 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

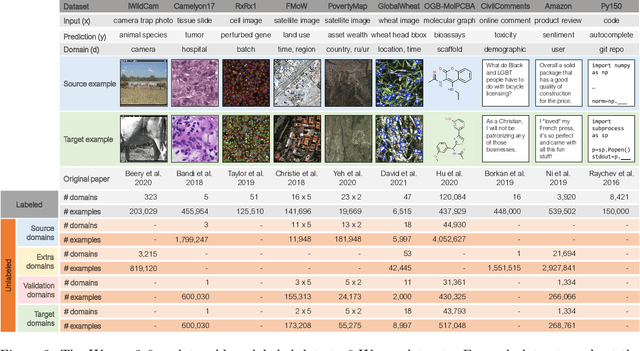
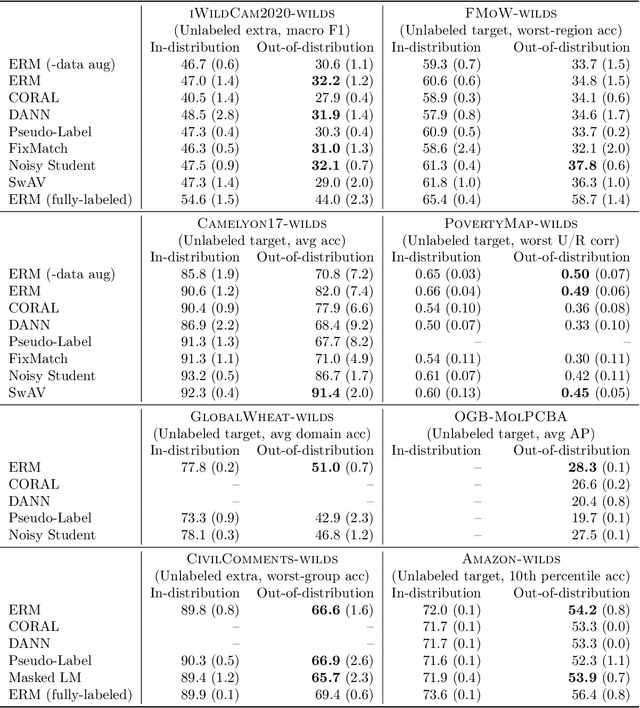
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.
An Explanation of In-context Learning as Implicit Bayesian Inference
Nov 14, 2021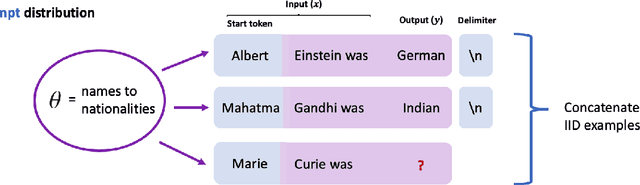
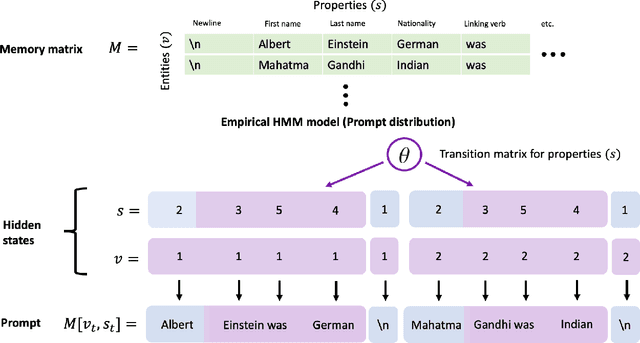
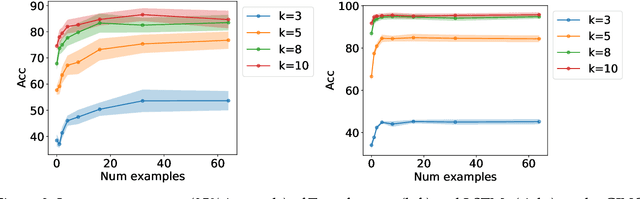

Large pretrained language models such as GPT-3 have the surprising ability to do in-context learning, where the model learns to do a downstream task simply by conditioning on a prompt consisting of input-output examples. Without being explicitly pretrained to do so, the language model learns from these examples during its forward pass without parameter updates on "out-of-distribution" prompts. Thus, it is unclear what mechanism enables in-context learning. In this paper, we study the role of the pretraining distribution on the emergence of in-context learning under a mathematical setting where the pretraining texts have long-range coherence. Here, language model pretraining requires inferring a latent document-level concept from the conditioning text to generate coherent next tokens. At test time, this mechanism enables in-context learning by inferring the shared latent concept between prompt examples and applying it to make a prediction on the test example. Concretely, we prove that in-context learning occurs implicitly via Bayesian inference of the latent concept when the pretraining distribution is a mixture of HMMs. This can occur despite the distribution mismatch between prompts and pretraining data. In contrast to messy large-scale pretraining datasets for in-context learning in natural language, we generate a family of small-scale synthetic datasets (GINC) where Transformer and LSTM language models both exhibit in-context learning. Beyond the theory which focuses on the effect of the pretraining distribution, we empirically find that scaling model size improves in-context accuracy even when the pretraining loss is the same.
LILA: Language-Informed Latent Actions
Nov 05, 2021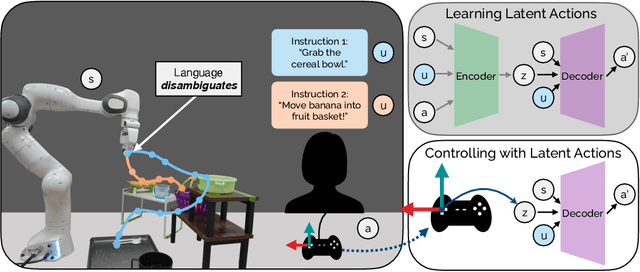
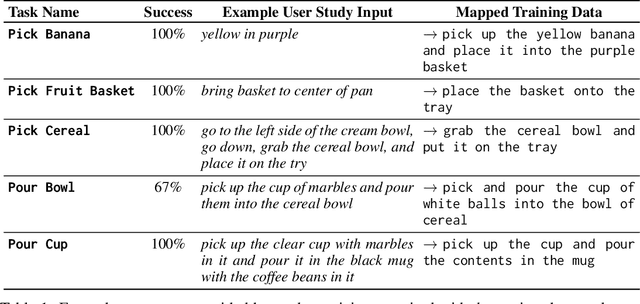
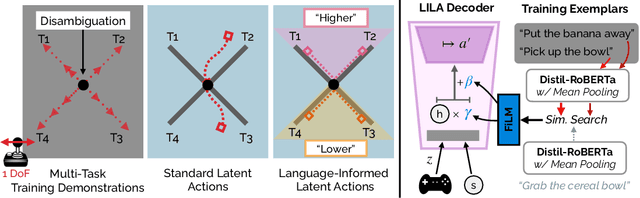
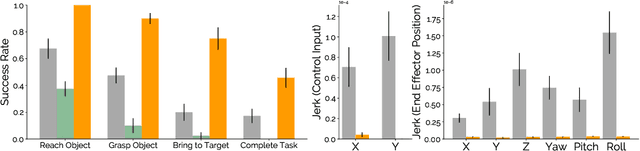
We introduce Language-Informed Latent Actions (LILA), a framework for learning natural language interfaces in the context of human-robot collaboration. LILA falls under the shared autonomy paradigm: in addition to providing discrete language inputs, humans are given a low-dimensional controller $-$ e.g., a 2 degree-of-freedom (DoF) joystick that can move left/right and up/down $-$ for operating the robot. LILA learns to use language to modulate this controller, providing users with a language-informed control space: given an instruction like "place the cereal bowl on the tray," LILA may learn a 2-DoF space where one dimension controls the distance from the robot's end-effector to the bowl, and the other dimension controls the robot's end-effector pose relative to the grasp point on the bowl. We evaluate LILA with real-world user studies, where users can provide a language instruction while operating a 7-DoF Franka Emika Panda Arm to complete a series of complex manipulation tasks. We show that LILA models are not only more sample efficient and performant than imitation learning and end-effector control baselines, but that they are also qualitatively preferred by users.
Large Language Models Can Be Strong Differentially Private Learners
Oct 12, 2021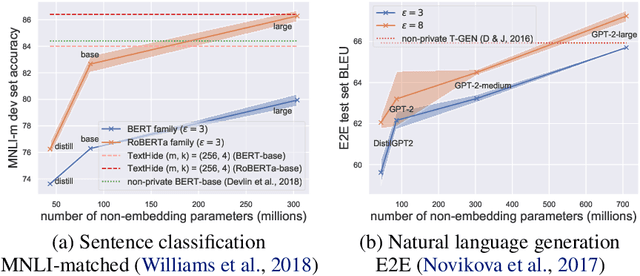
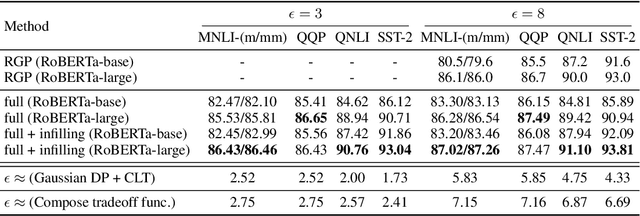
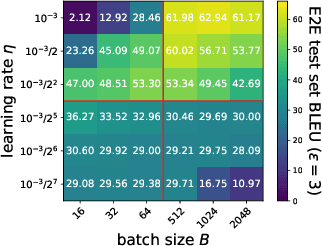
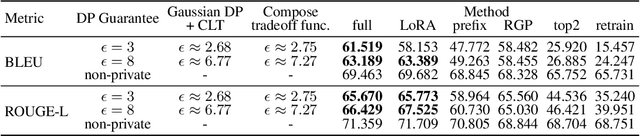
Differentially Private (DP) learning has seen limited success for building large deep learning models of text, and attempts at straightforwardly applying Differentially Private Stochastic Gradient Descent (DP-SGD) to NLP tasks have resulted in large performance drops and high computational overhead. We show that this performance drop can be mitigated with (1) the use of large pretrained models; (2) hyperparameters that suit DP optimization; and (3) fine-tuning objectives aligned with the pretraining procedure. With these factors set right, we obtain private NLP models that outperform state-of-the-art private training approaches and strong non-private baselines -- by directly fine-tuning pretrained models with DP optimization on moderately-sized corpora. To address the computational challenge of running DP-SGD with large Transformers, we propose a memory saving technique that allows clipping in DP-SGD to run without instantiating per-example gradients for any layer in the model. The technique enables privately training Transformers with almost the same memory cost as non-private training at a modest run-time overhead. Contrary to conventional wisdom that DP optimization fails at learning high-dimensional models (due to noise that scales with dimension) empirical results reveal that private learning with pretrained models tends to not suffer from dimension-dependent performance degradation.
Conditional probing: measuring usable information beyond a baseline
Sep 19, 2021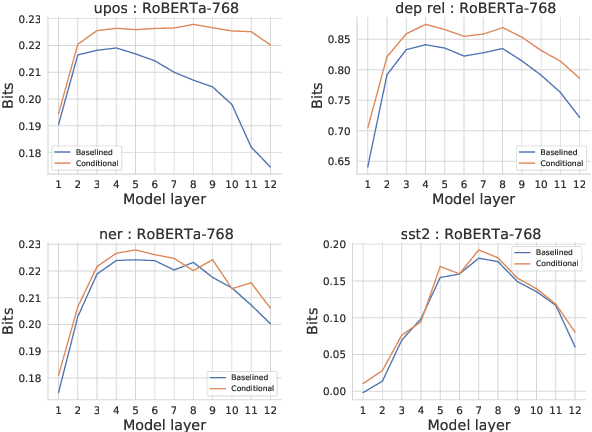
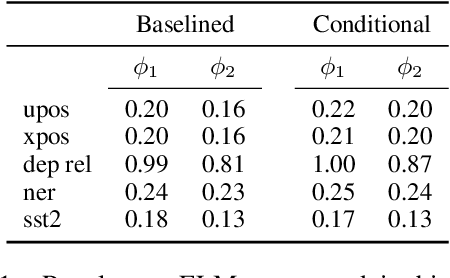
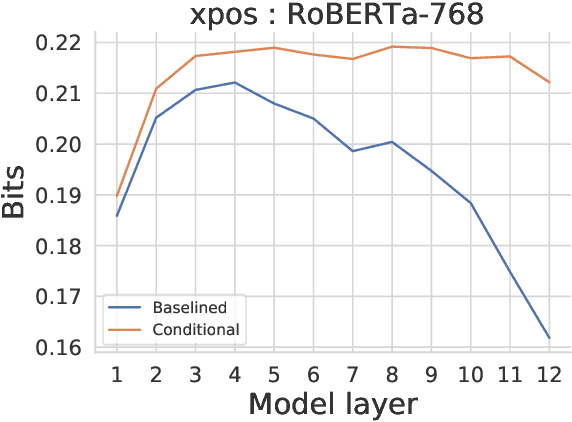
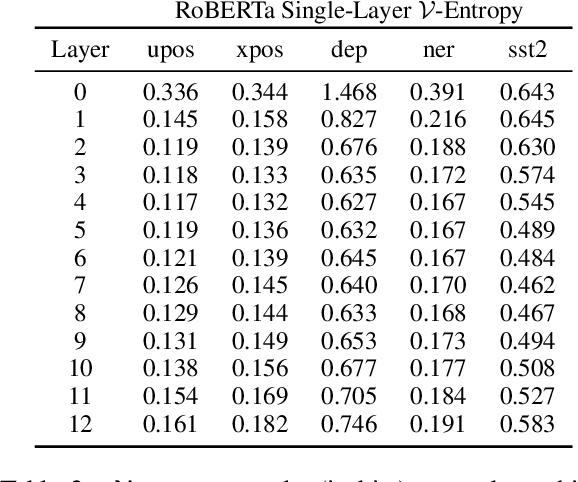
Probing experiments investigate the extent to which neural representations make properties -- like part-of-speech -- predictable. One suggests that a representation encodes a property if probing that representation produces higher accuracy than probing a baseline representation like non-contextual word embeddings. Instead of using baselines as a point of comparison, we're interested in measuring information that is contained in the representation but not in the baseline. For example, current methods can detect when a representation is more useful than the word identity (a baseline) for predicting part-of-speech; however, they cannot detect when the representation is predictive of just the aspects of part-of-speech not explainable by the word identity. In this work, we extend a theory of usable information called $\mathcal{V}$-information and propose conditional probing, which explicitly conditions on the information in the baseline. In a case study, we find that after conditioning on non-contextual word embeddings, properties like part-of-speech are accessible at deeper layers of a network than previously thought.
LM-Critic: Language Models for Unsupervised Grammatical Error Correction
Sep 14, 2021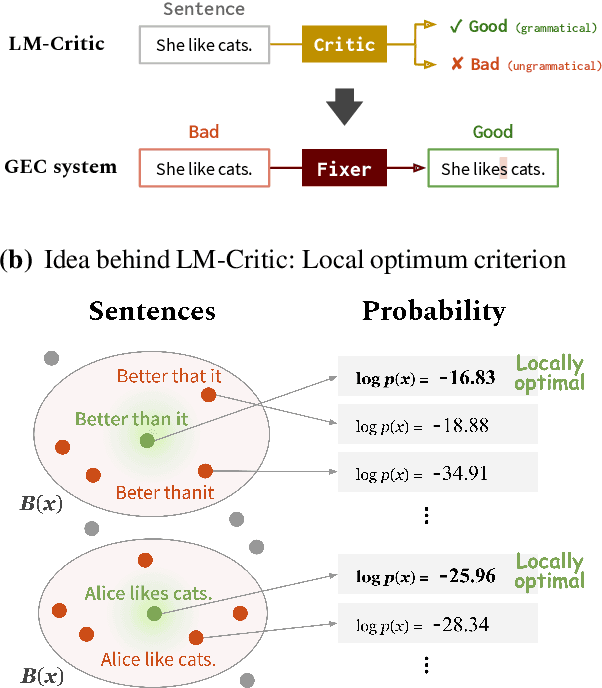
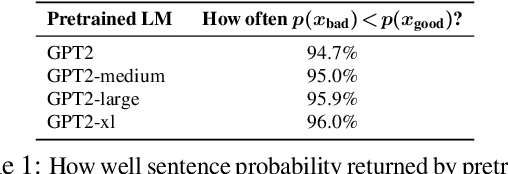
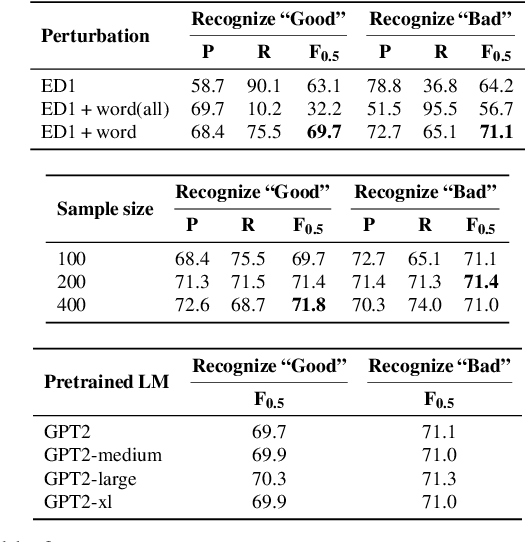
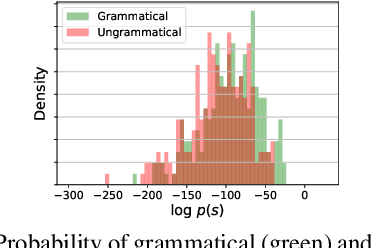
Training a model for grammatical error correction (GEC) requires a set of labeled ungrammatical / grammatical sentence pairs, but manually annotating such pairs can be expensive. Recently, the Break-It-Fix-It (BIFI) framework has demonstrated strong results on learning to repair a broken program without any labeled examples, but this relies on a perfect critic (e.g., a compiler) that returns whether an example is valid or not, which does not exist for the GEC task. In this work, we show how to leverage a pretrained language model (LM) in defining an LM-Critic, which judges a sentence to be grammatical if the LM assigns it a higher probability than its local perturbations. We apply this LM-Critic and BIFI along with a large set of unlabeled sentences to bootstrap realistic ungrammatical / grammatical pairs for training a corrector. We evaluate our approach on GEC datasets across multiple domains (CoNLL-2014, BEA-2019, GMEG-wiki and GMEG-yahoo) and show that it outperforms existing methods in both the unsupervised setting (+7.7 F0.5) and the supervised setting (+0.5 F0.5).
No True State-of-the-Art? OOD Detection Methods are Inconsistent across Datasets
Sep 12, 2021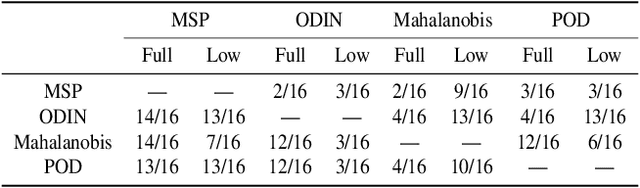
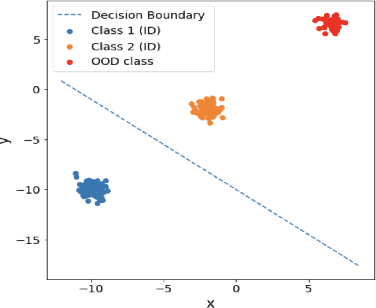
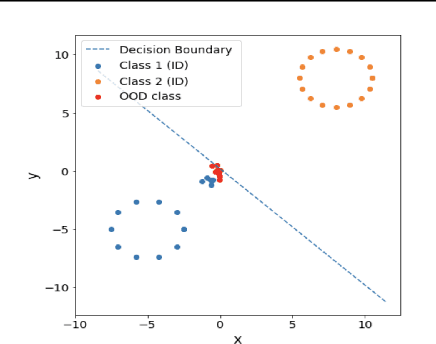
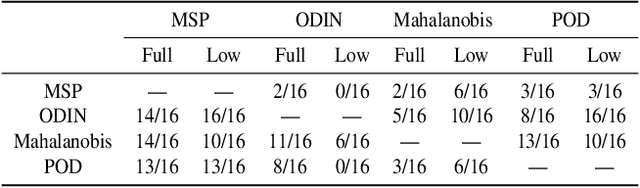
Out-of-distribution detection is an important component of reliable ML systems. Prior literature has proposed various methods (e.g., MSP (Hendrycks & Gimpel, 2017), ODIN (Liang et al., 2018), Mahalanobis (Lee et al., 2018)), claiming they are state-of-the-art by showing they outperform previous methods on a selected set of in-distribution (ID) and out-of-distribution (OOD) datasets. In this work, we show that none of these methods are inherently better at OOD detection than others on a standardized set of 16 (ID, OOD) pairs. We give possible explanations for these inconsistencies with simple toy datasets where whether one method outperforms another depends on the structure of the ID and OOD datasets in question. Finally, we show that a method outperforming another on a certain (ID, OOD) pair may not do so in a low-data regime. In the low-data regime, we propose a distance-based method, Pairwise OOD detection (POD), which is based on Siamese networks and improves over Mahalanobis by sidestepping the expensive covariance estimation step. Our results suggest that the OOD detection problem may be too broad, and we should consider more specific structures for leverage.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Just Train Twice: Improving Group Robustness without Training Group Information
Jul 19, 2021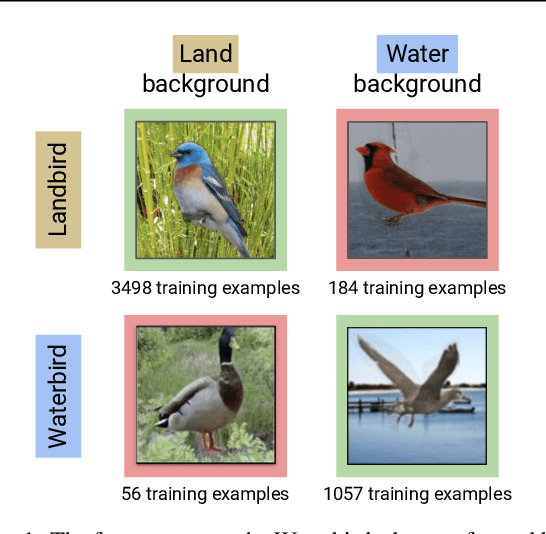
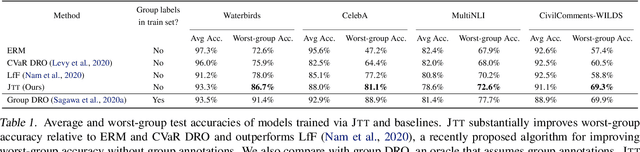

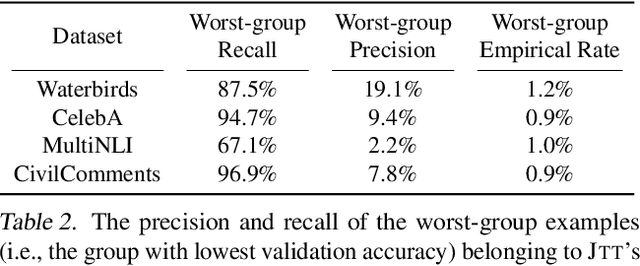
Standard training via empirical risk minimization (ERM) can produce models that achieve high accuracy on average but low accuracy on certain groups, especially in the presence of spurious correlations between the input and label. Prior approaches that achieve high worst-group accuracy, like group distributionally robust optimization (group DRO) require expensive group annotations for each training point, whereas approaches that do not use such group annotations typically achieve unsatisfactory worst-group accuracy. In this paper, we propose a simple two-stage approach, JTT, that first trains a standard ERM model for several epochs, and then trains a second model that upweights the training examples that the first model misclassified. Intuitively, this upweights examples from groups on which standard ERM models perform poorly, leading to improved worst-group performance. Averaged over four image classification and natural language processing tasks with spurious correlations, JTT closes 75% of the gap in worst-group accuracy between standard ERM and group DRO, while only requiring group annotations on a small validation set in order to tune hyperparameters.
Codified audio language modeling learns useful representations for music information retrieval
Jul 12, 2021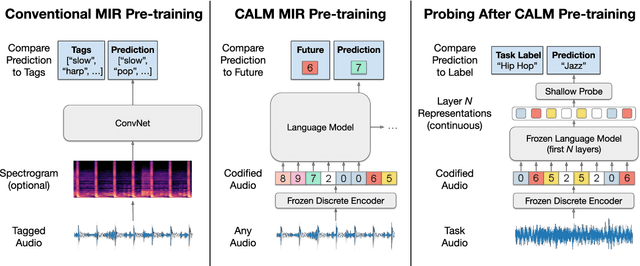
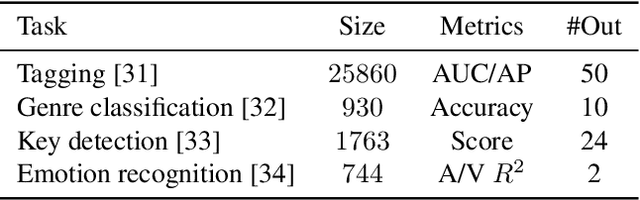
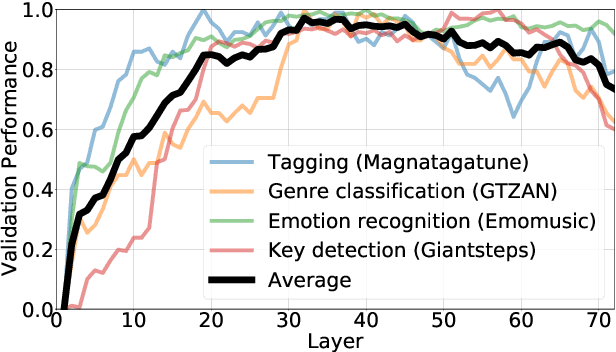

We demonstrate that language models pre-trained on codified (discretely-encoded) music audio learn representations that are useful for downstream MIR tasks. Specifically, we explore representations from Jukebox (Dhariwal et al. 2020): a music generation system containing a language model trained on codified audio from 1M songs. To determine if Jukebox's representations contain useful information for MIR, we use them as input features to train shallow models on several MIR tasks. Relative to representations from conventional MIR models which are pre-trained on tagging, we find that using representations from Jukebox as input features yields 30% stronger performance on average across four MIR tasks: tagging, genre classification, emotion recognition, and key detection. For key detection, we observe that representations from Jukebox are considerably stronger than those from models pre-trained on tagging, suggesting that pre-training via codified audio language modeling may address blind spots in conventional approaches. We interpret the strength of Jukebox's representations as evidence that modeling audio instead of tags provides richer representations for MIR.