 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Regularization for Text Classification
Mar 24, 2021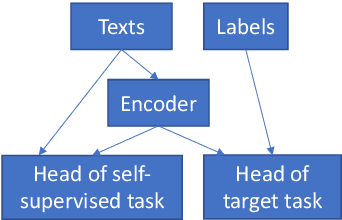

Text classification is a widely studied problem and has broad applications. In many real-world problems, the number of texts for training classification models is limited, which renders these models prone to overfitting. To address this problem, we propose SSL-Reg, a data-dependent regularization approach based on self-supervised learning (SSL). SSL is an unsupervised learning approach which defines auxiliary tasks on input data without using any human-provided labels and learns data representations by solving these auxiliary tasks. In SSL-Reg, a supervised classification task and an unsupervised SSL task are performed simultaneously. The SSL task is unsupervised, which is defined purely on input texts without using any human-provided labels. Training a model using an SSL task can prevent the model from being overfitted to a limited number of class labels in the classification task. Experiments on 17 text classification datasets demonstrate the effectiveness of our proposed method.
Interleaving Learning, with Application to Neural Architecture Search
Mar 12, 2021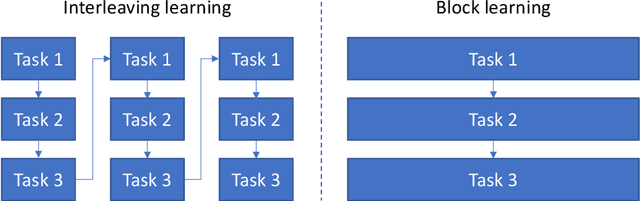

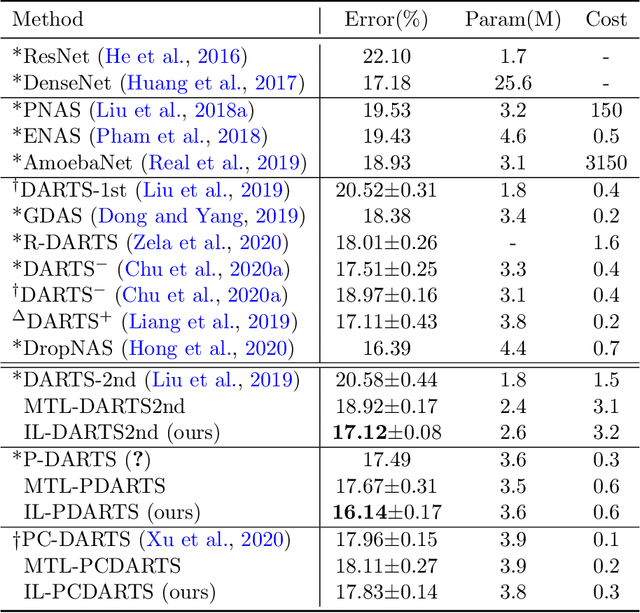
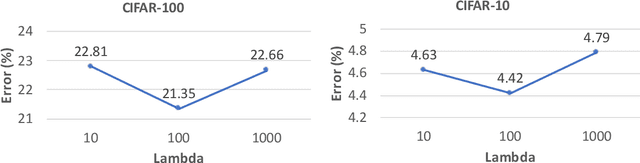
Interleaving learning is a human learning technique where a learner interleaves the studies of multiple topics, which increases long-term retention and improves ability to transfer learned knowledge. Inspired by the interleaving learning technique of humans, in this paper we explore whether this learning methodology is beneficial for improving the performance of machine learning models as well. We propose a novel machine learning framework referred to as interleaving learning (IL). In our framework, a set of models collaboratively learn a data encoder in an interleaving fashion: the encoder is trained by model 1 for a while, then passed to model 2 for further training, then model 3, and so on; after trained by all models, the encoder returns back to model 1 and is trained again, then moving to model 2, 3, etc. This process repeats for multiple rounds. Our framework is based on multi-level optimization consisting of multiple inter-connected learning stages. An efficient gradient-based algorithm is developed to solve the multi-level optimization problem. We apply interleaving learning to search neural architectures for image classification on CIFAR-10, CIFAR-100, and ImageNet. The effectiveness of our method is strongly demonstrated by the experimental results.
Learning by Teaching, with Application to Neural Architecture Search
Mar 11, 2021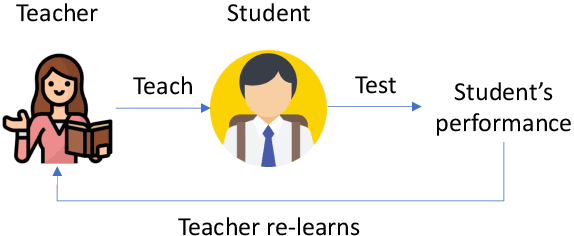

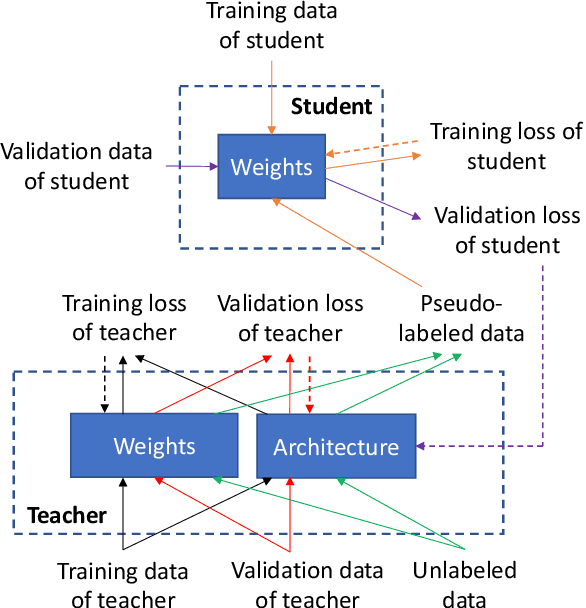
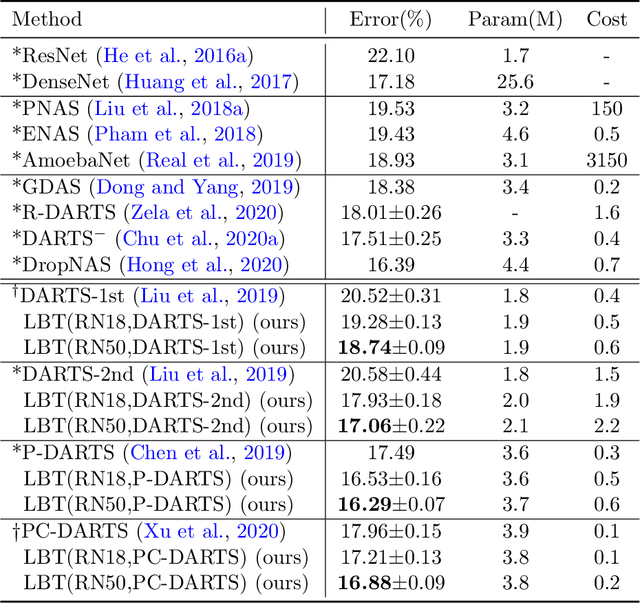
In human learning, an effective skill in improving learning outcomes is learning by teaching: a learner deepens his/her understanding of a topic by teaching this topic to others. In this paper, we aim to borrow this teaching-driven learning methodology from humans and leverage it to train more performant machine learning models, by proposing a novel ML framework referred to as learning by teaching (LBT). In the LBT framework, a teacher model improves itself by teaching a student model to learn well. Specifically, the teacher creates a pseudo-labeled dataset and uses it to train a student model. Based on how the student performs on a validation dataset, the teacher re-learns its model and re-teaches the student until the student achieves great validation performance. Our framework is based on three-level optimization which contains three stages: teacher learns; teacher teaches student; teacher re-learns based on how well the student performs. A simple but efficient algorithm is developed to solve the three-level optimization problem. We apply LBT to search neural architectures on CIFAR-10, CIFAR-100, and ImageNet. The efficacy of our method is demonstrated in various experiments.
Learning by Ignoring
Dec 28, 2020
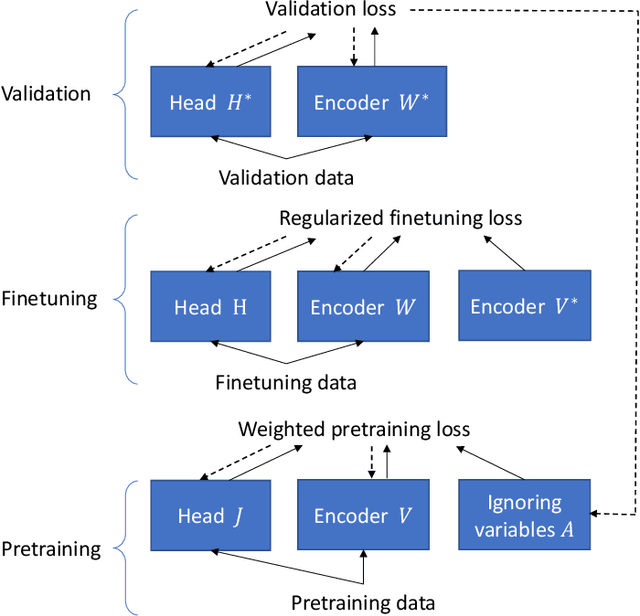
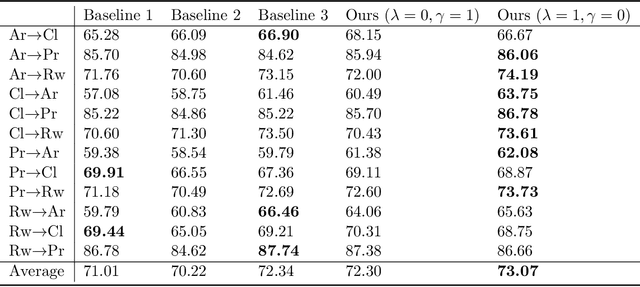
Learning by ignoring, which identifies less important things and excludes them from the learning process, is an effective learning technique in human learning. There has been psychological studies showing that learning to ignore certain things is a powerful tool for helping people focus. We are interested in investigating whether this powerful learning technique can be borrowed from humans to improve the learning abilities of machines. We propose a novel learning approach called learning by ignoring (LBI). Our approach automatically identifies pretraining data examples that have large domain shift from the target distribution by learning an ignoring variable for each example and excludes them from the pretraining process. We propose a three-level optimization framework to formulate LBI which involves three stages of learning: pretraining by minimizing the losses weighed by ignoring variables; finetuning; updating the ignoring variables by minimizing the validation loss. We develop an efficient algorithm to solve the LBI problem. Experiments on various datasets demonstrate the effectiveness of our method.
Learning by Self-Explanation, with Application to Neural Architecture Search
Dec 23, 2020



Learning by self-explanation, where students explain a learned topic to themselves for deepening their understanding of this topic, is a broadly used methodology in human learning and shows great effectiveness in improving learning outcome. We are interested in investigating whether this powerful learning technique can be borrowed from humans to improve the learning abilities of machines. We propose a novel learning approach called learning by self-explanation (LeaSE). In our approach, an explainer model improves its learning ability by trying to clearly explain to an audience model regarding how a prediction outcome is made. We propose a multi-level optimization framework to formulate LeaSE which involves four stages of learning: explainer learns; explainer explains; audience learns; explainer and audience validate themselves. We develop an efficient algorithm to solve the LeaSE problem. We apply our approach to neural architecture search on CIFAR-100, CIFAR-10, and ImageNet. The results demonstrate the effectiveness of our method.
Small-Group Learning, with Application to Neural Architecture Search
Dec 23, 2020



Small-group learning is a broadly used methodology in human learning and shows great effectiveness in improving learning outcomes: a small group of students work together towards the same learning objective, where they express their understanding of a topic to their peers, compare their ideas, and help each other to trouble-shoot problems. We are interested in investigating whether this powerful learning technique can be borrowed from humans to improve the learning abilities of machines. We propose a novel learning approach called small-group learning (SGL). In our approach, each learner uses its intermediately trained model to generate a pseudo-labeled dataset and re-trains its model using pseudo-labeled datasets generated by other learners. We propose a multi-level optimization framework to formulate SGL which involves three learning stages: learners train their network weights independently; learners train their network weights collaboratively via mutual pseudo-labeling; learners improve their architectures by minimizing validation losses. We develop an efficient algorithm to solve the SGL problem. We apply our approach to neural architecture search and achieve significant improvement on CIFAR-100, CIFAR-10, and ImageNet.
DSRNA: Differentiable Search of Robust Neural Architectures
Dec 11, 2020



In deep learning applications, the architectures of deep neural networks are crucial in achieving high accuracy. Many methods have been proposed to search for high-performance neural architectures automatically. However, these searched architectures are prone to adversarial attacks. A small perturbation of the input data can render the architecture to change prediction outcomes significantly. To address this problem, we propose methods to perform differentiable search of robust neural architectures. In our methods, two differentiable metrics are defined to measure architectures' robustness, based on certified lower bound and Jacobian norm bound. Then we search for robust architectures by maximizing the robustness metrics. Different from previous approaches which aim to improve architectures' robustness in an implicit way: performing adversarial training and injecting random noise, our methods explicitly and directly maximize robustness metrics to harvest robust architectures. On CIFAR-10, ImageNet, and MNIST, we perform game-based evaluation and verification-based evaluation on the robustness of our methods. The experimental results show that our methods 1) are more robust to various norm-bound attacks than several robust NAS baselines; 2) are more accurate than baselines when there are no attacks; 3) have significantly higher certified lower bounds than baselines.
Skillearn: Machine Learning Inspired by Humans' Learning Skills
Dec 09, 2020

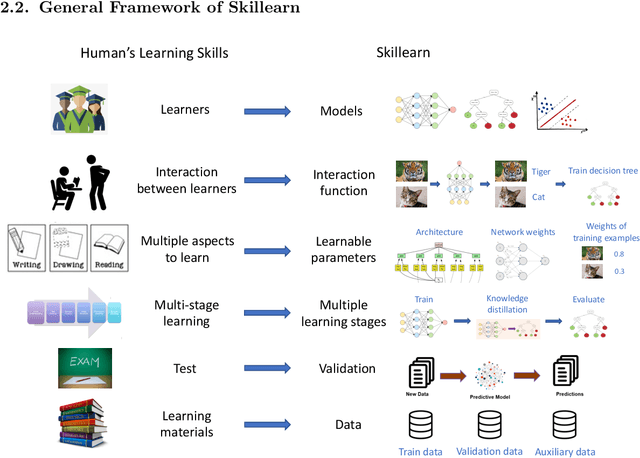

Humans, as the most powerful learners on the planet, have accumulated a lot of learning skills, such as learning through tests, interleaving learning, self-explanation, active recalling, to name a few. These learning skills and methodologies enable humans to learn new topics more effectively and efficiently. We are interested in investigating whether humans' learning skills can be borrowed to help machines to learn better. Specifically, we aim to formalize these skills and leverage them to train better machine learning (ML) models. To achieve this goal, we develop a general framework -- Skillearn, which provides a principled way to represent humans' learning skills mathematically and use the formally-represented skills to improve the training of ML models. In two case studies, we apply Skillearn to formalize two learning skills of humans: learning by passing tests and interleaving learning, and use the formalized skills to improve neural architecture search. Experiments on various datasets show that trained using the skills formalized by Skillearn, ML models achieve significantly better performance.
Learning by Passing Tests, with Application to Neural Architecture Search
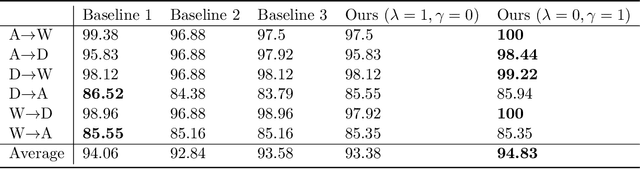
Nov 30, 2020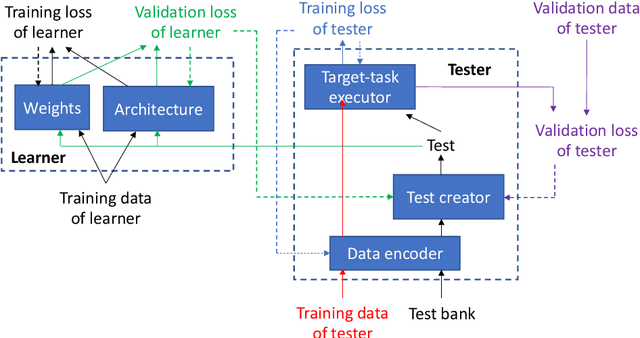

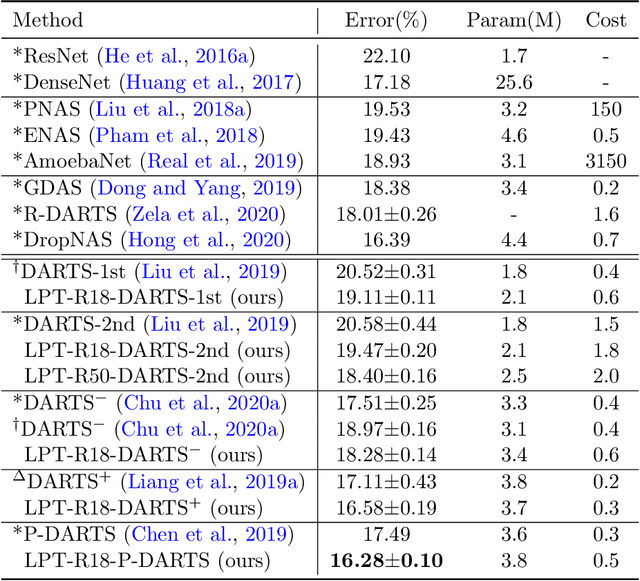
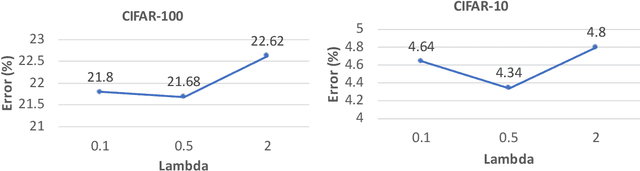
Learning through tests is a broadly used methodology in human learning and shows great effectiveness in improving learning outcome: a sequence of tests are made with increasing levels of difficulty; the learner takes these tests to identify his/her weak points in learning and continuously addresses these weak points to successfully pass these tests. We are interested in investigating whether this powerful learning technique can be borrowed from humans to improve the learning abilities of machines. We propose a novel learning approach called learning by passing tests (LPT). In our approach, a tester model creates increasingly more-difficult tests to evaluate a learner model. The learner tries to continuously improve its learning ability so that it can successfully pass however difficult tests created by the tester. We propose a multi-level optimization framework to formulate LPT, where the tester learns to create difficult and meaningful tests and the learner learns to pass these tests. We develop an efficient algorithm to solve the LCT problem. Our method is applied for neural architecture search and achieves significant improvement over state-of-the-art baselines on CIFAR-100, CIFAR-10, and ImageNet.
Discriminative Cross-Modal Data Augmentation for Medical Imaging Applications
Oct 07, 2020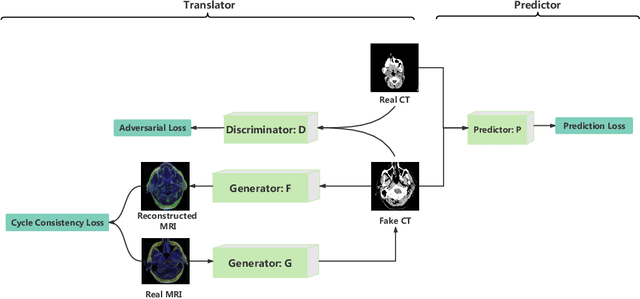
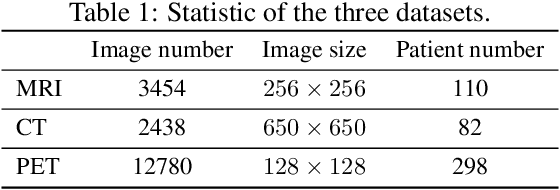

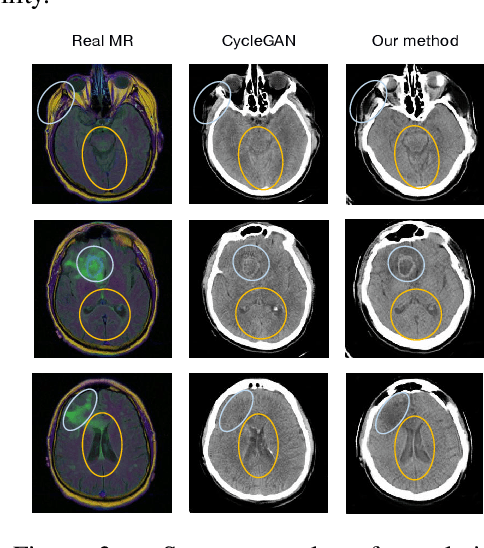
While deep learning methods have shown great success in medical image analysis, they require a number of medical images to train. Due to data privacy concerns and unavailability of medical annotators, it is oftentimes very difficult to obtain a lot of labeled medical images for model training. In this paper, we study cross-modality data augmentation to mitigate the data deficiency issue in the medical imaging domain. We propose a discriminative unpaired image-to-image translation model which translates images in source modality into images in target modality where the translation task is conducted jointly with the downstream prediction task and the translation is guided by the prediction. Experiments on two applications demonstrate the effectiveness of our method.