 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatisficing in multi-armed bandit problems
Dec 19, 2016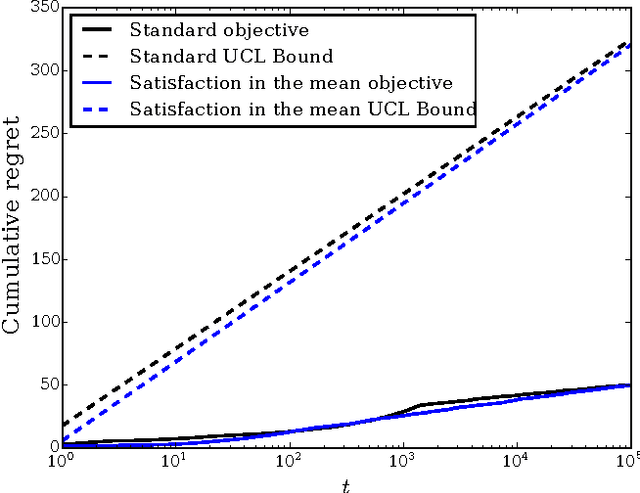
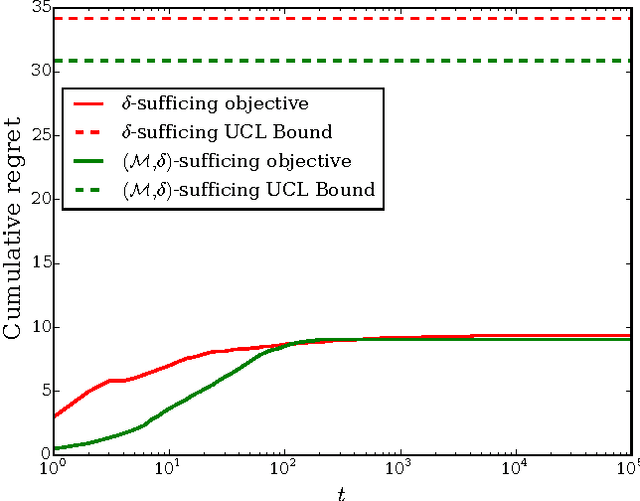
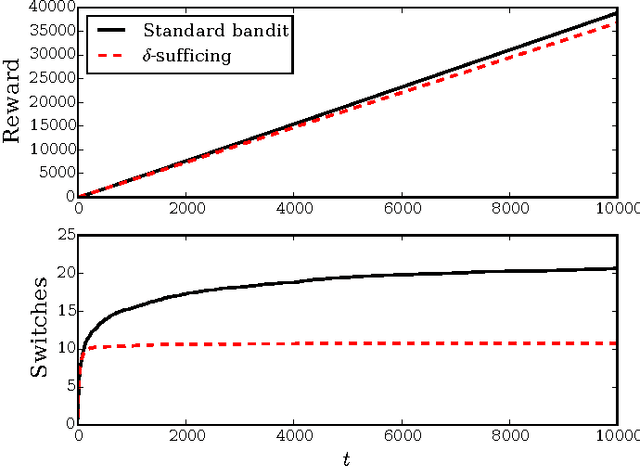
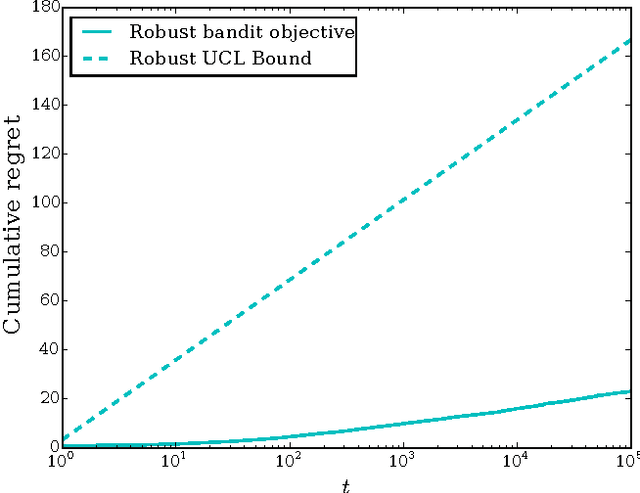
Satisficing is a relaxation of maximizing and allows for less risky decision making in the face of uncertainty. We propose two sets of satisficing objectives for the multi-armed bandit problem, where the objective is to achieve reward-based decision-making performance above a given threshold. We show that these new problems are equivalent to various standard multi-armed bandit problems with maximizing objectives and use the equivalence to find bounds on performance. The different objectives can result in qualitatively different behavior; for example, agents explore their options continually in one case and only a finite number of times in another. For the case of Gaussian rewards we show an additional equivalence between the two sets of satisficing objectives that allows algorithms developed for one set to be applied to the other. We then develop variants of the Upper Credible Limit (UCL) algorithm that solve the problems with satisficing objectives and show that these modified UCL algorithms achieve efficient satisficing performance.
Parameter estimation in softmax decision-making models with linear objective functions
Aug 29, 2015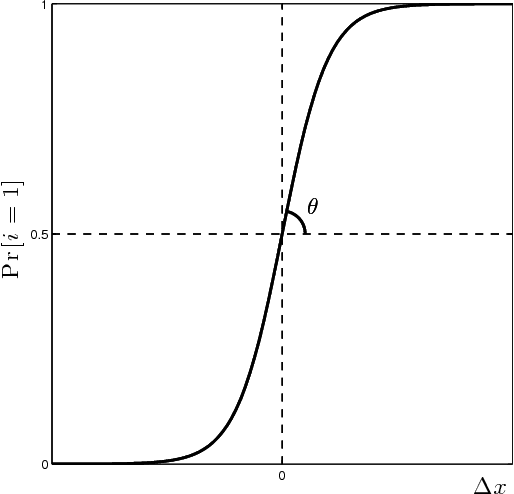
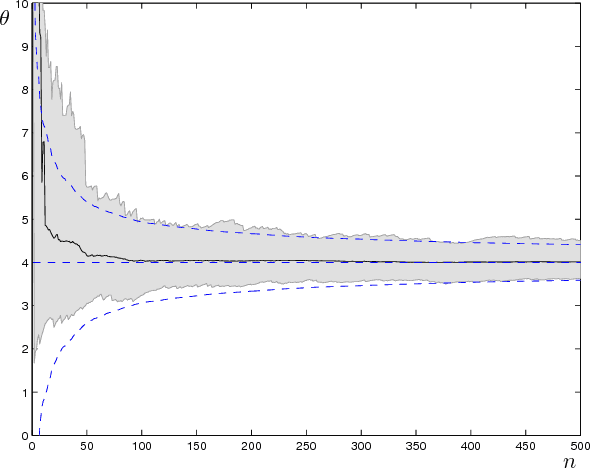
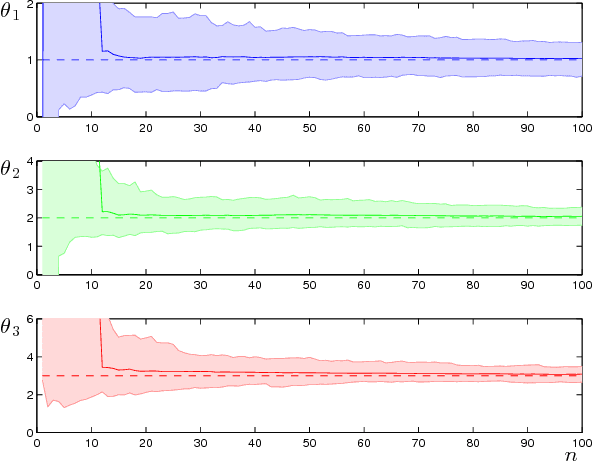
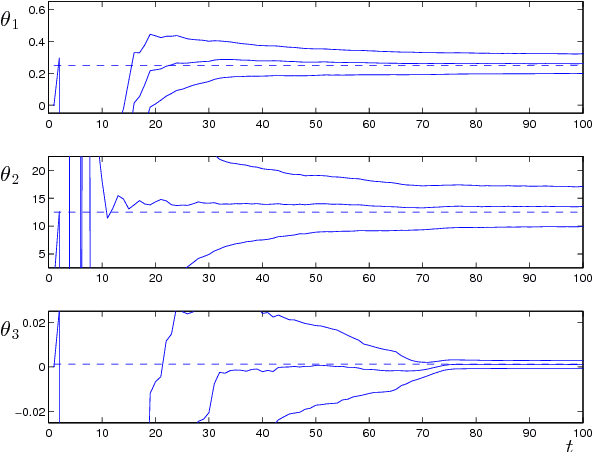
With an eye towards human-centered automation, we contribute to the development of a systematic means to infer features of human decision-making from behavioral data. Motivated by the common use of softmax selection in models of human decision-making, we study the maximum likelihood parameter estimation problem for softmax decision-making models with linear objective functions. We present conditions under which the likelihood function is convex. These allow us to provide sufficient conditions for convergence of the resulting maximum likelihood estimator and to construct its asymptotic distribution. In the case of models with nonlinear objective functions, we show how the estimator can be applied by linearizing about a nominal parameter value. We apply the estimator to fit the stochastic UCL (Upper Credible Limit) model of human decision-making to human subject data. We show statistically significant differences in behavior across related, but distinct, tasks.
Correlated Multiarmed Bandit Problem: Bayesian Algorithms and Regret Analysis
Jul 07, 2015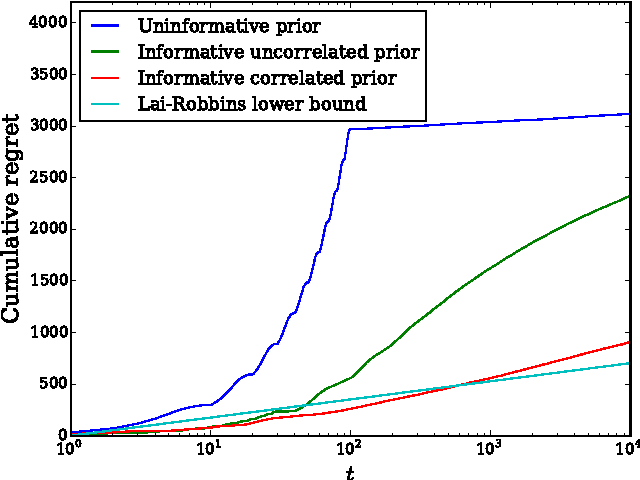
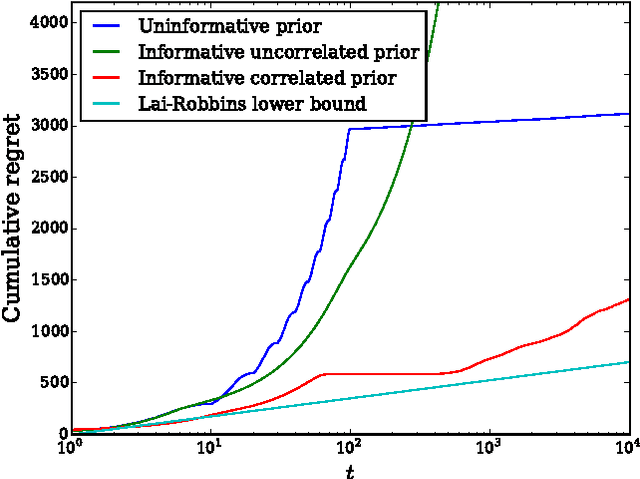
We consider the correlated multiarmed bandit (MAB) problem in which the rewards associated with each arm are modeled by a multivariate Gaussian random variable, and we investigate the influence of the assumptions in the Bayesian prior on the performance of the upper credible limit (UCL) algorithm and a new correlated UCL algorithm. We rigorously characterize the influence of accuracy, confidence, and correlation scale in the prior on the decision-making performance of the algorithms. Our results show how priors and correlation structure can be leveraged to improve performance.
Modeling Human Decision-making in Generalized Gaussian Multi-armed Bandits
Feb 14, 2014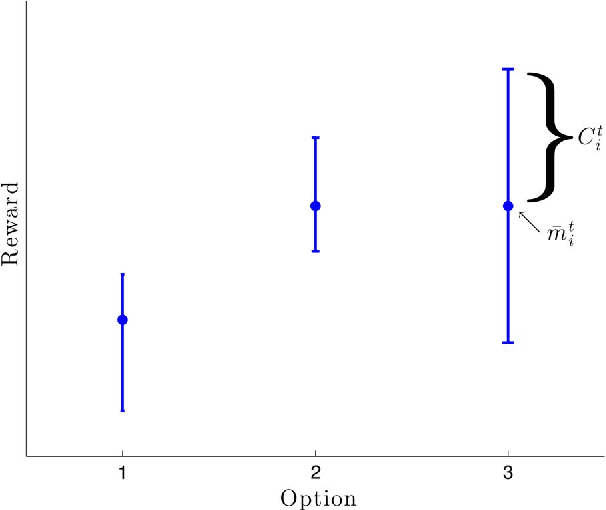
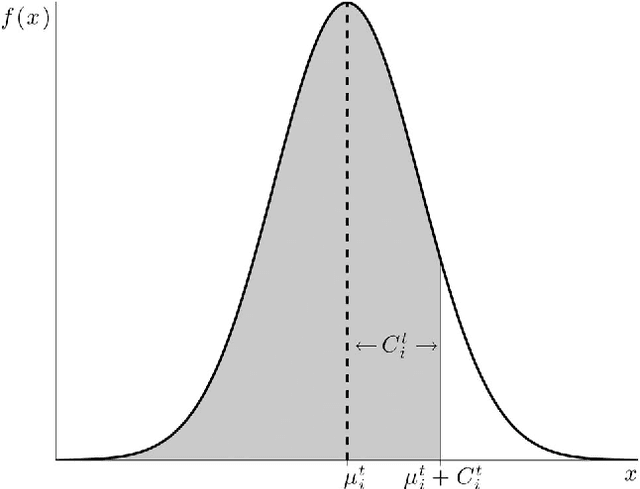
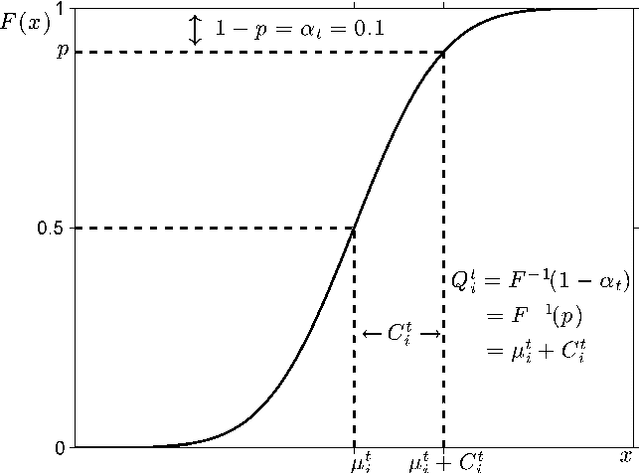
We present a formal model of human decision-making in explore-exploit tasks using the context of multi-armed bandit problems, where the decision-maker must choose among multiple options with uncertain rewards. We address the standard multi-armed bandit problem, the multi-armed bandit problem with transition costs, and the multi-armed bandit problem on graphs. We focus on the case of Gaussian rewards in a setting where the decision-maker uses Bayesian inference to estimate the reward values. We model the decision-maker's prior knowledge with the Bayesian prior on the mean reward. We develop the upper credible limit (UCL) algorithm for the standard multi-armed bandit problem and show that this deterministic algorithm achieves logarithmic cumulative expected regret, which is optimal performance for uninformative priors. We show how good priors and good assumptions on the correlation structure among arms can greatly enhance decision-making performance, even over short time horizons. We extend to the stochastic UCL algorithm and draw several connections to human decision-making behavior. We present empirical data from human experiments and show that human performance is efficiently captured by the stochastic UCL algorithm with appropriate parameters. For the multi-armed bandit problem with transition costs and the multi-armed bandit problem on graphs, we generalize the UCL algorithm to the block UCL algorithm and the graphical block UCL algorithm, respectively. We show that these algorithms also achieve logarithmic cumulative expected regret and require a sub-logarithmic expected number of transitions among arms. We further illustrate the performance of these algorithms with numerical examples.