 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Neural Networks for Quantum Eigenvalue Problems
Oct 10, 2020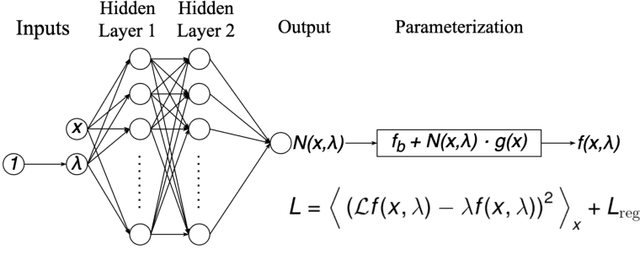
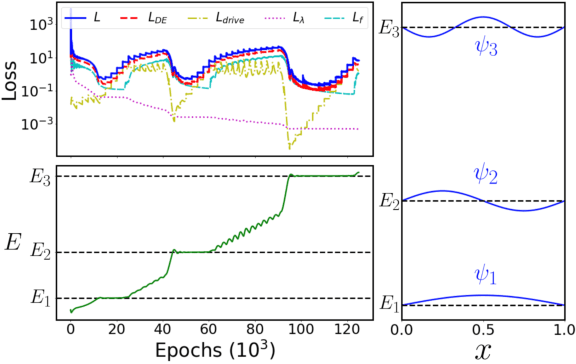
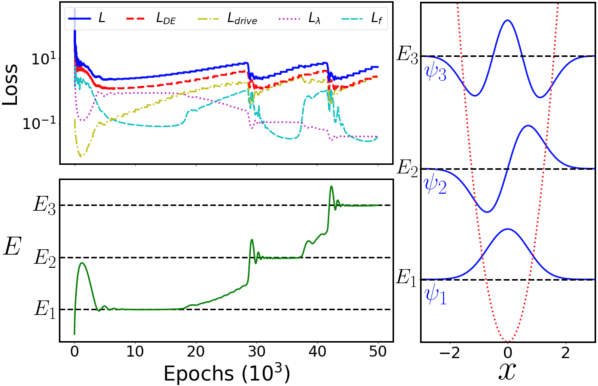
Eigenvalue problems are critical to several fields of science and engineering. We present a novel unsupervised neural network for discovering eigenfunctions and eigenvalues for differential eigenvalue problems with solutions that identically satisfy the boundary conditions. A scanning mechanism is embedded allowing the method to find an arbitrary number of solutions. The network optimization is data-free and depends solely on the predictions. The unsupervised method is used to solve the quantum infinite well and quantum oscillator eigenvalue problems.
Semi-supervised Neural Networks solve an inverse problem for modeling Covid-19 spread
Oct 10, 2020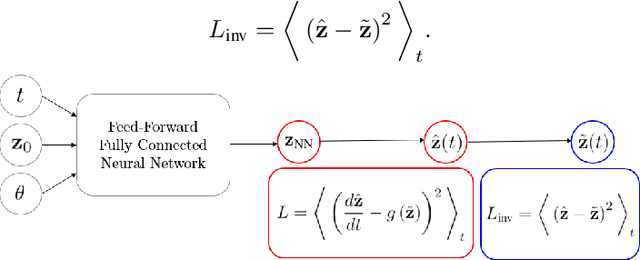
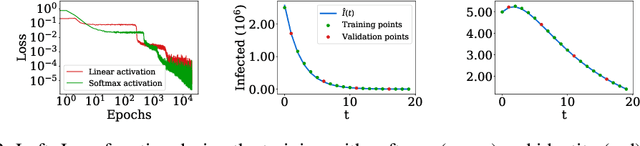
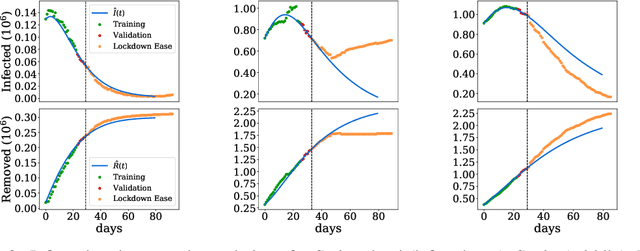
Studying the dynamics of COVID-19 is of paramount importance to understanding the efficiency of restrictive measures and develop strategies to defend against upcoming contagion waves. In this work, we study the spread of COVID-19 using a semi-supervised neural network and assuming a passive part of the population remains isolated from the virus dynamics. We start with an unsupervised neural network that learns solutions of differential equations for different modeling parameters and initial conditions. A supervised method then solves the inverse problem by estimating the optimal conditions that generate functions to fit the data for those infected by, recovered from, and deceased due to COVID-19. This semi-supervised approach incorporates real data to determine the evolution of the spread, the passive population, and the basic reproduction number for different countries.
MPCC: Matching Priors and Conditionals for Clustering
Aug 21, 2020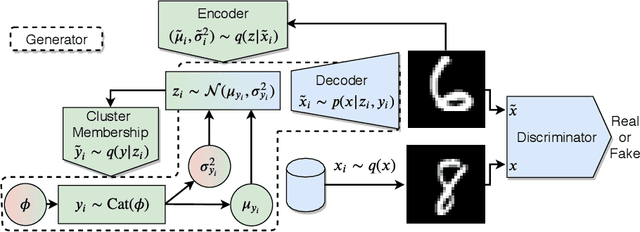


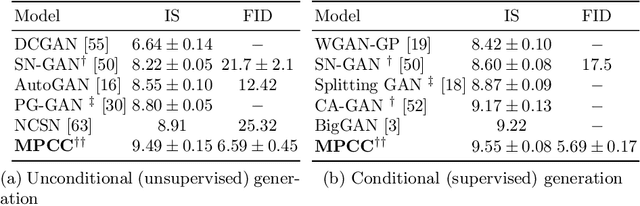
Clustering is a fundamental task in unsupervised learning that depends heavily on the data representation that is used. Deep generative models have appeared as a promising tool to learn informative low-dimensional data representations. We propose Matching Priors and Conditionals for Clustering (MPCC), a GAN-based model with an encoder to infer latent variables and cluster categories from data, and a flexible decoder to generate samples from a conditional latent space. With MPCC we demonstrate that a deep generative model can be competitive/superior against discriminative methods in clustering tasks surpassing the state of the art over a diverse set of benchmark datasets. Our experiments show that adding a learnable prior and augmenting the number of encoder updates improve the quality of the generated samples, obtaining an inception score of 9.49 $\pm$ 0.15 and improving the Fr\'echet inception distance over the state of the art by a 46.9% in CIFAR10.
Unsupervised Learning of Solutions to Differential Equations with Generative Adversarial Networks
Jul 21, 2020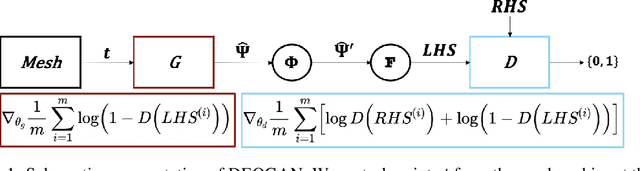
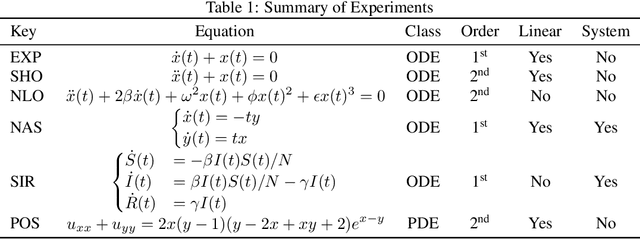
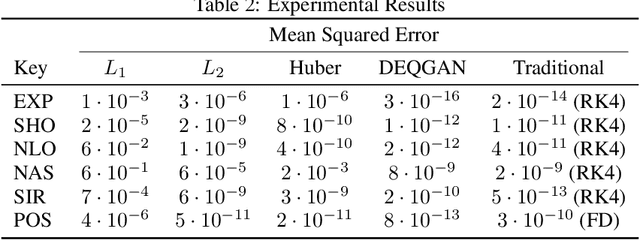
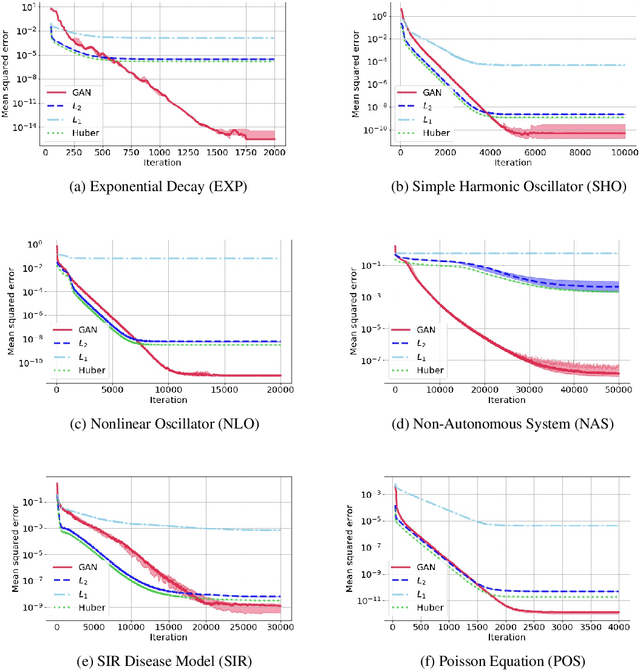
Solutions to differential equations are of significant scientific and engineering relevance. Recently, there has been a growing interest in solving differential equations with neural networks. This work develops a novel method for solving differential equations with unsupervised neural networks that applies Generative Adversarial Networks (GANs) to \emph{learn the loss function} for optimizing the neural network. We present empirical results showing that our method, which we call Differential Equation GAN (DEQGAN), can obtain multiple orders of magnitude lower mean squared errors than an alternative unsupervised neural network method based on (squared) $L_2$, $L_1$, and Huber loss functions. Moreover, we show that DEQGAN achieves solution accuracy that is competitive with traditional numerical methods. Finally, we analyze the stability of our approach and find it to be sensitive to the selection of hyperparameters, which we provide in the appendix. Code available at https://github.com/dylanrandle/denn. Please address any electronic correspondence to dylanrandle@alumni.harvard.edu.
Gender Classification and Bias Mitigation in Facial Images
Jul 13, 2020
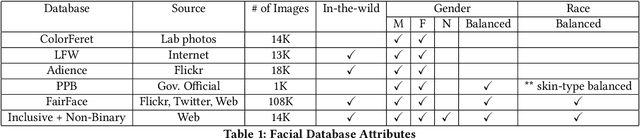
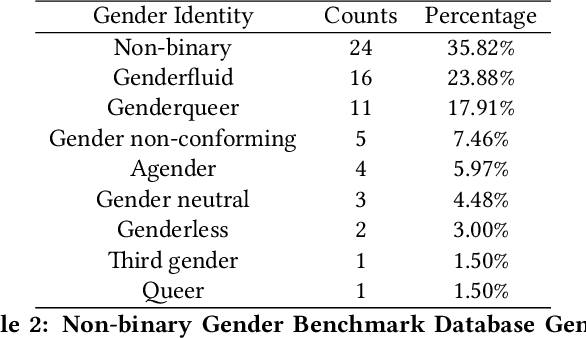
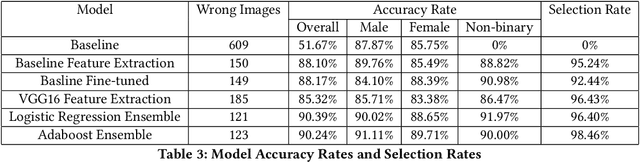
Gender classification algorithms have important applications in many domains today such as demographic research, law enforcement, as well as human-computer interaction. Recent research showed that algorithms trained on biased benchmark databases could result in algorithmic bias. However, to date, little research has been carried out on gender classification algorithms' bias towards gender minorities subgroups, such as the LGBTQ and the non-binary population, who have distinct characteristics in gender expression. In this paper, we began by conducting surveys on existing benchmark databases for facial recognition and gender classification tasks. We discovered that the current benchmark databases lack representation of gender minority subgroups. We worked on extending the current binary gender classifier to include a non-binary gender class. We did that by assembling two new facial image databases: 1) a racially balanced inclusive database with a subset of LGBTQ population 2) an inclusive-gender database that consists of people with non-binary gender. We worked to increase classification accuracy and mitigate algorithmic biases on our baseline model trained on the augmented benchmark database. Our ensemble model has achieved an overall accuracy score of 90.39%, which is a 38.72% increase from the baseline binary gender classifier trained on Adience. While this is an initial attempt towards mitigating bias in gender classification, more work is needed in modeling gender as a continuum by assembling more inclusive databases.
* 9 pages
Solving Differential Equations Using Neural Network Solution Bundles
Jun 17, 2020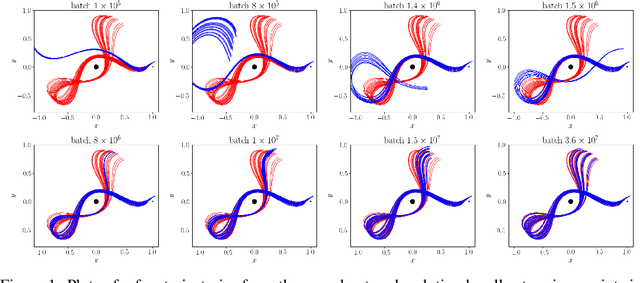

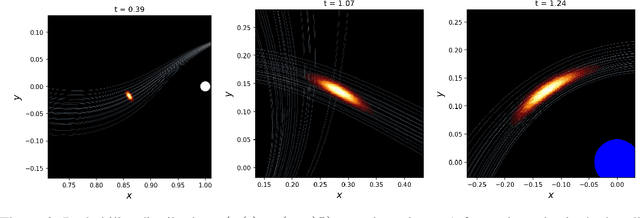

The time evolution of dynamical systems is frequently described by ordinary differential equations (ODEs), which must be solved for given initial conditions. Most standard approaches numerically integrate ODEs producing a single solution whose values are computed at discrete times. When many varied solutions with different initial conditions to the ODE are required, the computational cost can become significant. We propose that a neural network be used as a solution bundle, a collection of solutions to an ODE for various initial states and system parameters. The neural network solution bundle is trained with an unsupervised loss that does not require any prior knowledge of the sought solutions, and the resulting object is differentiable in initial conditions and system parameters. The solution bundle exhibits fast, parallelizable evaluation of the system state, facilitating the use of Bayesian inference for parameter estimation in real dynamical systems.
Application of Machine Learning to Predict the Risk of Alzheimer's Disease: An Accurate and Practical Solution for Early Diagnostics
Jun 02, 2020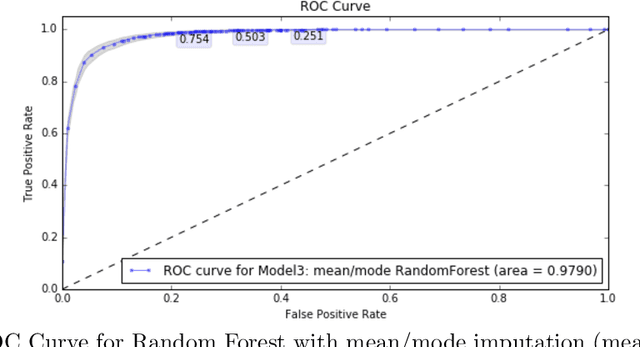

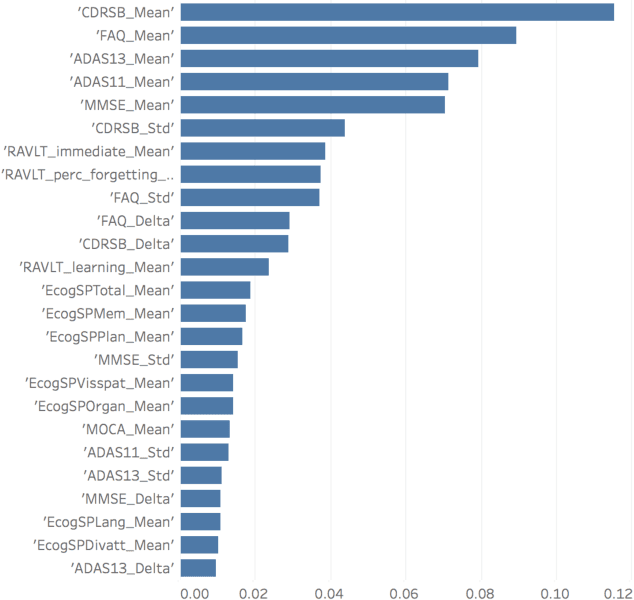
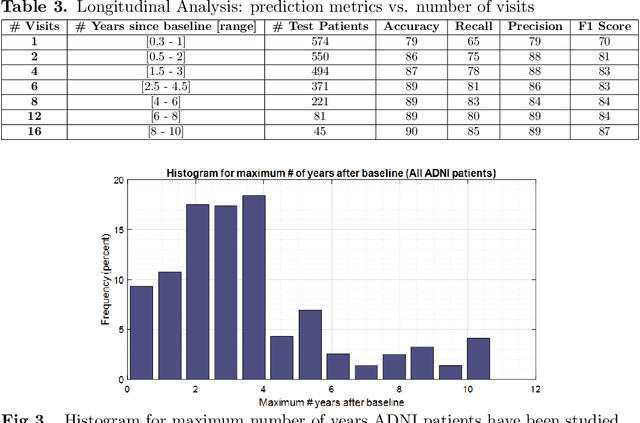
Alzheimer's Disease (AD) ravages the cognitive ability of more than 5 million Americans and creates an enormous strain on the health care system. This paper proposes a machine learning predictive model for AD development without medical imaging and with fewer clinical visits and tests, in hopes of earlier and cheaper diagnoses. That earlier diagnoses could be critical in the effectiveness of any drug or medical treatment to cure this disease. Our model is trained and validated using demographic, biomarker and cognitive test data from two prominent research studies: Alzheimer's Disease Neuroimaging Initiative (ADNI) and Australian Imaging, Biomarker Lifestyle Flagship Study of Aging (AIBL). We systematically explore different machine learning models, pre-processing methods and feature selection techniques. The most performant model demonstrates greater than 90% accuracy and recall in predicting AD, and the results generalize across sub-studies of ADNI and to the independent AIBL study. We also demonstrate that these results are robust to reducing the number of clinical visits or tests per visit. Using a metaclassification algorithm and longitudinal data analysis we are able to produce a "lean" diagnostic protocol with only 3 tests and 4 clinical visits that can predict Alzheimer's development with 87% accuracy and 79% recall. This novel work can be adapted into a practical early diagnostic tool for predicting the development of Alzheimer's that maximizes accuracy while minimizing the number of necessary diagnostic tests and clinical visits.
Gravitational Wave Detection and Information Extraction via Neural Networks
Mar 22, 2020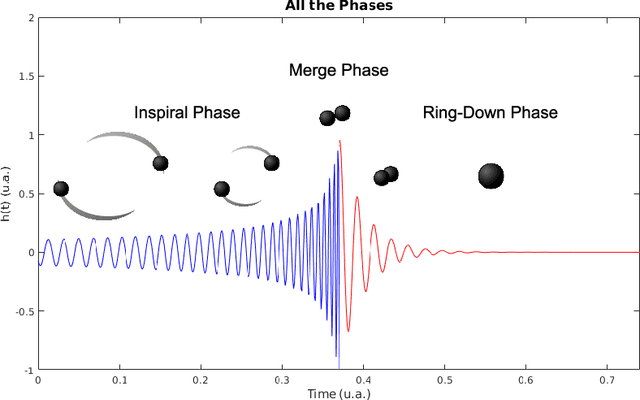
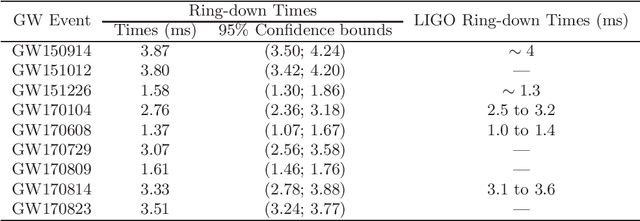
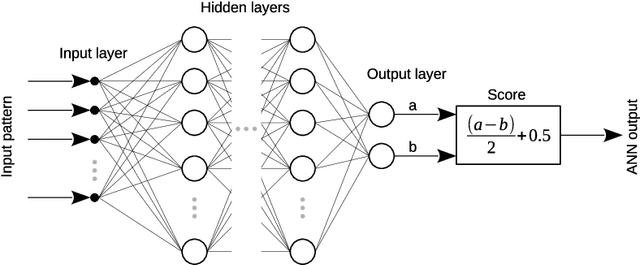
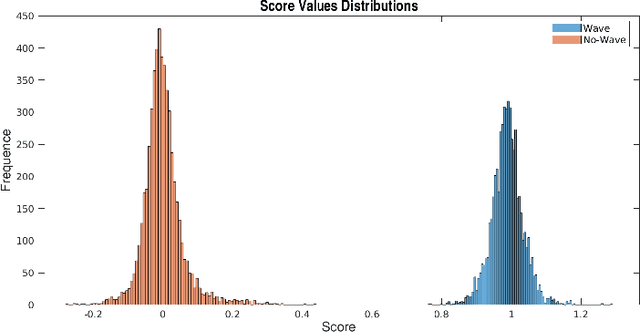
Laser Interferometer Gravitational-Wave Observatory (LIGO) was the first laboratory to measure the gravitational waves. It was needed an exceptional experimental design to measure distance changes much less than a radius of a proton. In the same way, the data analyses to confirm and extract information is a tremendously hard task. Here, it is shown a computational procedure base on artificial neural networks to detect a gravitation wave event and extract the knowledge of its ring-down time from the LIGO data. With this proposal, it is possible to make a probabilistic thermometer for gravitational wave detection and obtain physical information about the astronomical body system that created the phenomenon. Here, the ring-down time is determined with a direct data measure, without the need to use numerical relativity techniques and high computational power.
Hamiltonian Neural Networks for solving differential equations
Feb 12, 2020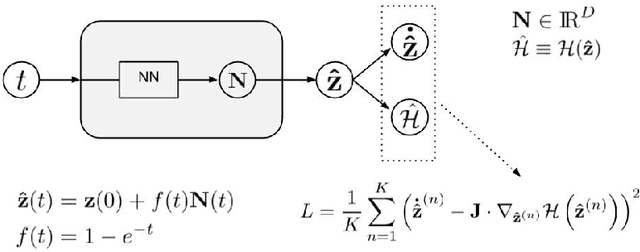
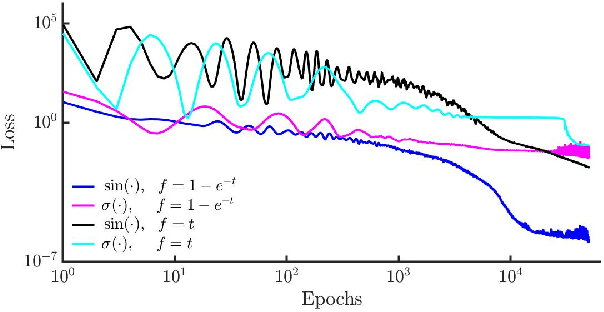
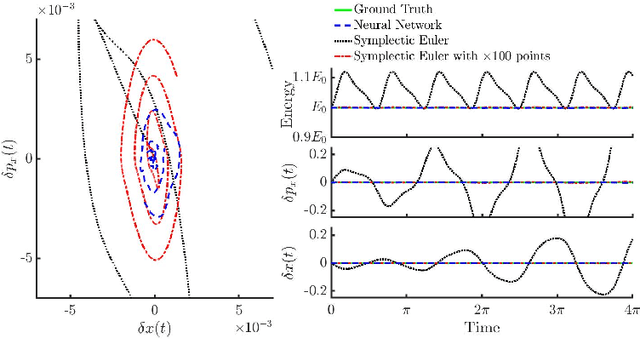
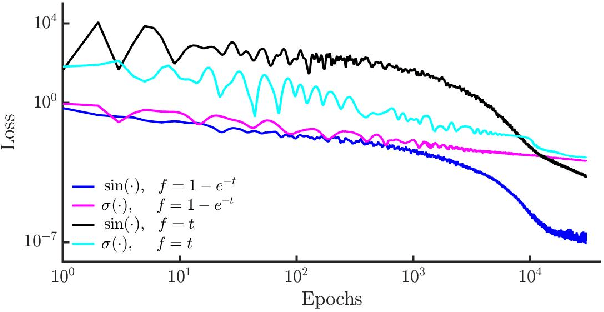
There has been a wave of interest in applying machine learning to study dynamical systems. In particular, neural networks have been applied to solve the equations of motion, and therefore, track the evolution of a system. In contrast to other applications of neural networks and machine learning, dynamical systems -- depending on their underlying symmetries -- possess invariants such as energy, momentum, and angular momentum. Traditional numerical iteration methods usually violate these conservation laws, propagating errors in time, and reducing the predictability of the method. We present a Hamiltonian neural network that solves the differential equations that govern dynamical systems. This unsupervised model is learning solutions that satisfy identically, up to an arbitrarily small error, Hamilton's equations and, therefore, conserve the Hamiltonian invariants. Once it is optimized, the proposed architecture is considered a symplectic unit due to the introduction of an efficient parametric form of solutions. In addition, by sharing the network parameters and the choice of an appropriate activation function drastically improve the predictability of the network. An error analysis is derived and states that the numerical errors depend on the overall network performance. The symplectic architecture is then employed to solve the equations for the nonlinear oscillator and the chaotic Henon-Heiles dynamical system. In both systems, the symplectic Euler integrator requires two orders more evaluation points than the Hamiltonian network in order to achieve the same order of the numerical error in the predicted phase space trajectories.
Scalable End-to-end Recurrent Neural Network for Variable star classification
Feb 03, 2020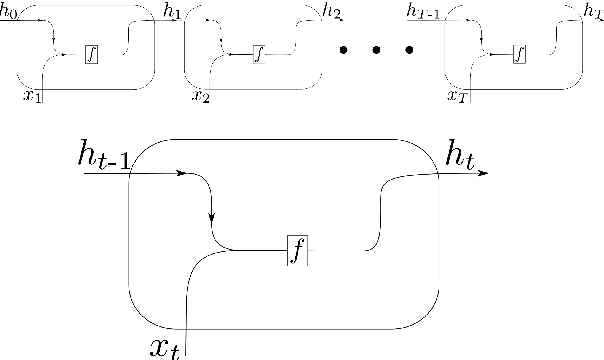

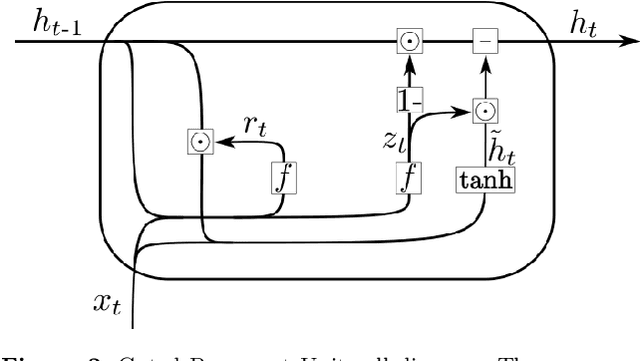
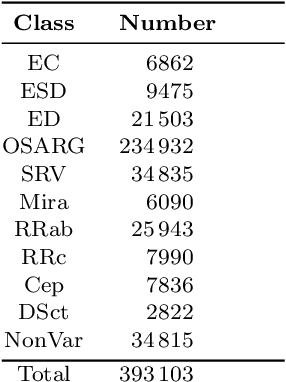
During the last decade, considerable effort has been made to perform automatic classification of variable stars using machine learning techniques. Traditionally, light curves are represented as a vector of descriptors or features used as input for many algorithms. Some features are computationally expensive, cannot be updated quickly and hence for large datasets such as the LSST cannot be applied. Previous work has been done to develop alternative unsupervised feature extraction algorithms for light curves, but the cost of doing so still remains high. In this work, we propose an end-to-end algorithm that automatically learns the representation of light curves that allows an accurate automatic classification. We study a series of deep learning architectures based on Recurrent Neural Networks and test them in automated classification scenarios. Our method uses minimal data preprocessing, can be updated with a low computational cost for new observations and light curves, and can scale up to massive datasets. We transform each light curve into an input matrix representation whose elements are the differences in time and magnitude, and the outputs are classification probabilities. We test our method in three surveys: OGLE-III, Gaia and WISE. We obtain accuracies of about $95\%$ in the main classes and $75\%$ in the majority of subclasses. We compare our results with the Random Forest classifier and obtain competitive accuracies while being faster and scalable. The analysis shows that the computational complexity of our approach grows up linearly with the light curve size, while the traditional approach cost grows as $N\log{(N)}$.