 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability without actionability: mechanistic methods cannot correct language model errors despite near-perfect internal representations
Mar 18, 2026Language models encode task-relevant knowledge in internal representations that far exceeds their output performance, but whether mechanistic interpretability methods can bridge this knowledge-action gap has not been systematically tested. We compared four mechanistic interpretability methods -- concept bottleneck steering (Steerling-8B), sparse autoencoder feature steering, logit lens with activation patching, and linear probing with truthfulness separator vector steering (Qwen 2.5 7B Instruct) -- for correcting false-negative triage errors using 400 physician-adjudicated clinical vignettes (144 hazards, 256 benign). Linear probes discriminated hazardous from benign cases with 98.2% AUROC, yet the model's output sensitivity was only 45.1%, a 53-percentage-point knowledge-action gap. Concept bottleneck steering corrected 20% of missed hazards but disrupted 53% of correct detections, indistinguishable from random perturbation (p=0.84). SAE feature steering produced zero effect despite 3,695 significant features. TSV steering at high strength corrected 24% of missed hazards while disrupting 6% of correct detections, but left 76% of errors uncorrected. Current mechanistic interpretability methods cannot reliably translate internal knowledge into corrected outputs, with implications for AI safety frameworks that assume interpretability enables effective error correction.
Feasibility-Guided Fair Adaptive Offline Reinforcement Learning for Medicaid Care Management
Sep 11, 2025We introduce Feasibility-Guided Fair Adaptive Reinforcement Learning (FG-FARL), an offline RL procedure that calibrates per-group safety thresholds to reduce harm while equalizing a chosen fairness target (coverage or harm) across protected subgroups. Using de-identified longitudinal trajectories from a Medicaid population health management program, we evaluate FG-FARL against behavior cloning (BC) and HACO (Hybrid Adaptive Conformal Offline RL; a global conformal safety baseline). We report off-policy value estimates with bootstrap 95% confidence intervals and subgroup disparity analyses with p-values. FG-FARL achieves comparable value to baselines while improving fairness metrics, demonstrating a practical path to safer and more equitable decision support.
Learning by Teaching, with Application to Neural Architecture Search
Mar 11, 2021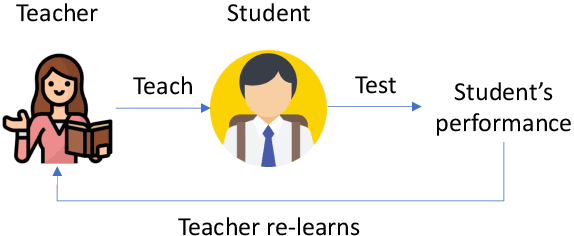

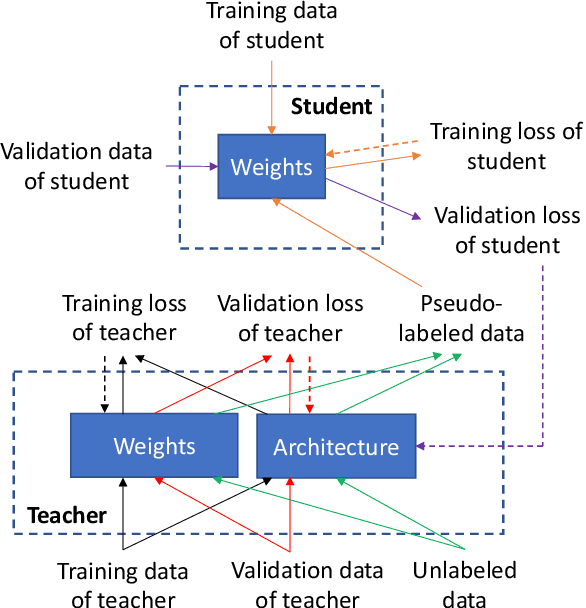
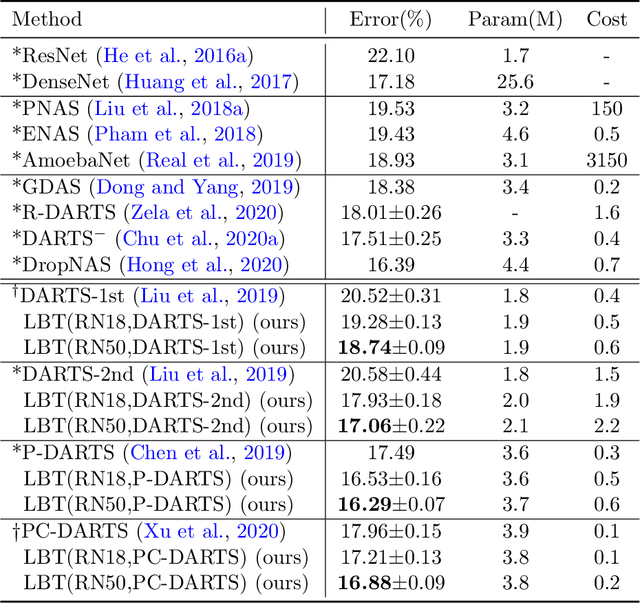
In human learning, an effective skill in improving learning outcomes is learning by teaching: a learner deepens his/her understanding of a topic by teaching this topic to others. In this paper, we aim to borrow this teaching-driven learning methodology from humans and leverage it to train more performant machine learning models, by proposing a novel ML framework referred to as learning by teaching (LBT). In the LBT framework, a teacher model improves itself by teaching a student model to learn well. Specifically, the teacher creates a pseudo-labeled dataset and uses it to train a student model. Based on how the student performs on a validation dataset, the teacher re-learns its model and re-teaches the student until the student achieves great validation performance. Our framework is based on three-level optimization which contains three stages: teacher learns; teacher teaches student; teacher re-learns based on how well the student performs. A simple but efficient algorithm is developed to solve the three-level optimization problem. We apply LBT to search neural architectures on CIFAR-10, CIFAR-100, and ImageNet. The efficacy of our method is demonstrated in various experiments.