 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Cosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
Hybrid Verified Decoding: Learning to Allocate Verification in Speculative Decoding
May 31, 2026Large Language Model (LLM) generation remains expensive because autoregressive decoding calls the model once for each new token. Speculative decoding reduces this cost by drafting multiple tokens and verifying them with the target model in one step, but its speedup depends on how many drafted tokens are accepted. Parameter-free draft sources can propose long continuations at low cost in structured and agentic workloads, yet a cache match that looks promising at one generation step may have low payoff at the next. We propose Hybrid Verified Decoding, which predicts the accepted length of a cache draft before verification and uses this payoff estimate to choose between cache verification and a model-based drafter. Across three LLMs and sixteen datasets, Hybrid Verified Decoding is especially effective on agentic workflows, where it outperforms EAGLE3 in every setting with a 2.73x average speedup. Our analysis shows how prompt structure creates cache opportunities, how high-payoff cache drafts concentrate in a small part of the draft space, and how payoff-guided selection reduces sequential decoding work, pointing to runtime draft selection as a promising direction for speculative decoding.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
TSPP: A Unified Benchmarking Tool for Time-series Forecasting
Jan 08, 2024



While machine learning has witnessed significant advancements, the emphasis has largely been on data acquisition and model creation. However, achieving a comprehensive assessment of machine learning solutions in real-world settings necessitates standardization throughout the entire pipeline. This need is particularly acute in time series forecasting, where diverse settings impede meaningful comparisons between various methods. To bridge this gap, we propose a unified benchmarking framework that exposes the crucial modelling and machine learning decisions involved in developing time series forecasting models. This framework fosters seamless integration of models and datasets, aiding both practitioners and researchers in their development efforts. We benchmark recently proposed models within this framework, demonstrating that carefully implemented deep learning models with minimal effort can rival gradient-boosting decision trees requiring extensive feature engineering and expert knowledge.
Heterogenous Ensemble of Models for Molecular Property Prediction
Nov 20, 2022



Previous works have demonstrated the importance of considering different modalities on molecules, each of which provide a varied granularity of information for downstream property prediction tasks. Our method combines variants of the recent TransformerM architecture with Transformer, GNN, and ResNet backbone architectures. Models are trained on the 2D data, 3D data, and image modalities of molecular graphs. We ensemble these models with a HuberRegressor. The models are trained on 4 different train/validation splits of the original train + valid datasets. This yields a winning solution to the 2\textsuperscript{nd} edition of the OGB Large-Scale Challenge (2022) on the PCQM4Mv2 molecular property prediction dataset. Our proposed method achieves a test-challenge MAE of $0.0723$ and a validation MAE of $0.07145$. Total inference time for our solution is less than 2 hours. We open-source our code at https://github.com/jfpuget/NVIDIA-PCQM4Mv2.
A Framework for Large Scale Synthetic Graph Dataset Generation
Oct 06, 2022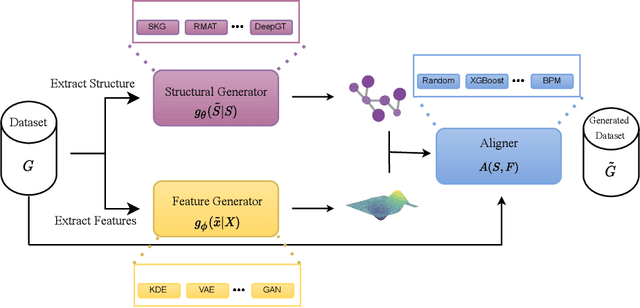
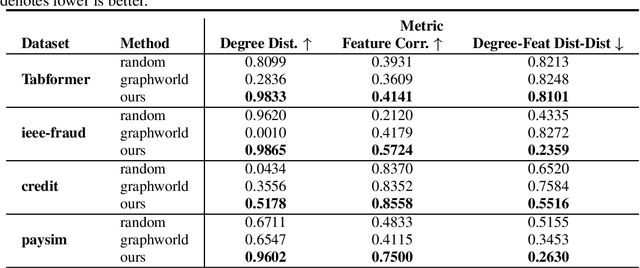
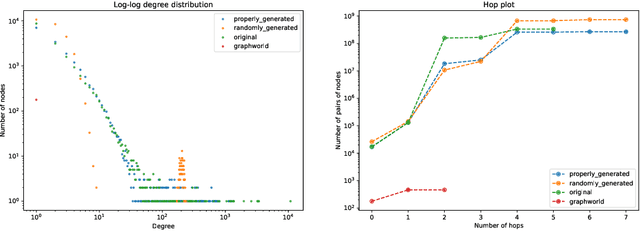
Recently there has been increasing interest in developing and deploying deep graph learning algorithms for many graph analysis tasks such as node and edge classification, link prediction, and clustering with numerous practical applications such as fraud detection, drug discovery, or recommender systems. Allbeit there is a limited number of publicly available graph-structured datasets, most of which are tiny compared to production-sized applications with trillions of edges and billions of nodes. Further, new algorithms and models are benchmarked across similar datasets with similar properties. In this work, we tackle this shortcoming by proposing a scalable synthetic graph generation tool that can mimic the original data distribution of real-world graphs and scale them to arbitrary sizes. This tool can be used then to learn a set of parametric models from proprietary datasets that can subsequently be released to researchers to study various graph methods on the synthetic data increasing prototype development and novel applications. Finally, the performance of the graph learning algorithms depends not only on the size but also on the dataset's structure. We show how our framework generalizes across a set of datasets, mimicking both structural and feature distributions as well as its scalability across varying dataset sizes.