 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Federated Learning for Activity Recognition
Nov 06, 2020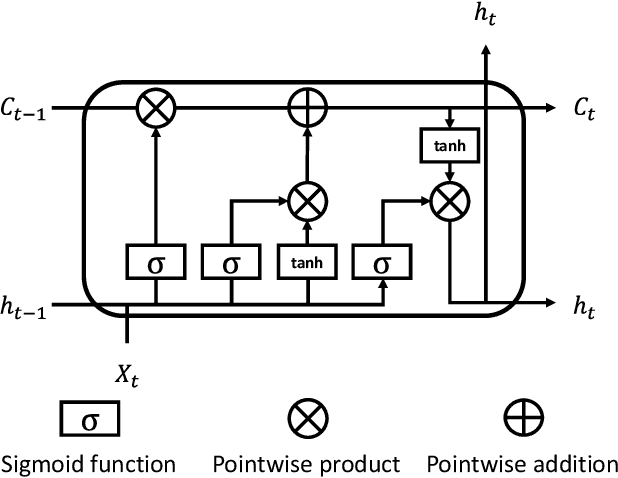
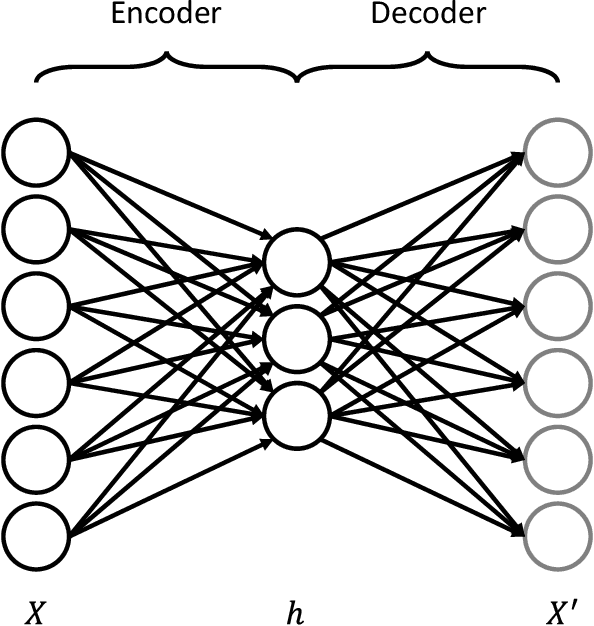

The proliferation of IoT sensors and edge devices makes it possible to use deep learning models to recognise daily activities locally using in-home monitoring technologies. Recently, federated learning systems that use edge devices as clients to collect and utilise IoT sensory data for human activity recognition have been commonly used as a new way to combine local (individual-level) and global (group-level) models. This approach provides better scalability and generalisability and also offers higher privacy compared with the traditional centralised analysis and learning models. The assumption behind federated learning, however, relies on supervised learning on clients. This requires a large volume of labelled data, which is difficult to collect in uncontrolled IoT environments such as remote in-home monitoring. In this paper, we propose an activity recognition system that uses semi-supervised federated learning, wherein clients conduct unsupervised learning on autoencoders with unlabelled local data to learn general representations, and a cloud server conducts supervised learning on an activity classifier with labelled data. Our experimental results show that using autoencoders and a long short-term memory (LSTM) classifier, the accuracy of our proposed system is comparable to that of a supervised federated learning system. Meanwhile, we demonstrate that our system is not affected by the Non-IID distribution of local data, and can even achieve better accuracy than supervised federated learning on some datasets. Additionally, we show that our proposed system can reduce the number of needed labels in the system and the size of local models without losing much accuracy, and has shorter local activity recognition time than supervised federated learning.
Verifying the Causes of Adversarial Examples
Oct 19, 2020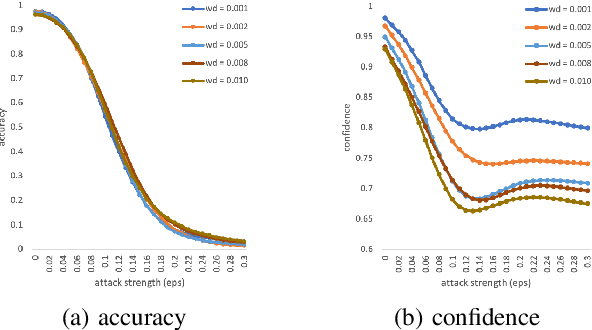
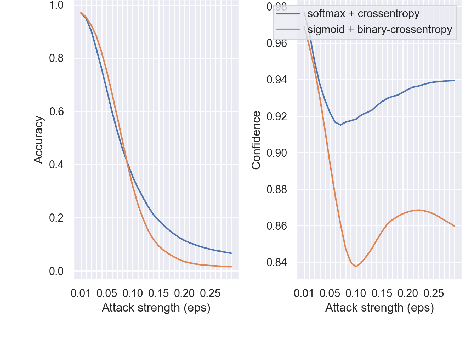
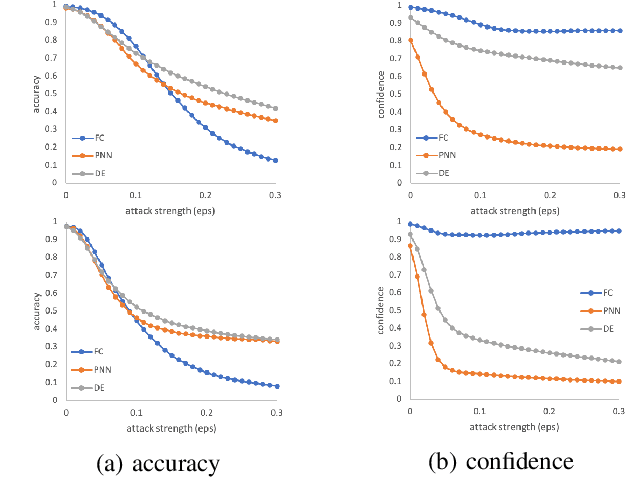
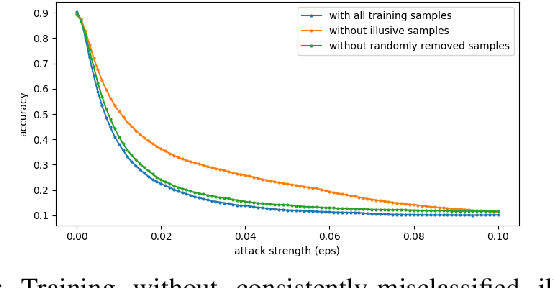
The robustness of neural networks is challenged by adversarial examples that contain almost imperceptible perturbations to inputs, which mislead a classifier to incorrect outputs in high confidence. Limited by the extreme difficulty in examining a high-dimensional image space thoroughly, research on explaining and justifying the causes of adversarial examples falls behind studies on attacks and defenses. In this paper, we present a collection of potential causes of adversarial examples and verify (or partially verify) them through carefully-designed controlled experiments. The major causes of adversarial examples include model linearity, one-sum constraint, and geometry of the categories. To control the effect of those causes, multiple techniques are applied such as $L_2$ normalization, replacement of loss functions, construction of reference datasets, and novel models using multi-layer perceptron probabilistic neural networks (MLP-PNN) and density estimation (DE). Our experiment results show that geometric factors tend to be more direct causes and statistical factors magnify the phenomenon, especially for assigning high prediction confidence. We believe this paper will inspire more studies to rigorously investigate the root causes of adversarial examples, which in turn provide useful guidance on designing more robust models.
Continual Learning Using Task Conditional Neural Networks
May 08, 2020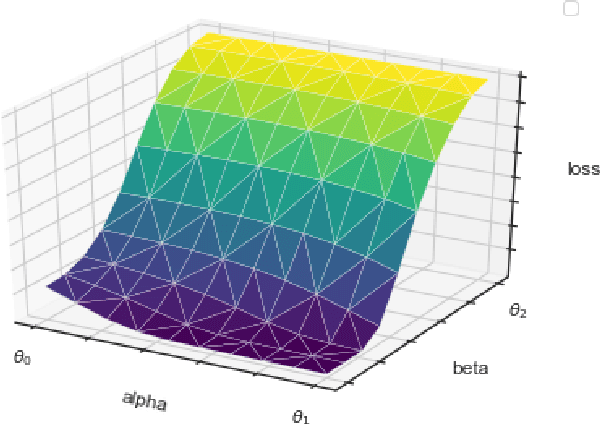
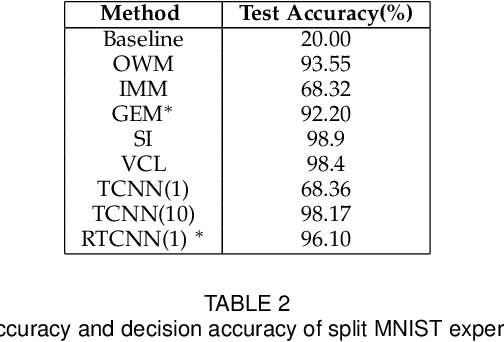
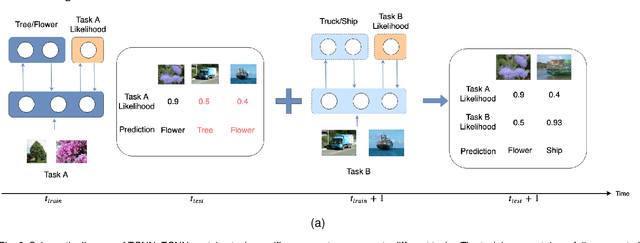
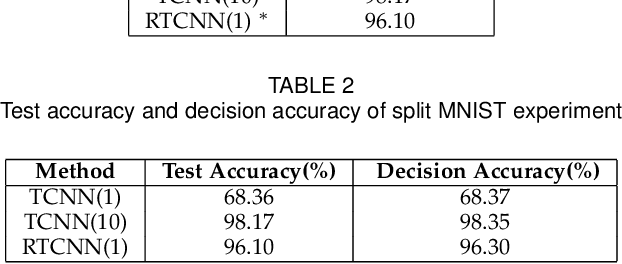
Conventional deep learning models have limited capacity in learning multiple tasks sequentially. The issue of forgetting the previously learned tasks in continual learning is known as catastrophic forgetting or interference. When the input data or the goal of learning change, a continual model will learn and adapt to the new status. However, the model will not remember or recognise any revisits to the previous states. This causes performance reduction and re-training curves in dealing with periodic or irregularly reoccurring changes in the data or goals. The changes in goals or data are referred to as new tasks in a continual learning model. Most of the continual learning methods have a task-known setup in which the task identities are known in advance to the learning model. We propose Task Conditional Neural Networks (TCNN) that does not require to known the reoccurring tasks in advance. We evaluate our model on standard datasets using MNIST and CIFAR10, and also a real-world dataset that we have collected in a remote healthcare monitoring study (i.e. TIHM dataset). The proposed model outperforms the state-of-the-art solutions in continual learning and adapting to new tasks that are not defined in advance.
Continual Learning Using Bayesian Neural Networks
Oct 09, 2019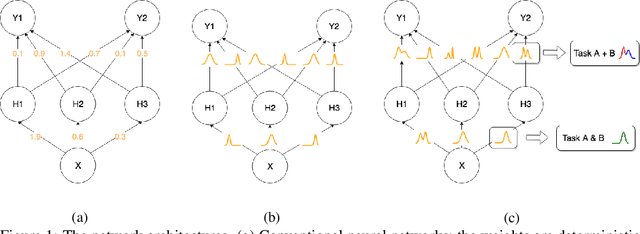

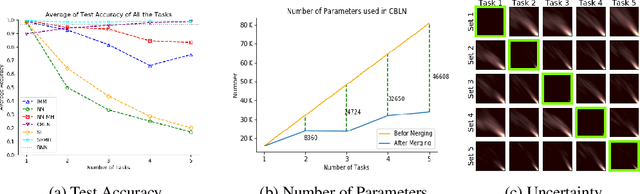
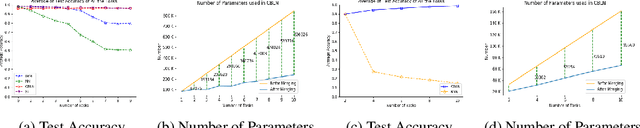
Continual learning models allow to learn and adapt to new changes and tasks over time. However, in continual and sequential learning scenarios in which the models are trained using different data with various distributions, neural networks tend to forget the previously learned knowledge. This phenomenon is often referred to as catastrophic forgetting. The catastrophic forgetting is an inevitable problem in continual learning models for dynamic environments. To address this issue, we propose a method, called Continual Bayesian Learning Networks (CBLN), which enables the networks to allocate additional resources to adapt to new tasks without forgetting the previously learned tasks. Using a Bayesian Neural Network, CBLN maintains a mixture of Gaussian posterior distributions that are associated with different tasks. The proposed method tries to optimise the number of resources that are needed to learn each task and avoids an exponential increase in the number of resources that are involved in learning multiple tasks. The proposed method does not need to access the past training data and can choose suitable weights to classify the data points during the test time automatically based on an uncertainty criterion. We have evaluated our method on the MNIST and UCR time-series datasets. The evaluation results show that our method can address the catastrophic forgetting problem at a promising rate compared to the state-of-the-art models.
Continual Learning in Deep Neural Network by Using a Kalman Optimiser
May 24, 2019
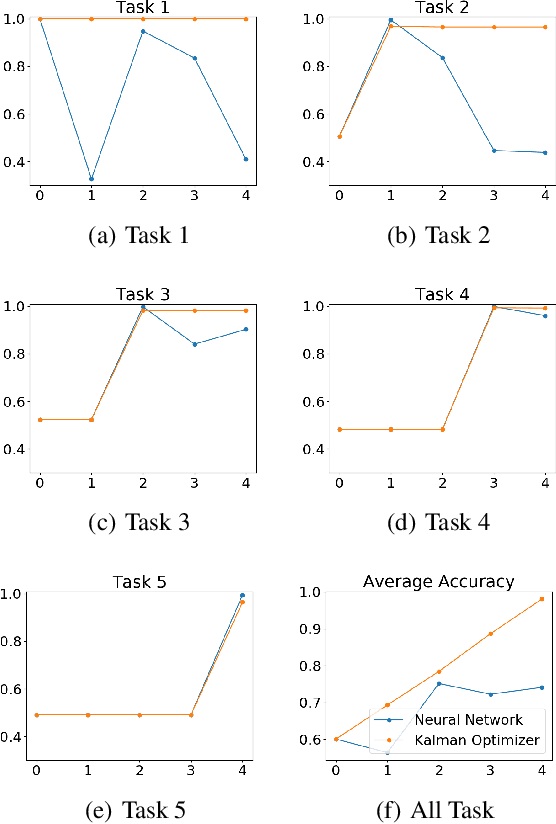
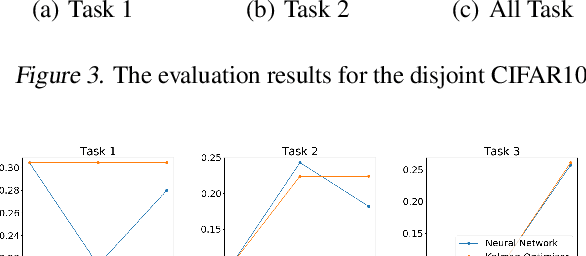
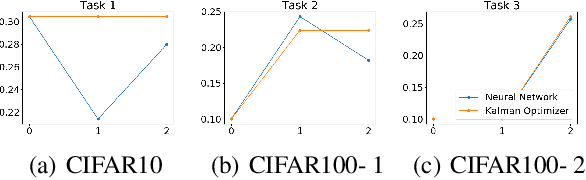
Learning and adapting to new distributions or learning new tasks sequentially without forgetting the previously learned knowledge is a challenging phenomenon in continual learning models. Most of the conventional deep learning models are not capable of learning new tasks sequentially in one model without forgetting the previously learned ones. We address this issue by using a Kalman Optimiser. The Kalman Optimiser divides the neural network into two parts: the long-term and short-term memory units. The long-term memory unit is used to remember the learned tasks and the short-term memory unit is to adapt to the new task. We have evaluated our method on MNIST, CIFAR10, CIFAR100 datasets and compare our results with state-of-the-art baseline models. The results show that our approach enables the model to continually learn and adapt to the new changes without forgetting the previously learned tasks.
Kalman Filter Modifier for Neural Networks in Non-stationary Environments
Nov 06, 2018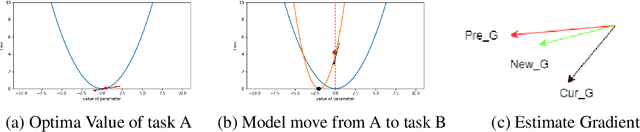
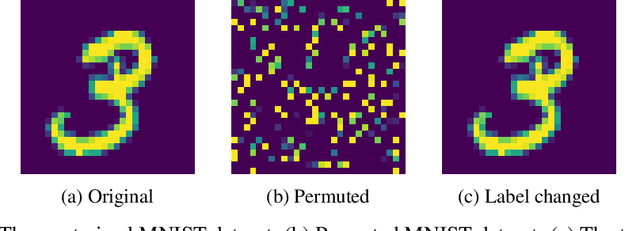
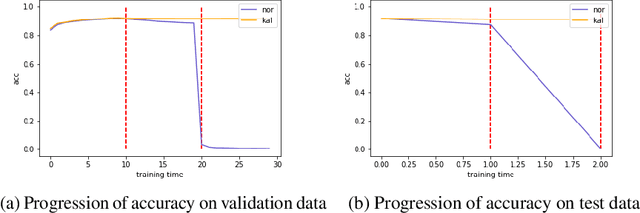
Learning in a non-stationary environment is an inevitable problem when applying machine learning algorithm to real world environment. Learning new tasks without forgetting the previous knowledge is a challenge issue in machine learning. We propose a Kalman Filter based modifier to maintain the performance of Neural Network models under non-stationary environments. The result shows that our proposed model can preserve the key information and adapts better to the changes. The accuracy of proposed model decreases by 0.4% in our experiments, while the accuracy of conventional model decreases by 90% in the drifts environment.
Machine learning for Internet of Things data analysis: A survey
Feb 17, 2018
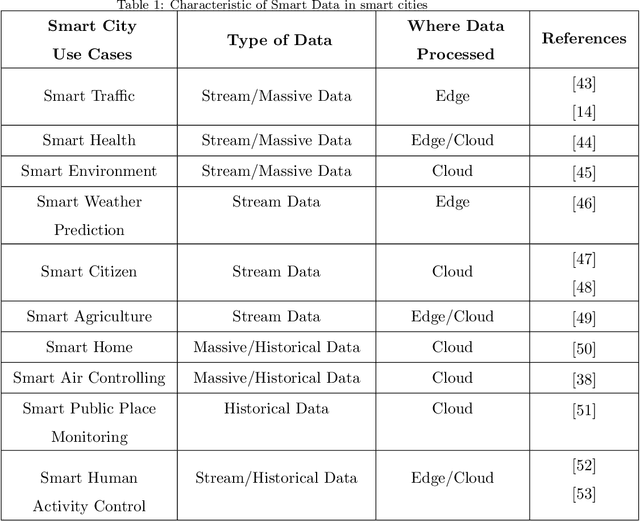
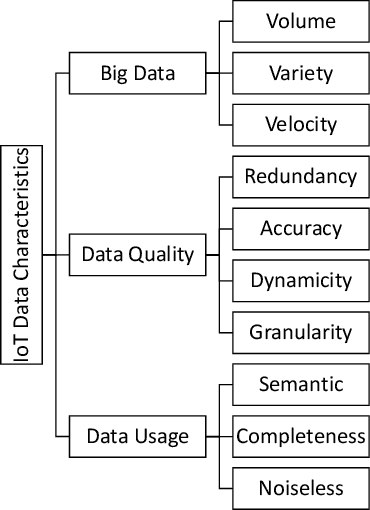
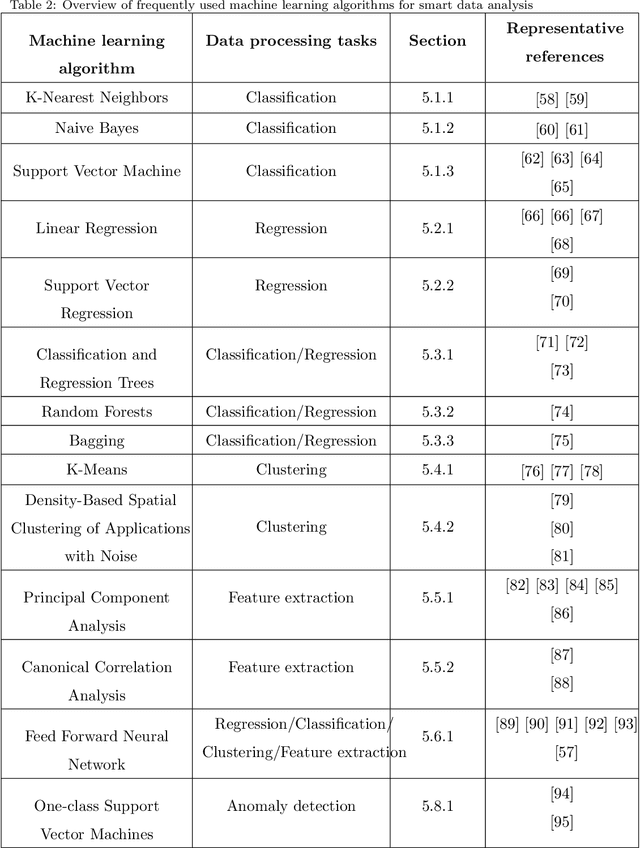
Rapid developments in hardware, software, and communication technologies have allowed the emergence of Internet-connected sensory devices that provide observation and data measurement from the physical world. By 2020, it is estimated that the total number of Internet-connected devices being used will be between 25 and 50 billion. As the numbers grow and technologies become more mature, the volume of data published will increase. Internet-connected devices technology, referred to as Internet of Things (IoT), continues to extend the current Internet by providing connectivity and interaction between the physical and cyber worlds. In addition to increased volume, the IoT generates Big Data characterized by velocity in terms of time and location dependency, with a variety of multiple modalities and varying data quality. Intelligent processing and analysis of this Big Data is the key to developing smart IoT applications. This article assesses the different machine learning methods that deal with the challenges in IoT data by considering smart cities as the main use case. The key contribution of this study is presentation of a taxonomy of machine learning algorithms explaining how different techniques are applied to the data in order to extract higher level information. The potential and challenges of machine learning for IoT data analytics will also be discussed. A use case of applying Support Vector Machine (SVM) on Aarhus Smart City traffic data is presented for a more detailed exploration.
Segment Parameter Labelling in MCMC Mean-Shift Change Detection
Oct 26, 2017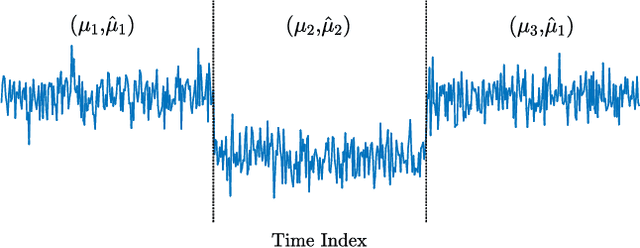
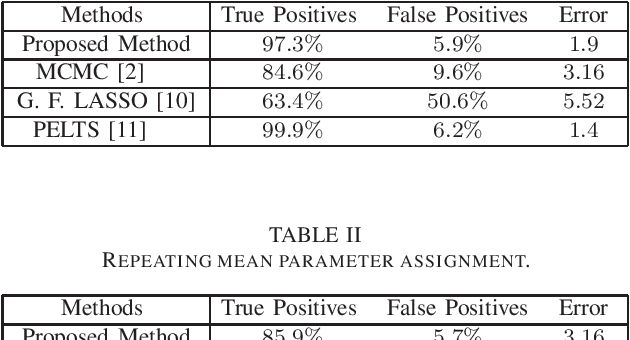
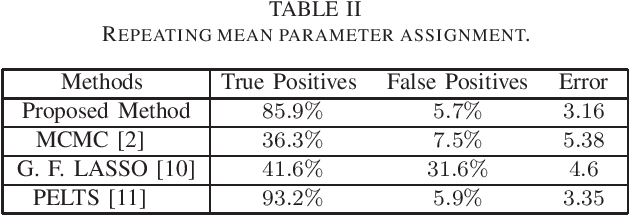
This work addresses the problem of segmentation in time series data with respect to a statistical parameter of interest in Bayesian models. It is common to assume that the parameters are distinct within each segment. As such, many Bayesian change point detection models do not exploit the segment parameter patterns, which can improve performance. This work proposes a Bayesian mean-shift change point detection algorithm that makes use of repetition in segment parameters, by introducing segment class labels that utilise a Dirichlet process prior. The performance of the proposed approach was assessed on both synthetic and real world data, highlighting the enhanced performance when using parameter labelling.
A Deep Multi-View Learning Framework for City Event Extraction from Twitter Data Streams
May 28, 2017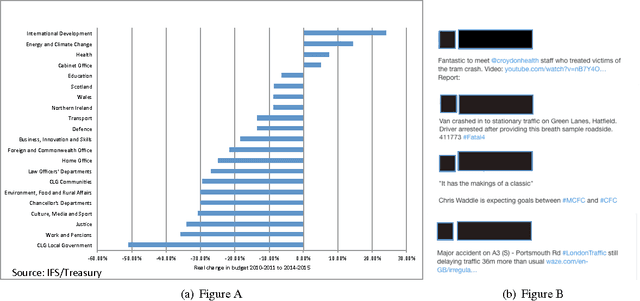

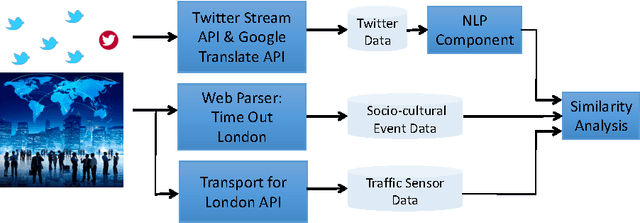
Cities have been a thriving place for citizens over the centuries due to their complex infrastructure. The emergence of the Cyber-Physical-Social Systems (CPSS) and context-aware technologies boost a growing interest in analysing, extracting and eventually understanding city events which subsequently can be utilised to leverage the citizen observations of their cities. In this paper, we investigate the feasibility of using Twitter textual streams for extracting city events. We propose a hierarchical multi-view deep learning approach to contextualise citizen observations of various city systems and services. Our goal has been to build a flexible architecture that can learn representations useful for tasks, thus avoiding excessive task-specific feature engineering. We apply our approach on a real-world dataset consisting of event reports and tweets of over four months from San Francisco Bay Area dataset and additional datasets collected from London. The results of our evaluations show that our proposed solution outperforms the existing models and can be used for extracting city related events with an averaged accuracy of 81% over all classes. To further evaluate the impact of our Twitter event extraction model, we have used two sources of authorised reports through collecting road traffic disruptions data from Transport for London API, and parsing the Time Out London website for sociocultural events. The analysis showed that 49.5% of the Twitter traffic comments are reported approximately five hours prior to the authorities official records. Moreover, we discovered that amongst the scheduled sociocultural event topics; tweets reporting transportation, cultural and social events are 31.75% more likely to influence the distribution of the Twitter comments than sport, weather and crime topics.