 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPNAS: Neural Architecture Search for Deep Learning with Differential Privacy
Oct 19, 2021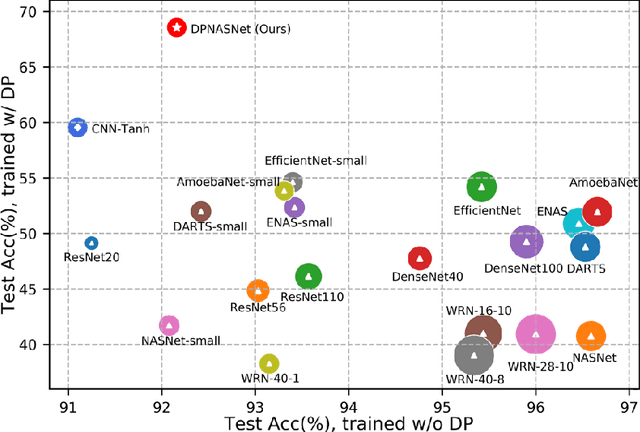
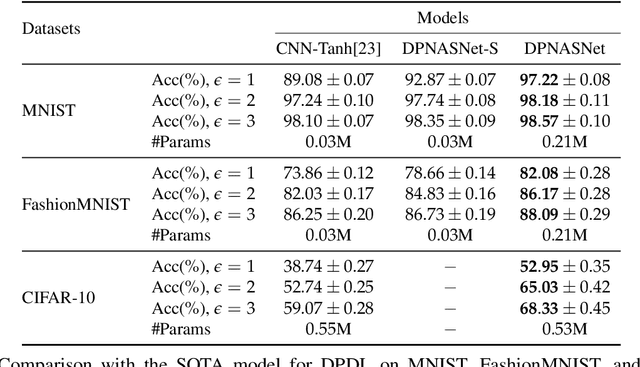
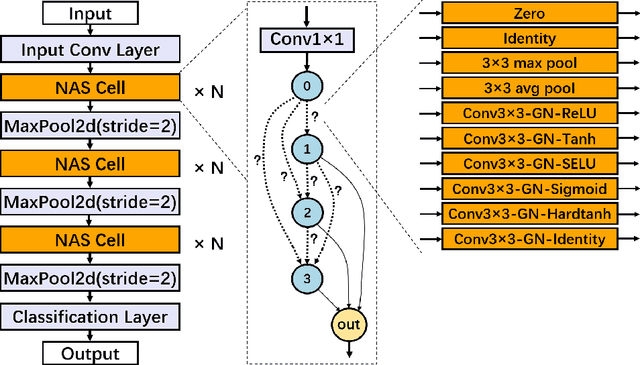
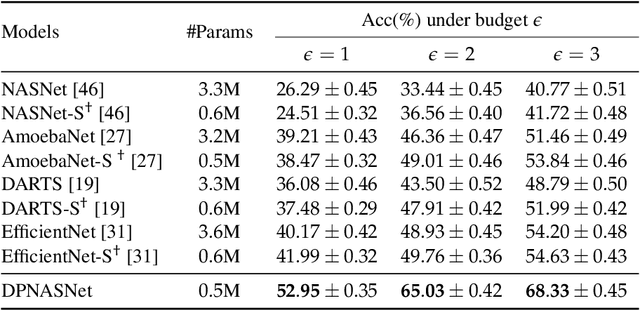
Training deep neural networks (DNNs) for meaningful differential privacy (DP) guarantees severely degrades model utility. In this paper, we demonstrate that the architecture of DNNs has a significant impact on model utility in the context of private deep learning, whereas its effect is largely unexplored in previous studies. In light of this missing, we propose the very first framework that employs neural architecture search to automatic model design for private deep learning, dubbed as DPNAS. To integrate private learning with architecture search, we delicately design a novel search space and propose a DP-aware method for training candidate models. We empirically certify the effectiveness of the proposed framework. The searched model DPNASNet achieves state-of-the-art privacy/utility trade-offs, e.g., for the privacy budget of $(\epsilon, \delta)=(3, 1\times10^{-5})$, our model obtains test accuracy of $98.57\%$ on MNIST, $88.09\%$ on FashionMNIST, and $68.33\%$ on CIFAR-10. Furthermore, by studying the generated architectures, we provide several intriguing findings of designing private-learning-friendly DNNs, which can shed new light on model design for deep learning with differential privacy.
Towards Mixed-Precision Quantization of Neural Networks via Constrained Optimization
Oct 13, 2021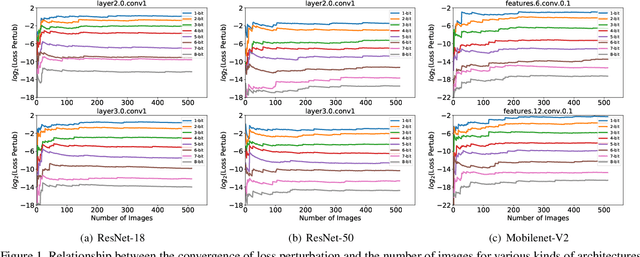
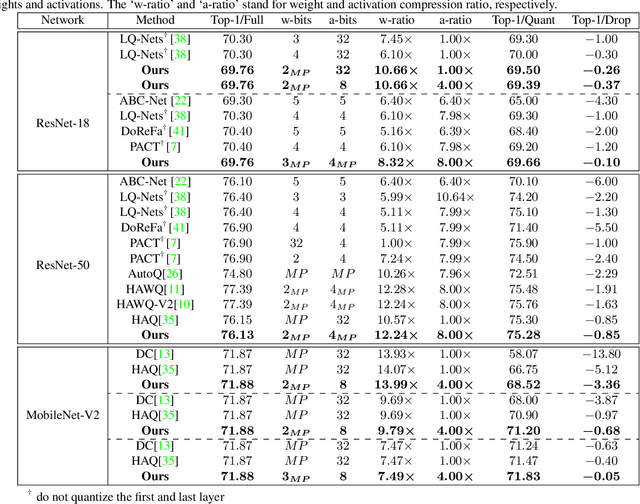
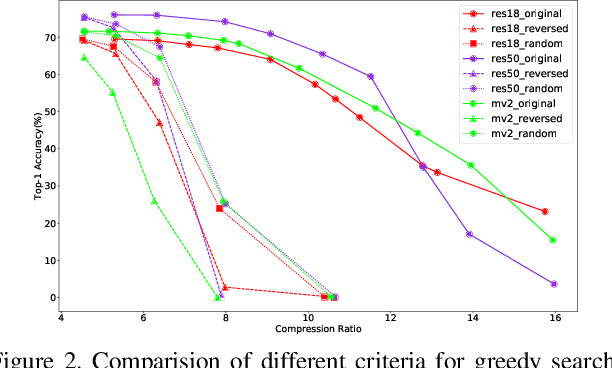
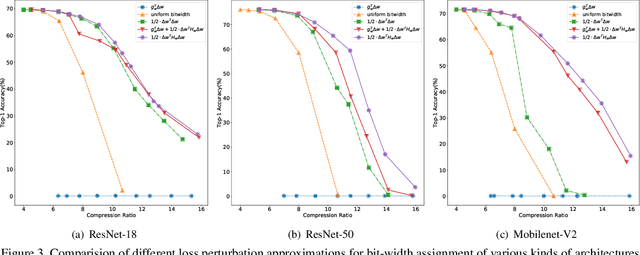
Quantization is a widely used technique to compress and accelerate deep neural networks. However, conventional quantization methods use the same bit-width for all (or most of) the layers, which often suffer significant accuracy degradation in the ultra-low precision regime and ignore the fact that emergent hardware accelerators begin to support mixed-precision computation. Consequently, we present a novel and principled framework to solve the mixed-precision quantization problem in this paper. Briefly speaking, we first formulate the mixed-precision quantization as a discrete constrained optimization problem. Then, to make the optimization tractable, we approximate the objective function with second-order Taylor expansion and propose an efficient approach to compute its Hessian matrix. Finally, based on the above simplification, we show that the original problem can be reformulated as a Multiple-Choice Knapsack Problem (MCKP) and propose a greedy search algorithm to solve it efficiently. Compared with existing mixed-precision quantization works, our method is derived in a principled way and much more computationally efficient. Moreover, extensive experiments conducted on the ImageNet dataset and various kinds of network architectures also demonstrate its superiority over existing uniform and mixed-precision quantization approaches.
Improving Binary Neural Networks through Fully Utilizing Latent Weights
Oct 12, 2021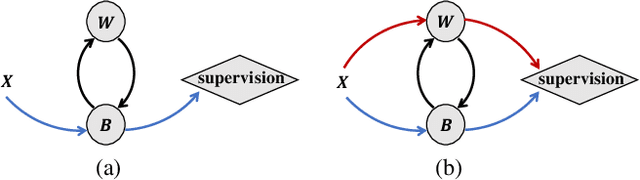

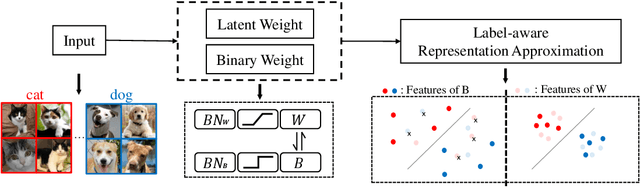
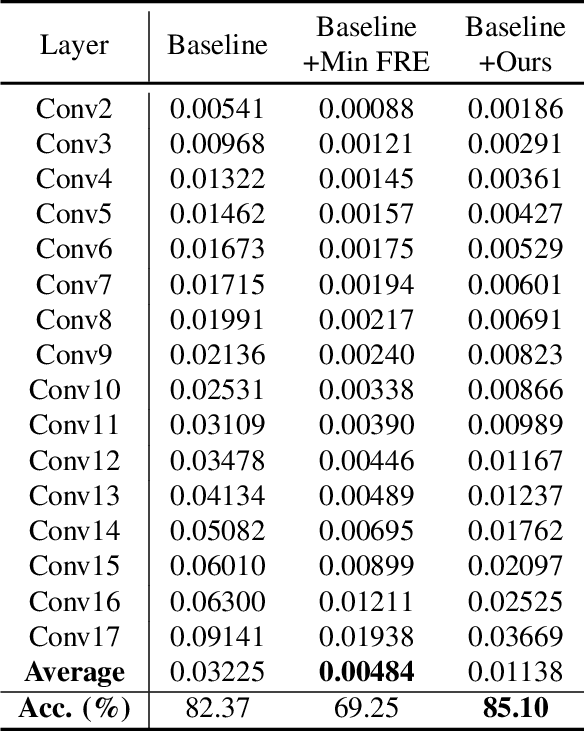
Binary Neural Networks (BNNs) rely on a real-valued auxiliary variable W to help binary training. However, pioneering binary works only use W to accumulate gradient updates during backward propagation, which can not fully exploit its power and may hinder novel advances in BNNs. In this work, we explore the role of W in training besides acting as a latent variable. Notably, we propose to add W into the computation graph, making it perform as a real-valued feature extractor to aid the binary training. We make different attempts on how to utilize the real-valued weights and propose a specialized supervision. Visualization experiments qualitatively verify the effectiveness of our approach in making it easier to distinguish between different categories. Quantitative experiments show that our approach outperforms current state-of-the-arts, further closing the performance gap between floating-point networks and BNNs. Evaluation on ImageNet with ResNet-18 (Top-1 63.4%), ResNet-34 (Top-1 67.0%) achieves new state-of-the-art.
Generative Zero-shot Network Quantization
Jan 21, 2021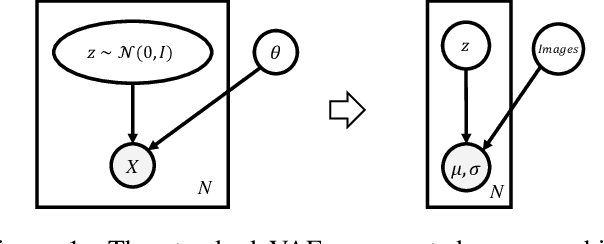
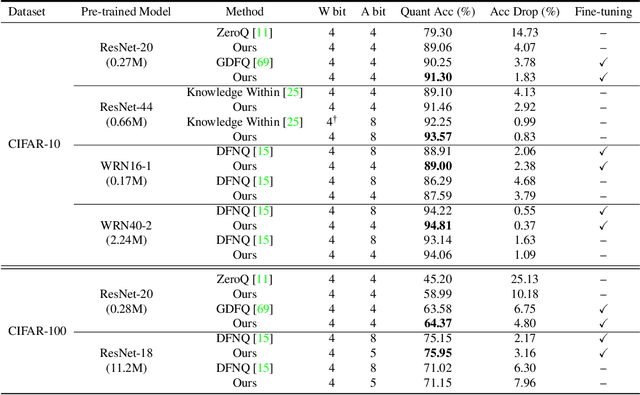
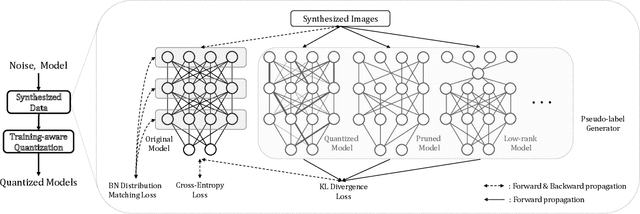
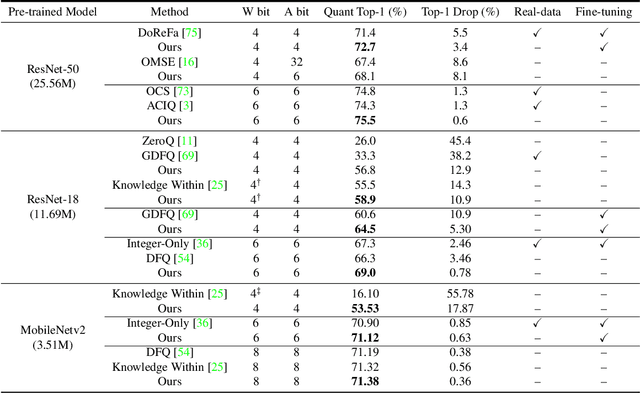
Convolutional neural networks are able to learn realistic image priors from numerous training samples in low-level image generation and restoration. We show that, for high-level image recognition tasks, we can further reconstruct "realistic" images of each category by leveraging intrinsic Batch Normalization (BN) statistics without any training data. Inspired by the popular VAE/GAN methods, we regard the zero-shot optimization process of synthetic images as generative modeling to match the distribution of BN statistics. The generated images serve as a calibration set for the following zero-shot network quantizations. Our method meets the needs for quantizing models based on sensitive information, \textit{e.g.,} due to privacy concerns, no data is available. Extensive experiments on benchmark datasets show that, with the help of generated data, our approach consistently outperforms existing data-free quantization methods.
SpatialFlow: Bridging All Tasks for Panoptic Segmentation
Dec 02, 2019
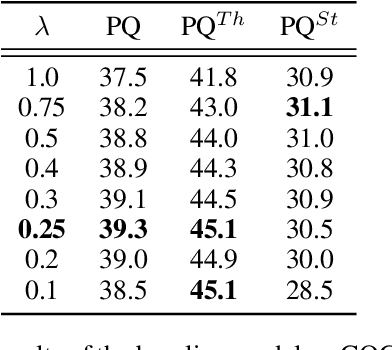
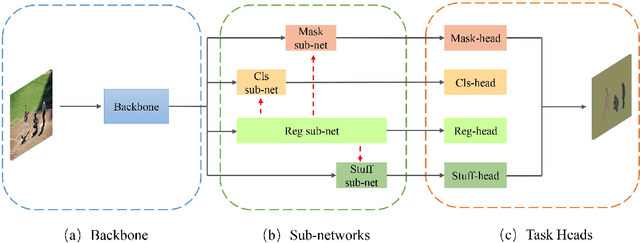
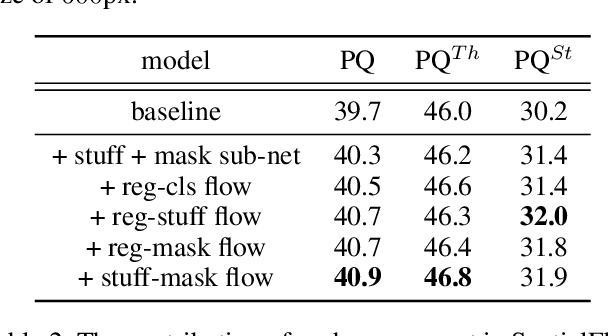
Object location is fundamental to panoptic segmentation as it is related to all things and stuff. How to integrate object location in both thing and stuff segmentation is a crucial problem. In this paper, we propose object spatial information flows to achieve this objective. More importantly, we design four parallel sub-networks for sub-tasks in panoptic segmentation, which leads to the preferable adaptation of object spatial information. With sub-networks, the flows can bridge all tasks together by delivering the object's spatial context from the box regression task to others. They can also provide clues for segmenting both things and stuff, which helps the network better understand the whole image. Upon the sub-networks and the flows, we present a location-aware and unified framework for panoptic segmentation, denoted as SpatialFlow. We perform a detailed ablation study on each component and conduct extensive experiments to prove the effectiveness of Our SpatialFlow. Furthermore, we achieve state-of-the-art results, which are $47.3$ PQ and $62.5$ PQ respectively on MS-COCO and Cityscapes panoptic benchmarks.
Location-aware Upsampling for Semantic Segmentation
Nov 14, 2019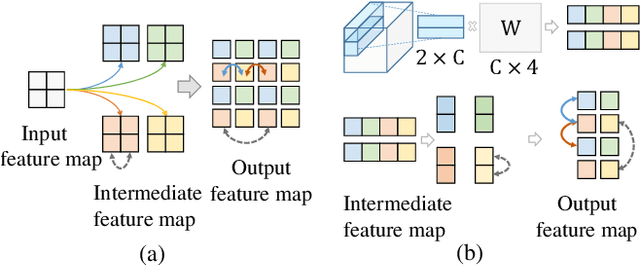
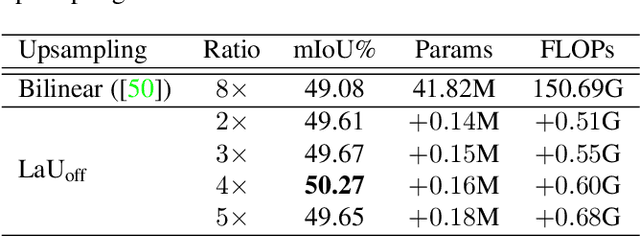
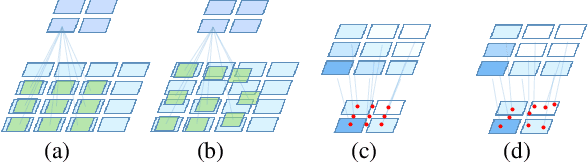

Many successful learning targets such as minimizing dice loss and cross-entropy loss have enabled unprecedented breakthroughs in segmentation tasks. Beyond these semantic metrics, this paper aims to introduce location supervision into semantic segmentation. Based on this idea, we present a Location-aware Upsampling (LaU) that adaptively refines the interpolating coordinates with trainable offsets. Then, location-aware losses are established by encouraging pixels to move towards well-classified locations. An LaU is offset prediction coupled with interpolation, which is trained end-to-end to generate confidence score at each position from coarse to fine. Guided by location-aware losses, the new module can replace its plain counterpart (\textit{e.g.}, bilinear upsampling) in a plug-and-play manner to further boost the leading encoder-decoder approaches. Extensive experiments validate the consistent improvement over the state-of-the-art methods on benchmark datasets. Our code is available at https://github.com/HolmesShuan/Location-aware-Upsampling-for-Semantic-Segmentation
A System-Level Solution for Low-Power Object Detection
Oct 19, 2019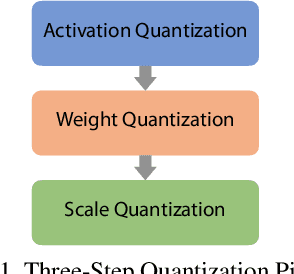
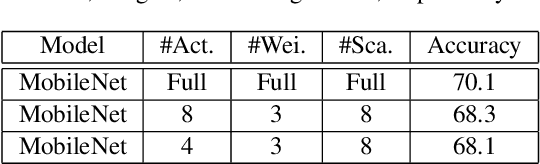
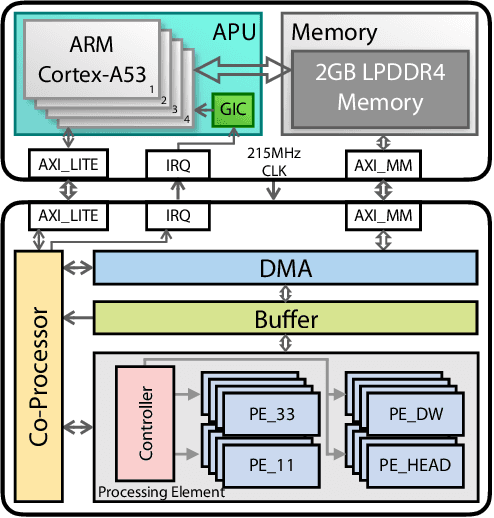

Object detection has made impressive progress in recent years with the help of deep learning. However, state-of-the-art algorithms are both computation and memory intensive. Though many lightweight networks are developed for a trade-off between accuracy and efficiency, it is still a challenge to make it practical on an embedded device. In this paper, we present a system-level solution for efficient object detection on a heterogeneous embedded device. The detection network is quantized to low bits and allows efficient implementation with shift operators. In order to make the most of the benefits of low-bit quantization, we design a dedicated accelerator with programmable logic. Inside the accelerator, a hybrid dataflow is exploited according to the heterogeneous property of different convolutional layers. We adopt a straightforward but resource-friendly column-prior tiling strategy to map the computation-intensive convolutional layers to the accelerator that can support arbitrary feature size. Other operations can be performed on the low-power CPU cores, and the entire system is executed in a pipelined manner. As a case study, we evaluate our object detection system on a real-world surveillance video with input size of 512x512, and it turns out that the system can achieve an inference speed of 18 fps at the cost of 6.9W (with display) with an mAP of 66.4 verified on the PASCAL VOC 2012 dataset.
Compact Global Descriptor for Neural Networks
Aug 01, 2019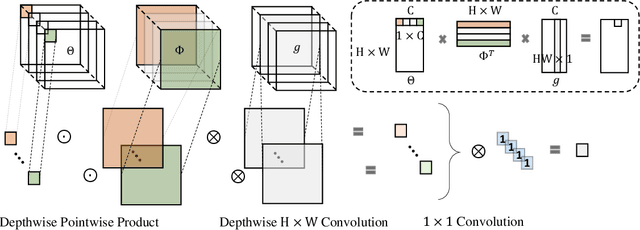

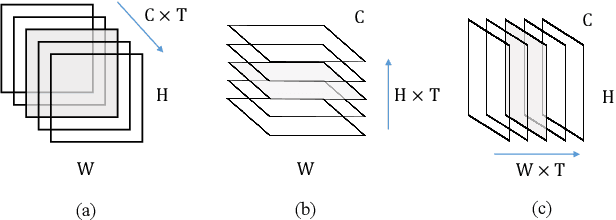

Long-range dependencies modeling, widely used in capturing spatiotemporal correlation, has shown to be effective in CNN dominated computer vision tasks. Yet neither stacks of convolutional operations to enlarge receptive fields nor recent nonlocal modules is computationally efficient. In this paper, we present a generic family of lightweight global descriptors for modeling the interactions between positions across different dimensions (e.g., channels, frames). This descriptor enables subsequent convolutions to access the informative global features with negligible computational complexity and parameters. Benchmark experiments show that the proposed method can complete state-of-the-art long-range mechanisms with a significant reduction in extra computing cost. Code available at https://github.com/HolmesShuan/Compact-Global-Descriptor.
Recent Advances in Efficient Computation of Deep Convolutional Neural Networks
Feb 11, 2018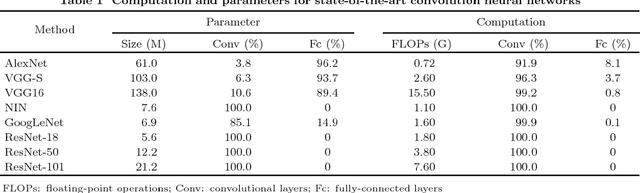
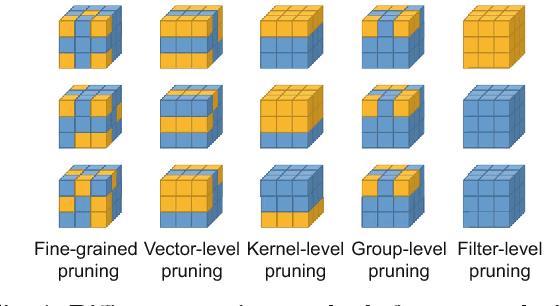
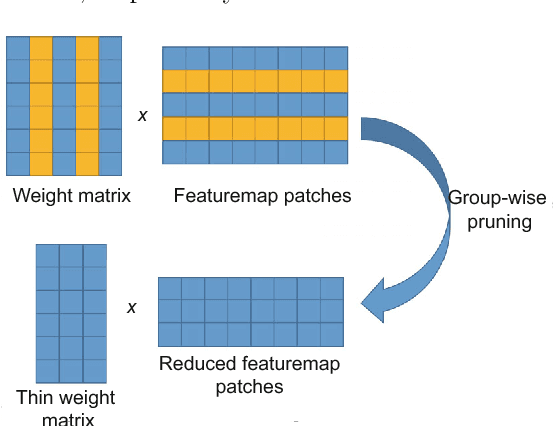
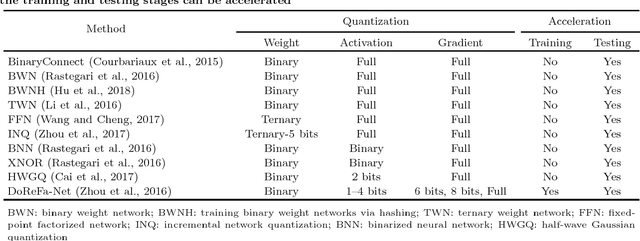
Deep neural networks have evolved remarkably over the past few years and they are currently the fundamental tools of many intelligent systems. At the same time, the computational complexity and resource consumption of these networks also continue to increase. This will pose a significant challenge to the deployment of such networks, especially in real-time applications or on resource-limited devices. Thus, network acceleration has become a hot topic within the deep learning community. As for hardware implementation of deep neural networks, a batch of accelerators based on FPGA/ASIC have been proposed in recent years. In this paper, we provide a comprehensive survey of recent advances in network acceleration, compression and accelerator design from both algorithm and hardware points of view. Specifically, we provide a thorough analysis of each of the following topics: network pruning, low-rank approximation, network quantization, teacher-student networks, compact network design and hardware accelerators. Finally, we will introduce and discuss a few possible future directions.
From Hashing to CNNs: Training BinaryWeight Networks via Hashing
Feb 08, 2018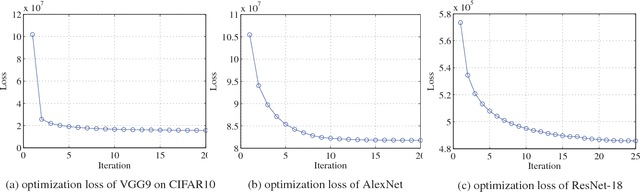
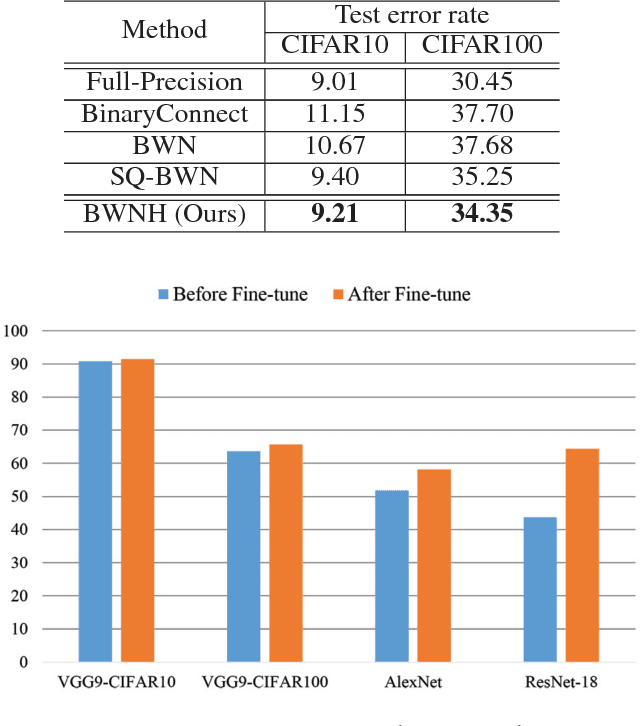
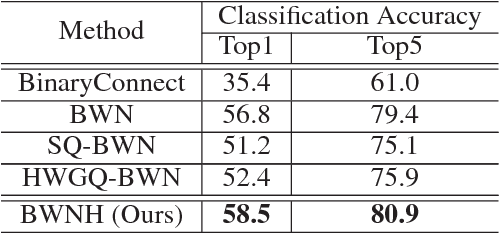
Deep convolutional neural networks (CNNs) have shown appealing performance on various computer vision tasks in recent years. This motivates people to deploy CNNs to realworld applications. However, most of state-of-art CNNs require large memory and computational resources, which hinders the deployment on mobile devices. Recent studies show that low-bit weight representation can reduce much storage and memory demand, and also can achieve efficient network inference. To achieve this goal, we propose a novel approach named BWNH to train Binary Weight Networks via Hashing. In this paper, we first reveal the strong connection between inner-product preserving hashing and binary weight networks, and show that training binary weight networks can be intrinsically regarded as a hashing problem. Based on this perspective, we propose an alternating optimization method to learn the hash codes instead of directly learning binary weights. Extensive experiments on CIFAR10, CIFAR100 and ImageNet demonstrate that our proposed BWNH outperforms current state-of-art by a large margin.