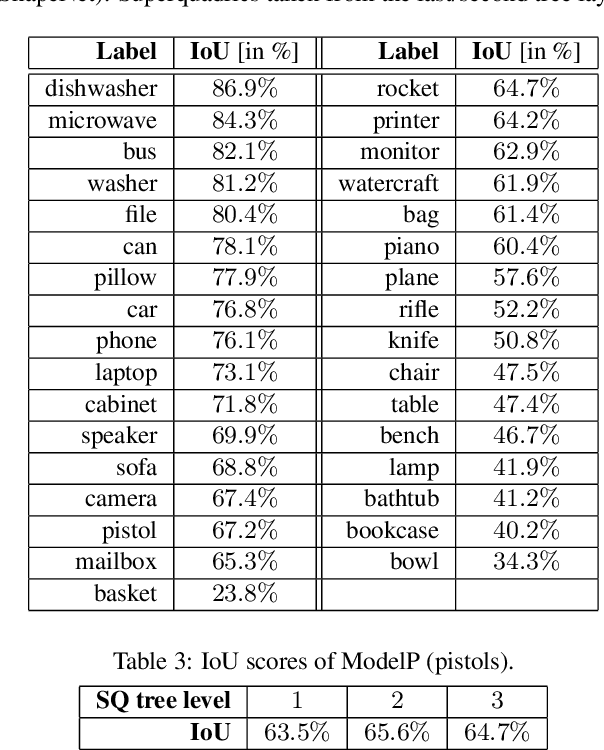
We introduce a new method to reconstruct 3D objects using a set of volumetric primitives, i.e., superquadrics. The method hierarchically decomposes a target 3D object into pairs of superquadrics recovering finer and finer details. While such hierarchical methods have been studied before, we introduce a new way of splitting the object space using only properties of the predicted superquadrics. The method is trained and evaluated on the ShapeNet dataset. The results of our experiments suggest that reasonable reconstructions can be obtained with the proposed approach for a diverse set of objects with complex geometry.
SYN-MAD 2022: Competition on Face Morphing Attack Detection Based on Privacy-aware Synthetic Training Data
Aug 15, 2022
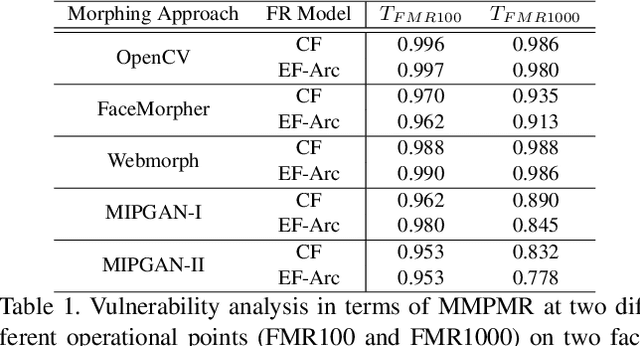
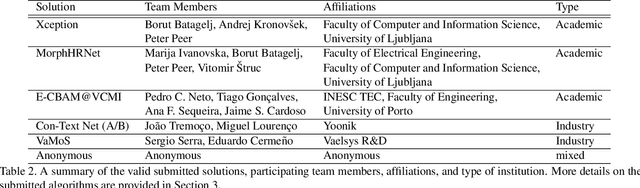
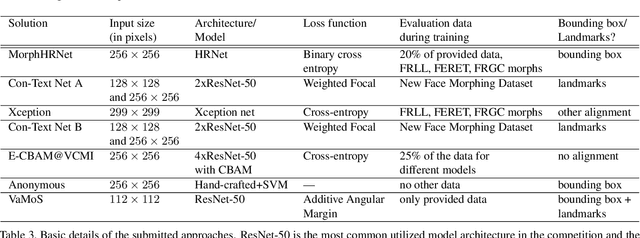
This paper presents a summary of the Competition on Face Morphing Attack Detection Based on Privacy-aware Synthetic Training Data (SYN-MAD) held at the 2022 International Joint Conference on Biometrics (IJCB 2022). The competition attracted a total of 12 participating teams, both from academia and industry and present in 11 different countries. In the end, seven valid submissions were submitted by the participating teams and evaluated by the organizers. The competition was held to present and attract solutions that deal with detecting face morphing attacks while protecting people's privacy for ethical and legal reasons. To ensure this, the training data was limited to synthetic data provided by the organizers. The submitted solutions presented innovations that led to outperforming the considered baseline in many experimental settings. The evaluation benchmark is now available at: https://github.com/marcohuber/SYN-MAD-2022.
Face Morphing Attack Detection Using Privacy-Aware Training Data
Jul 02, 2022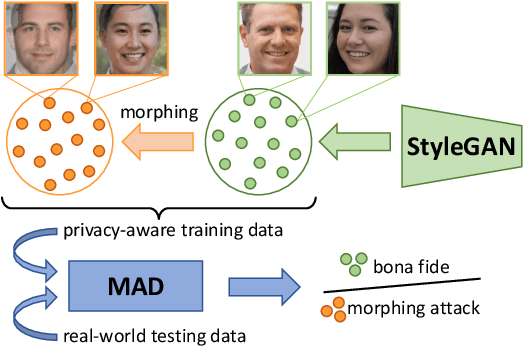


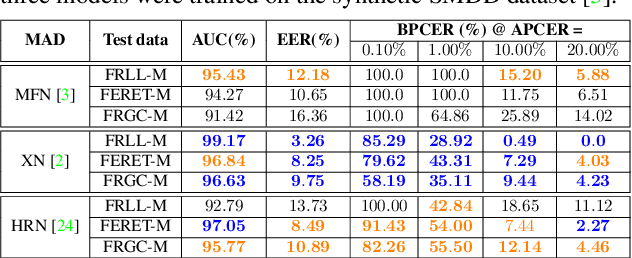
Images of morphed faces pose a serious threat to face recognition--based security systems, as they can be used to illegally verify the identity of multiple people with a single morphed image. Modern detection algorithms learn to identify such morphing attacks using authentic images of real individuals. This approach raises various privacy concerns and limits the amount of publicly available training data. In this paper, we explore the efficacy of detection algorithms that are trained only on faces of non--existing people and their respective morphs. To this end, two dedicated algorithms are trained with synthetic data and then evaluated on three real-world datasets, i.e.: FRLL-Morphs, FERET-Morphs and FRGC-Morphs. Our results show that synthetic facial images can be successfully employed for the training process of the detection algorithms and generalize well to real-world scenarios.
BiOcularGAN: Bimodal Synthesis and Annotation of Ocular Images
May 03, 2022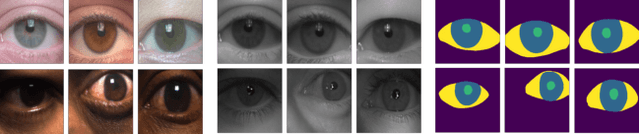
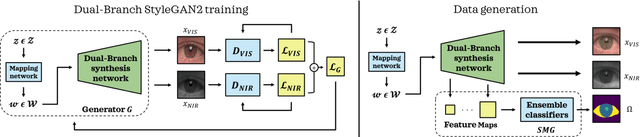
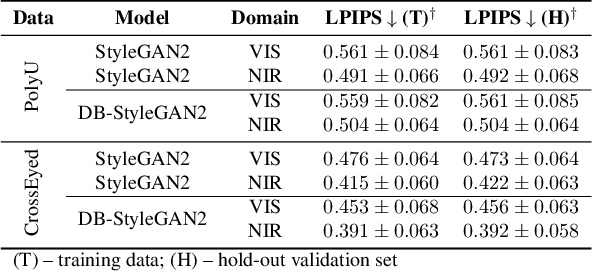
Current state-of-the-art segmentation techniques for ocular images are critically dependent on large-scale annotated datasets, which are labor-intensive to gather and often raise privacy concerns. In this paper, we present a novel framework, called BiOcularGAN, capable of generating synthetic large-scale datasets of photorealistic (visible light and near infrared) ocular images, together with corresponding segmentation labels to address these issues. At its core, the framework relies on a novel Dual-Branch StyleGAN2 (DB-StyleGAN2) model that facilitates bimodal image generation, and a Semantic Mask Generator (SMG) that produces semantic annotations by exploiting DB-StyleGAN2's feature space. We evaluate BiOcularGAN through extensive experiments across five diverse ocular datasets and analyze the effects of bimodal data generation on image quality and the produced annotations. Our experimental results show that BiOcularGAN is able to produce high-quality matching bimodal images and annotations (with minimal manual intervention) that can be used to train highly competitive (deep) segmentation models that perform well across multiple real-world datasets. The source code will be made publicly available.
Segmentation and Recovery of Superquadric Models using Convolutional Neural Networks
Jan 28, 2020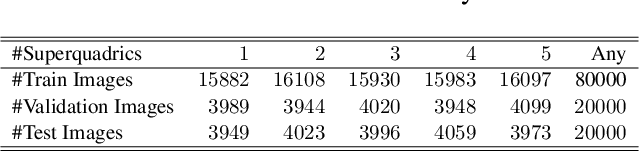

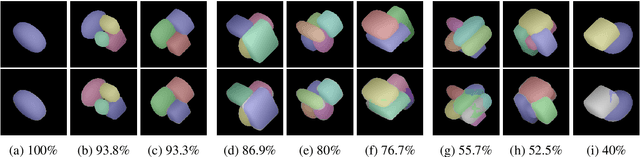
In this paper we address the problem of representing 3D visual data with parameterized volumetric shape primitives. Specifically, we present a (two-stage) approach built around convolutional neural networks (CNNs) capable of segmenting complex depth scenes into the simpler geometric structures that can be represented with superquadric models. In the first stage, our approach uses a Mask RCNN model to identify superquadric-like structures in depth scenes and then fits superquadric models to the segmented structures using a specially designed CNN regressor. Using our approach we are able to describe complex structures with a small number of interpretable parameters. We evaluated the proposed approach on synthetic as well as real-world depth data and show that our solution does not only result in competitive performance in comparison to the state-of-the-art, but is able to decompose scenes into a number of superquadric models at a fraction of the time required by competing approaches. We make all data and models used in the paper available from https://lmi.fe.uni-lj.si/en/research/resources/sq-seg.