 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnware of Language Models: Specialized Small Language Models Can Do Big
May 19, 2025The learnware paradigm offers a novel approach to machine learning by enabling users to reuse a set of well-trained models for tasks beyond the models' original purposes. It eliminates the need to build models from scratch, instead relying on specifications (representations of a model's capabilities) to identify and leverage the most suitable models for new tasks. While learnware has proven effective in many scenarios, its application to language models has remained largely unexplored. At the same time, large language models (LLMs) have demonstrated remarkable universal question-answering abilities, yet they face challenges in specialized scenarios due to data scarcity, privacy concerns, and high computational costs, thus more and more specialized small language models (SLMs) are being trained for specific domains. To address these limitations systematically, the learnware paradigm provides a promising solution by enabling maximum utilization of specialized SLMs, and allowing users to identify and reuse them in a collaborative and privacy-preserving manner. This paper presents a preliminary attempt to apply the learnware paradigm to language models. We simulated a learnware system comprising approximately 100 learnwares of specialized SLMs with 8B parameters, fine-tuned across finance, healthcare, and mathematics domains. Each learnware contains an SLM and a specification, which enables users to identify the most relevant models without exposing their own data. Experimental results demonstrate promising performance: by selecting one suitable learnware for each task-specific inference, the system outperforms the base SLMs on all benchmarks. Compared to LLMs, the system outperforms Qwen1.5-110B, Qwen2.5-72B, and Llama3.1-70B-Instruct by at least 14% in finance domain tasks, and surpasses Flan-PaLM-540B (ranked 7th on the Open Medical LLM Leaderboard) in medical domain tasks.
Beimingwu: A Learnware Dock System
Jan 24, 2024



The learnware paradigm proposed by Zhou [2016] aims to enable users to reuse numerous existing well-trained models instead of building machine learning models from scratch, with the hope of solving new user tasks even beyond models' original purposes. In this paradigm, developers worldwide can submit their high-performing models spontaneously to the learnware dock system (formerly known as learnware market) without revealing their training data. Once the dock system accepts the model, it assigns a specification and accommodates the model. This specification allows the model to be adequately identified and assembled to reuse according to future users' needs, even if they have no prior knowledge of the model. This paradigm greatly differs from the current big model direction and it is expected that a learnware dock system housing millions or more high-performing models could offer excellent capabilities for both planned tasks where big models are applicable; and unplanned, specialized, data-sensitive scenarios where big models are not present or applicable. This paper describes Beimingwu, the first open-source learnware dock system providing foundational support for future research of learnware paradigm.The system significantly streamlines the model development for new user tasks, thanks to its integrated architecture and engine design, extensive engineering implementations and optimizations, and the integration of various algorithms for learnware identification and reuse. Notably, this is possible even for users with limited data and minimal expertise in machine learning, without compromising the raw data's security. Beimingwu supports the entire process of learnware paradigm. The system lays the foundation for future research in learnware-related algorithms and systems, and prepares the ground for hosting a vast array of learnwares and establishing a learnware ecosystem.
Silicon Photonics in Optical Access Networks for 5G Communications
May 12, 2021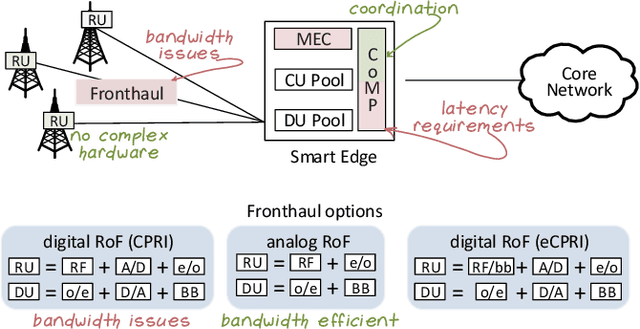
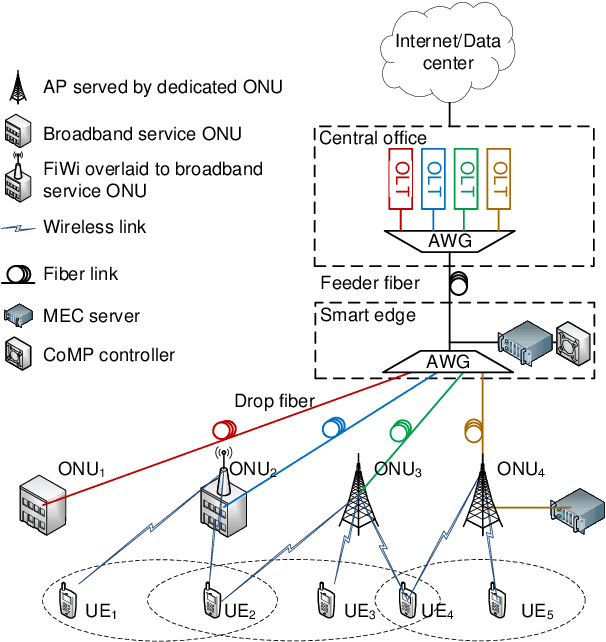
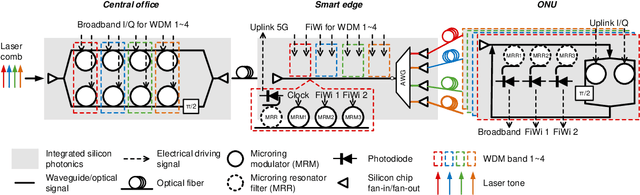
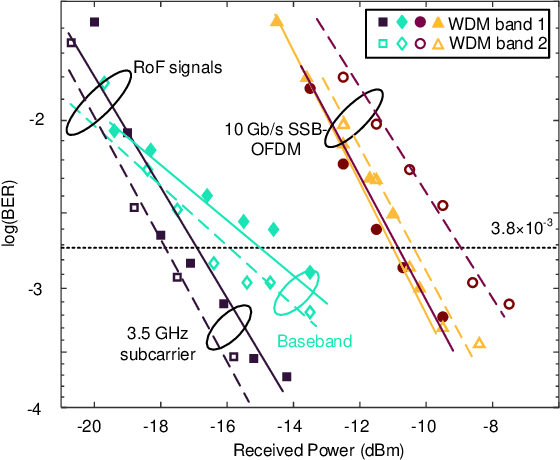
Only radio access networks can provide connectivity across multiple antenna sites to achieve the great leap forward in capacity targeted by 5G. Optical fronthaul remains a sticking point in that connectivity, and we make the case for analog radio over fiber signals and an optical access network smartedge to achieve the potential of radio access networks. The edge of the network would house the intelligence that coordinates wireless transmissions to minimize interference and maximize throughput. As silicon photonics provides a hardware platform well adapted to support optical fronthaul, it is poised to drive smart edge adoption. We draw out the issues in adopting oursolution, propose a strategy for network densification, and cite recent demonstrations to support our approach.