 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDAS: Deep learning human action intention prediction from natural eye movement patterns
Jan 22, 2022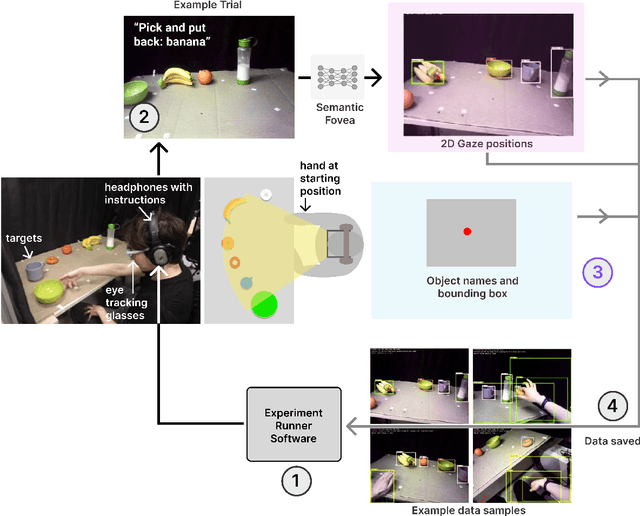
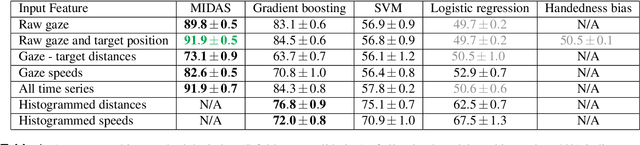
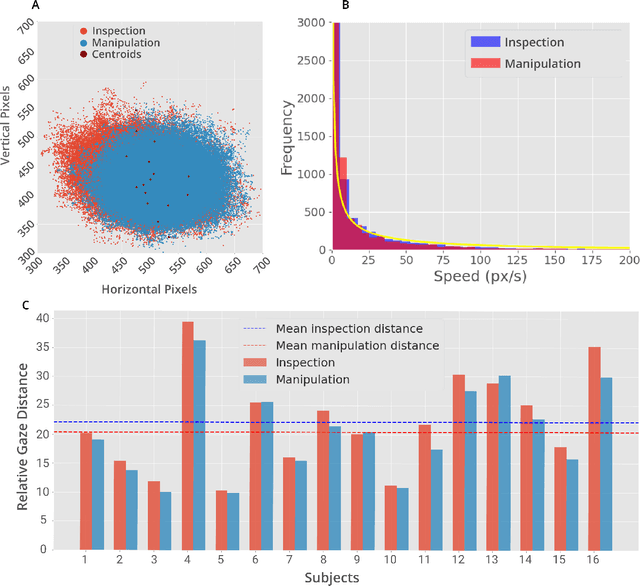
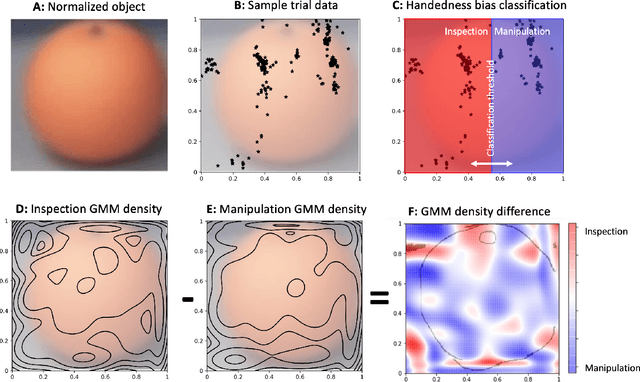
Eye movements have long been studied as a window into the attentional mechanisms of the human brain and made accessible as novelty style human-machine interfaces. However, not everything that we gaze upon, is something we want to interact with; this is known as the Midas Touch problem for gaze interfaces. To overcome the Midas Touch problem, present interfaces tend not to rely on natural gaze cues, but rather use dwell time or gaze gestures. Here we present an entirely data-driven approach to decode human intention for object manipulation tasks based solely on natural gaze cues. We run data collection experiments where 16 participants are given manipulation and inspection tasks to be performed on various objects on a table in front of them. The subjects' eye movements are recorded using wearable eye-trackers allowing the participants to freely move their head and gaze upon the scene. We use our Semantic Fovea, a convolutional neural network model to obtain the objects in the scene and their relation to gaze traces at every frame. We then evaluate the data and examine several ways to model the classification task for intention prediction. Our evaluation shows that intention prediction is not a naive result of the data, but rather relies on non-linear temporal processing of gaze cues. We model the task as a time series classification problem and design a bidirectional Long-Short-Term-Memory (LSTM) network architecture to decode intentions. Our results show that we can decode human intention of motion purely from natural gaze cues and object relative position, with $91.9\%$ accuracy. Our work demonstrates the feasibility of natural gaze as a Zero-UI interface for human-machine interaction, i.e., users will only need to act naturally, and do not need to interact with the interface itself or deviate from their natural eye movement patterns.
Gaze-contingent decoding of human navigation intention on an autonomous wheelchair platform
Mar 04, 2021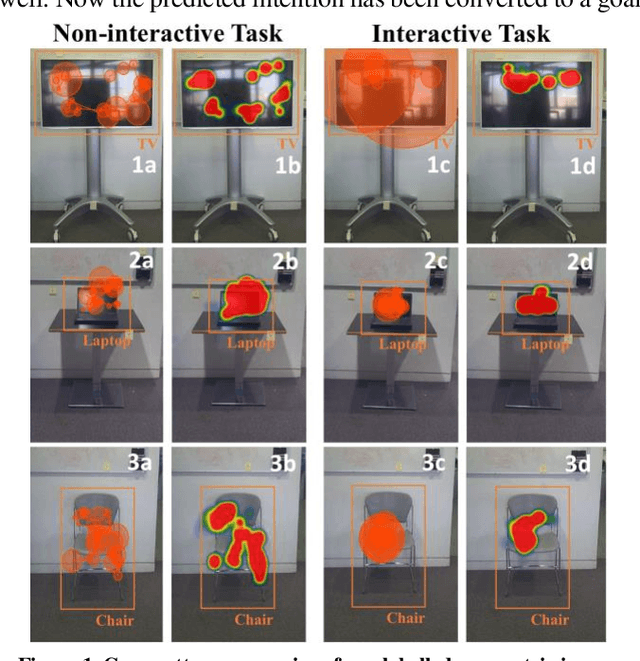
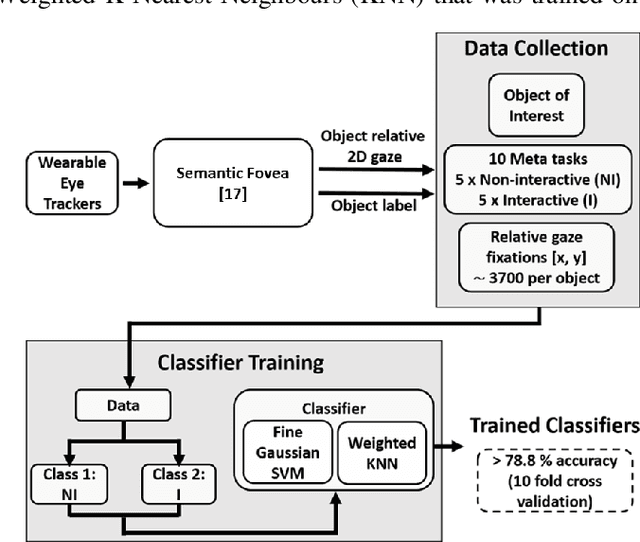

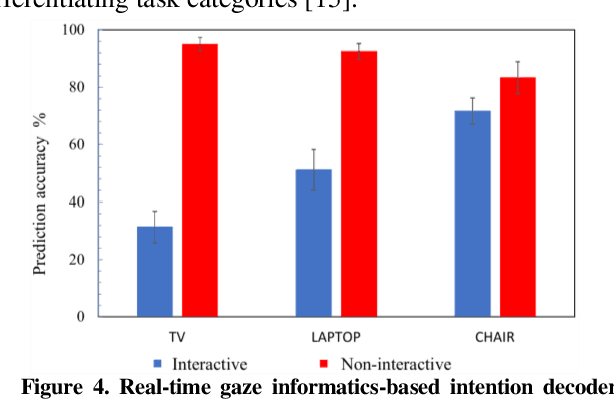
We have pioneered the Where-You-Look-Is Where-You-Go approach to controlling mobility platforms by decoding how the user looks at the environment to understand where they want to navigate their mobility device. However, many natural eye-movements are not relevant for action intention decoding, only some are, which places a challenge on decoding, the so-called Midas Touch Problem. Here, we present a new solution, consisting of 1. deep computer vision to understand what object a user is looking at in their field of view, with 2. an analysis of where on the object's bounding box the user is looking, to 3. use a simple machine learning classifier to determine whether the overt visual attention on the object is predictive of a navigation intention to that object. Our decoding system ultimately determines whether the user wants to drive to e.g., a door or just looks at it. Crucially, we find that when users look at an object and imagine they were moving towards it, the resulting eye-movements from this motor imagery (akin to neural interfaces) remain decodable. Once a driving intention and thus also the location is detected our system instructs our autonomous wheelchair platform, the A.Eye-Drive, to navigate to the desired object while avoiding static and moving obstacles. Thus, for navigation purposes, we have realised a cognitive-level human interface, as it requires the user only to cognitively interact with the desired goal, not to continuously steer their wheelchair to the target (low-level human interfacing).
Gaze-based, Context-aware Robotic System for Assisted Reaching and Grasping
Mar 06, 2019
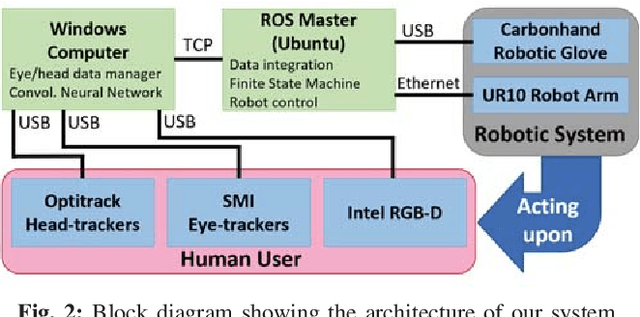
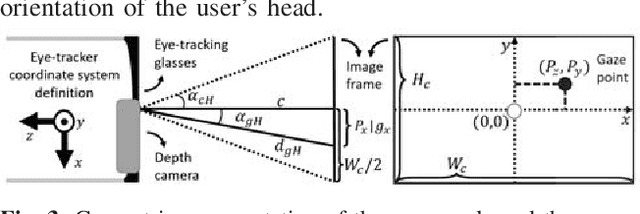
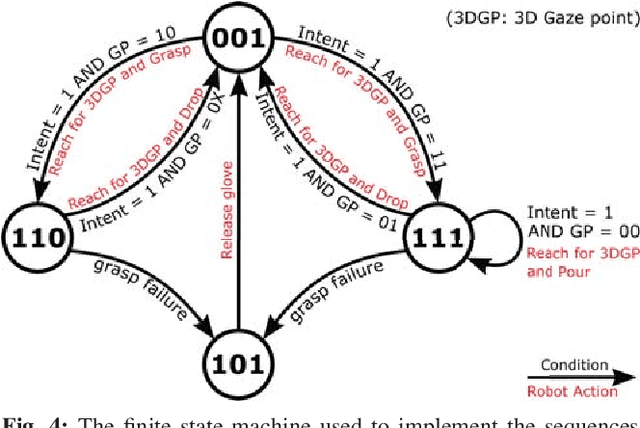
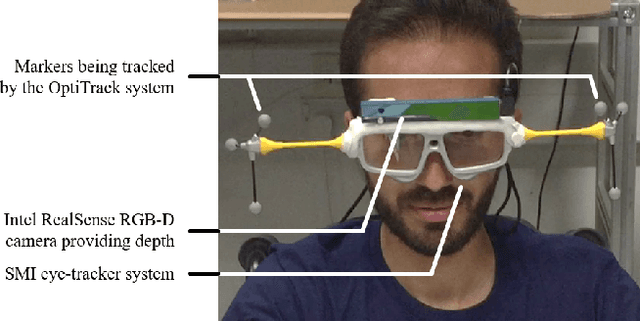
Assistive robotic systems endeavour to support those with movement disabilities, enabling them to move again and regain functionality. Main issue with these systems is the complexity of their low-level control, and how to translate this to simpler, higher level commands that are easy and intuitive for a human user to interact with. We have created a multi-modal system, consisting of different sensing, decision making and actuating modalities, leading to intuitive, human-in-the-loop assistive robotics. The system takes its cue from the user's gaze, to decode their intentions and implement low-level motion actions to achieve high-level tasks. This results in the user simply having to look at the objects of interest, for the robotic system to assist them in reaching for those objects, grasping them, and using them to interact with other objects. We present our method for 3D gaze estimation, and grammars-based implementation of sequences of action with the robotic system. The 3D gaze estimation is evaluated with 8 subjects, showing an overall accuracy of $4.68\pm0.14cm$. The full system is tested with 5 subjects, showing successful implementation of $100\%$ of reach to gaze point actions and full implementation of pick and place tasks in 96\%, and pick and pour tasks in $76\%$ of cases. Finally we present a discussion on our results and what future work is needed to improve the system.
Towards an Embodied Semantic Fovea: Semantic 3D scene reconstruction from ego-centric eye-tracker videos
Jul 27, 2018
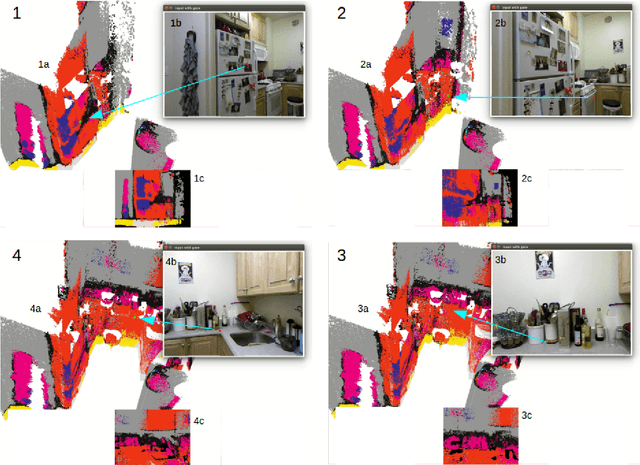
Incorporating the physical environment is essential for a complete understanding of human behavior in unconstrained every-day tasks. This is especially important in ego-centric tasks where obtaining 3 dimensional information is both limiting and challenging with the current 2D video analysis methods proving insufficient. Here we demonstrate a proof-of-concept system which provides real-time 3D mapping and semantic labeling of the local environment from an ego-centric RGB-D video-stream with 3D gaze point estimation from head mounted eye tracking glasses. We augment existing work in Semantic Simultaneous Localization And Mapping (Semantic SLAM) with collected gaze vectors. Our system can then find and track objects both inside and outside the user field-of-view in 3D from multiple perspectives with reasonable accuracy. We validate our concept by producing a semantic map from images of the NYUv2 dataset while simultaneously estimating gaze position and gaze classes from recorded gaze data of the dataset images.