 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single-Loop Smoothed Gradient Descent-Ascent Algorithm for Nonconvex-Concave Min-Max Problems
Oct 29, 2020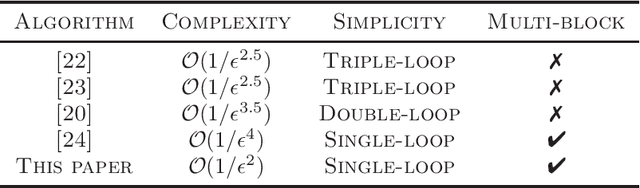
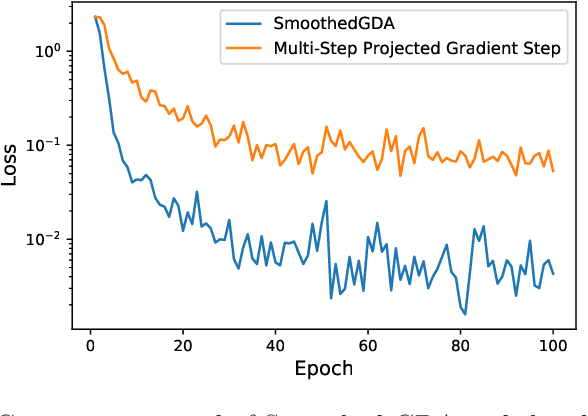

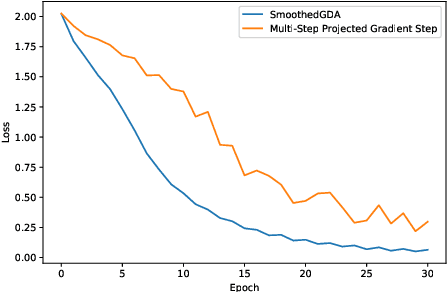
Nonconvex-concave min-max problem arises in many machine learning applications including minimizing a pointwise maximum of a set of nonconvex functions and robust adversarial training of neural networks. A popular approach to solve this problem is the gradient descent-ascent (GDA) algorithm which unfortunately can exhibit oscillation in case of nonconvexity. In this paper, we introduce a "smoothing" scheme which can be combined with GDA to stabilize the oscillation and ensure convergence to a stationary solution. We prove that the stabilized GDA algorithm can achieve an $O(1/\epsilon^2)$ iteration complexity for minimizing the pointwise maximum of a finite collection of nonconvex functions. Moreover, the smoothed GDA algorithm achieves an $O(1/\epsilon^4)$ iteration complexity for general nonconvex-concave problems. Extensions of this stabilized GDA algorithm to multi-block cases are presented. To the best of our knowledge, this is the first algorithm to achieve $O(1/\epsilon^2)$ for a class of nonconvex-concave problem. We illustrate the practical efficiency of the stabilized GDA algorithm on robust training.
DEED: A General Quantization Scheme for Communication Efficiency in Bits
Jun 19, 2020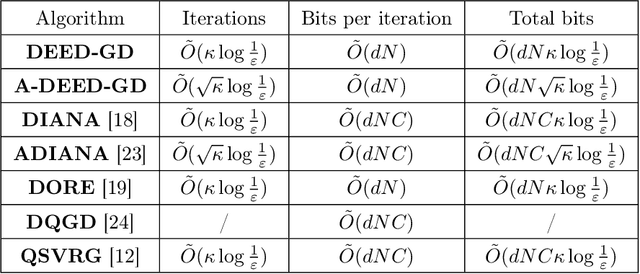
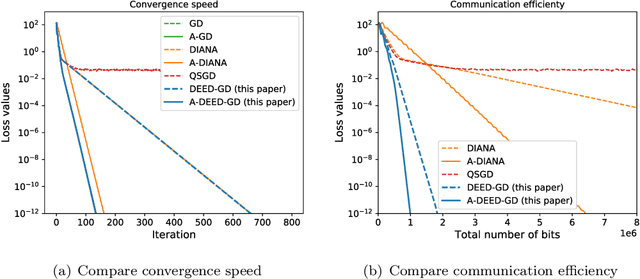

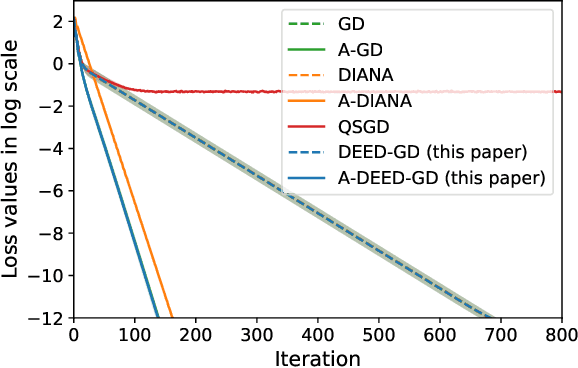
In distributed optimization, a popular technique to reduce communication is quantization. In this paper, we provide a general analysis framework for inexact gradient descent that is applicable to quantization schemes. We also propose a quantization scheme Double Encoding and Error Diminishing (DEED). DEED can achieve small communication complexity in three settings: frequent-communication large-memory, frequent-communication small-memory, and infrequent-communication (e.g. federated learning). More specifically, in the frequent-communication large-memory setting, DEED can be easily combined with Nesterov's method, so that the total number of bits required is $\tilde{O}( \sqrt{\kappa} \log 1/\epsilon )$, where $\tilde{O}$ hides numerical constant and $\log \kappa$ factors. In the frequent-communication small-memory setting, DEED combined with SGD only requires $\tilde{O}( \kappa \log 1/\epsilon)$ number of bits in the interpolation regime. In the infrequent communication setting, DEED combined with Federated averaging requires a smaller total number of bits than Federated Averaging. All these algorithms converge at the same rate as their non-quantized versions, while using a smaller number of bits.
Understanding Limitation of Two Symmetrized Orders by Worst-case Complexity
Oct 10, 2019
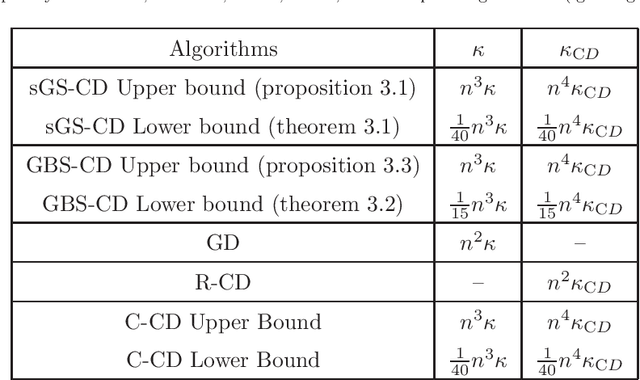

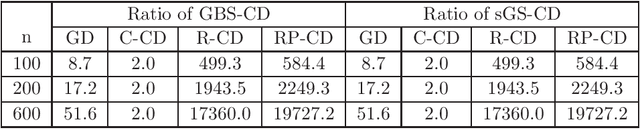
It was recently found that the standard version of multi-block cyclic ADMM diverges. Interestingly, Gaussian Back Substitution ADMM (GBS-ADMM) and symmetric Gauss-Seidel ADMM (sGS-ADMM) do not have the divergence issue. Therefore, it seems that symmetrization can improve the performance of the classical cyclic order. In another recent work, cyclic CD (Coordinate Descent) was shown to be $\mathcal{O}(n^2)$ times slower than randomized versions in the worst-case. A natural question arises: can the symmetrized orders achieve a faster convergence rate than the cyclic order, or even getting close to randomized versions? In this paper, we give a negative answer to this question. We show that both Gaussian Back Substitution and symmetric Gauss-Seidel order suffer from the same slow convergence issue as the cyclic order in the worst case. In particular, we prove that for unconstrained problems, they can be $\mathcal{O}(n^2)$ times slower than R-CD. For linearly constrained problems with quadratic objective, we empirically show the convergence speed of GBS-ADMM and sGS-ADMM can be roughly $\mathcal{O}(n^2)$ times slower than randomly permuted ADMM.