 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Locally Low-dimensional Structure in Networks by Locally Optimal Spectral Embedding
Mar 12, 2026Standard Adjacency Spectral Embedding (ASE) relies on a global low-rank assumption often incompatible with the sparse, transitive structure of real-world networks, causing local geometric features to be 'smeared'. To address this, we introduce Local Adjacency Spectral Embedding (LASE), which uncovers locally low-dimensional structure via weighted spectral decomposition. Under a latent position model with a kernel feature map, we treat the image of latent positions as a locally low-dimensional set in infinite-dimensional feature space. We establish finite-sample bounds quantifying the trade-off between the statistical cost of localisation and the reduced truncation error achieved by targeting a locally low-dimensional region of the embedding. Furthermore, we prove that sufficient localisation induces rapid spectral decay and the emergence of a distinct spectral gap, theoretically justifying low-dimensional local embeddings. Experiments on synthetic and real networks show that LASE improves local reconstruction and visualisation over global and subgraph baselines, and we introduce UMAP-LASE for assembling overlapping local embeddings into high-fidelity global visualisations.
The Origins of Representation Manifolds in Large Language Models
May 23, 2025There is a large ongoing scientific effort in mechanistic interpretability to map embeddings and internal representations of AI systems into human-understandable concepts. A key element of this effort is the linear representation hypothesis, which posits that neural representations are sparse linear combinations of `almost-orthogonal' direction vectors, reflecting the presence or absence of different features. This model underpins the use of sparse autoencoders to recover features from representations. Moving towards a fuller model of features, in which neural representations could encode not just the presence but also a potentially continuous and multidimensional value for a feature, has been a subject of intense recent discourse. We describe why and how a feature might be represented as a manifold, demonstrating in particular that cosine similarity in representation space may encode the intrinsic geometry of a feature through shortest, on-manifold paths, potentially answering the question of how distance in representation space and relatedness in concept space could be connected. The critical assumptions and predictions of the theory are validated on text embeddings and token activations of large language models.
How high is `high'? Rethinking the roles of dimensionality in topological data analysis and manifold learning
May 22, 2025We present a generalised Hanson-Wright inequality and use it to establish new statistical insights into the geometry of data point-clouds. In the setting of a general random function model of data, we clarify the roles played by three notions of dimensionality: ambient intrinsic dimension $p_{\mathrm{int}}$, which measures total variability across orthogonal feature directions; correlation rank, which measures functional complexity across samples; and latent intrinsic dimension, which is the dimension of manifold structure hidden in data. Our analysis shows that in order for persistence diagrams to reveal latent homology and for manifold structure to emerge it is sufficient that $p_{\mathrm{int}}\gg \log n$, where $n$ is the sample size. Informed by these theoretical perspectives, we revisit the ground-breaking neuroscience discovery of toroidal structure in grid-cell activity made by Gardner et al. (Nature, 2022): our findings reveal, for the first time, evidence that this structure is in fact isometric to physical space, meaning that grid cell activity conveys a geometrically faithful representation of the real world.
Valid Conformal Prediction for Dynamic GNNs
May 29, 2024Graph neural networks (GNNs) are powerful black-box models which have shown impressive empirical performance. However, without any form of uncertainty quantification, it can be difficult to trust such models in high-risk scenarios. Conformal prediction aims to address this problem, however, an assumption of exchangeability is required for its validity which has limited its applicability to static graphs and transductive regimes. We propose to use unfolding, which allows any existing static GNN to output a dynamic graph embedding with exchangeability properties. Using this, we extend the validity of conformal prediction to dynamic GNNs in both transductive and semi-inductive regimes. We provide a theoretical guarantee of valid conformal prediction in these cases and demonstrate the empirical validity, as well as the performance gains, of unfolded GNNs against standard GNN architectures on both simulated and real datasets.
A Simple and Powerful Framework for Stable Dynamic Network Embedding
Nov 14, 2023



In this paper, we address the problem of dynamic network embedding, that is, representing the nodes of a dynamic network as evolving vectors within a low-dimensional space. While the field of static network embedding is wide and established, the field of dynamic network embedding is comparatively in its infancy. We propose that a wide class of established static network embedding methods can be used to produce interpretable and powerful dynamic network embeddings when they are applied to the dilated unfolded adjacency matrix. We provide a theoretical guarantee that, regardless of embedding dimension, these unfolded methods will produce stable embeddings, meaning that nodes with identical latent behaviour will be exchangeable, regardless of their position in time or space. We additionally define a hypothesis testing framework which can be used to evaluate the quality of a dynamic network embedding by testing for planted structure in simulated networks. Using this, we demonstrate that, even in trivial cases, unstable methods are often either conservative or encode incorrect structure. In contrast, we demonstrate that our suite of stable unfolded methods are not only more interpretable but also more powerful in comparison to their unstable counterparts.
Intensity Profile Projection: A Framework for Continuous-Time Representation Learning for Dynamic Networks
Jun 09, 2023



We present a new algorithmic framework, Intensity Profile Projection, for learning continuous-time representations of the nodes of a dynamic network, characterised by a node set and a collection of instantaneous interaction events which occur in continuous time. Our framework consists of three stages: estimating the intensity functions underlying the interactions between pairs of nodes, e.g. via kernel smoothing; learning a projection which minimises a notion of intensity reconstruction error; and inductively constructing evolving node representations via the learned projection. We show that our representations preserve the underlying structure of the network, and are temporally coherent, meaning that node representations can be meaningfully compared at different points in time. We develop estimation theory which elucidates the role of smoothing as a bias-variance trade-off, and shows how we can reduce smoothing as the signal-to-noise ratio increases on account of the algorithm `borrowing strength' across the network.
Hierarchical clustering with dot products recovers hidden tree structure
May 24, 2023



In this paper we offer a new perspective on the well established agglomerative clustering algorithm, focusing on recovery of hierarchical structure. We recommend a simple variant of the standard algorithm, in which clusters are merged by maximum average dot product and not, for example, by minimum distance or within-cluster variance. We demonstrate that the tree output by this algorithm provides a bona fide estimate of generative hierarchical structure in data, under a generic probabilistic graphical model. The key technical innovations are to understand how hierarchical information in this model translates into tree geometry which can be recovered from data, and to characterise the benefits of simultaneously growing sample size and data dimension. We demonstrate superior tree recovery performance with real data over existing approaches such as UPGMA, Ward's method, and HDBSCAN.
Implications of sparsity and high triangle density for graph representation learning
Oct 27, 2022



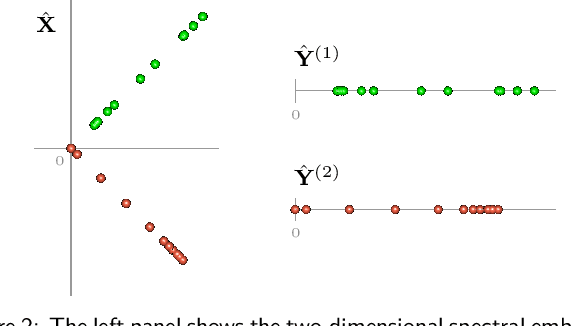
Recent work has shown that sparse graphs containing many triangles cannot be reproduced using a finite-dimensional representation of the nodes, in which link probabilities are inner products. Here, we show that such graphs can be reproduced using an infinite-dimensional inner product model, where the node representations lie on a low-dimensional manifold. Recovering a global representation of the manifold is impossible in a sparse regime. However, we can zoom in on local neighbourhoods, where a lower-dimensional representation is possible. As our constructions allow the points to be uniformly distributed on the manifold, we find evidence against the common perception that triangles imply community structure.
Spectral embedding and the latent geometry of multipartite networks
Feb 08, 2022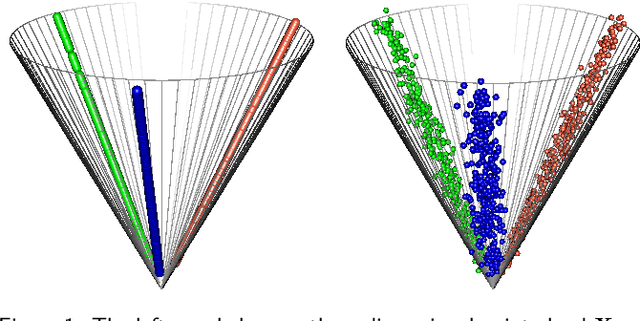
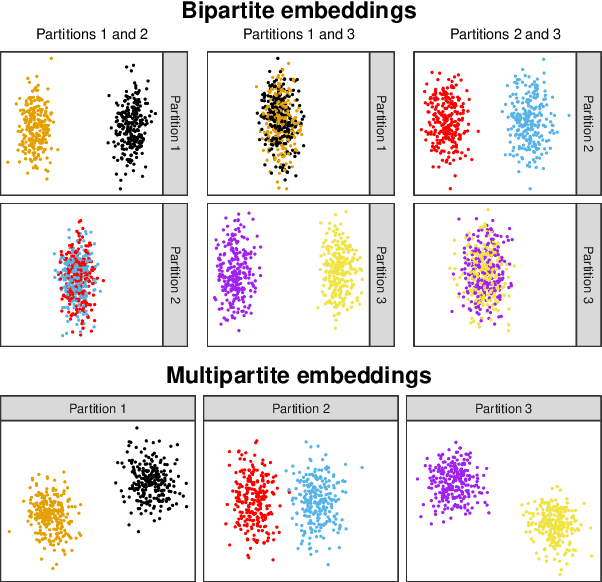
Spectral embedding finds vector representations of the nodes of a network, based on the eigenvectors of its adjacency or Laplacian matrix, and has found applications throughout the sciences. Many such networks are multipartite, meaning their nodes can be divided into partitions and nodes of the same partition are never connected. When the network is multipartite, this paper demonstrates that the node representations obtained via spectral embedding live near partition-specific low-dimensional subspaces of a higher-dimensional ambient space. For this reason we propose a follow-on step after spectral embedding, to recover node representations in their intrinsic rather than ambient dimension, proving uniform consistency under a low-rank, inhomogeneous random graph model. Our method naturally generalizes bipartite spectral embedding, in which node representations are obtained by singular value decomposition of the biadjacency or bi-Laplacian matrix.
Spectral embedding for dynamic networks with stability guarantees
Jun 02, 2021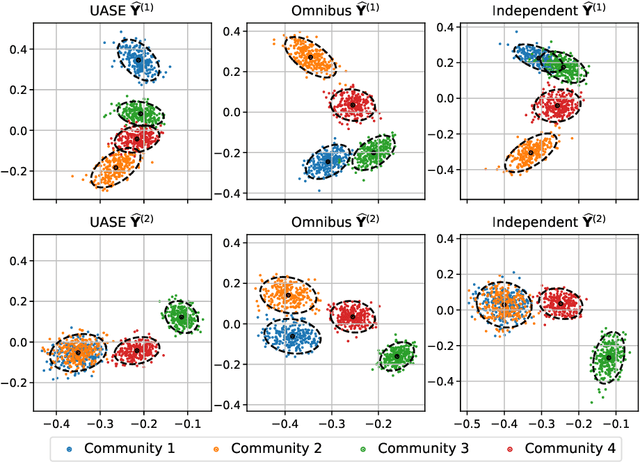
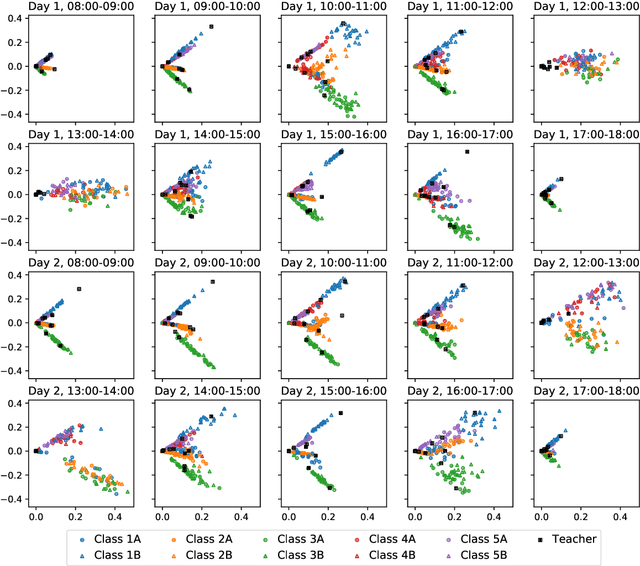
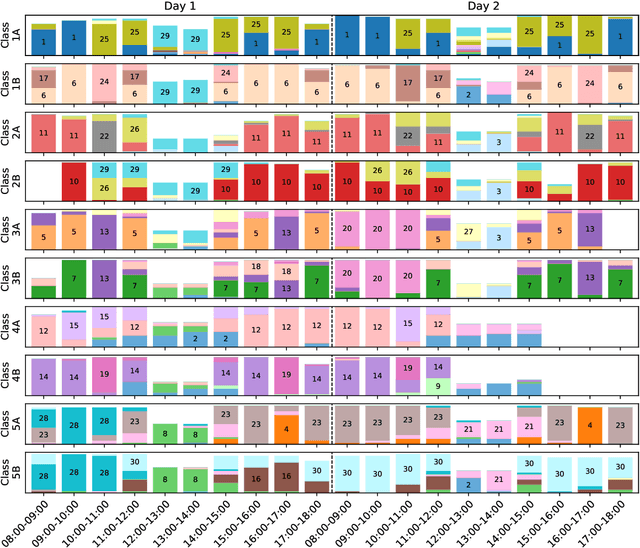
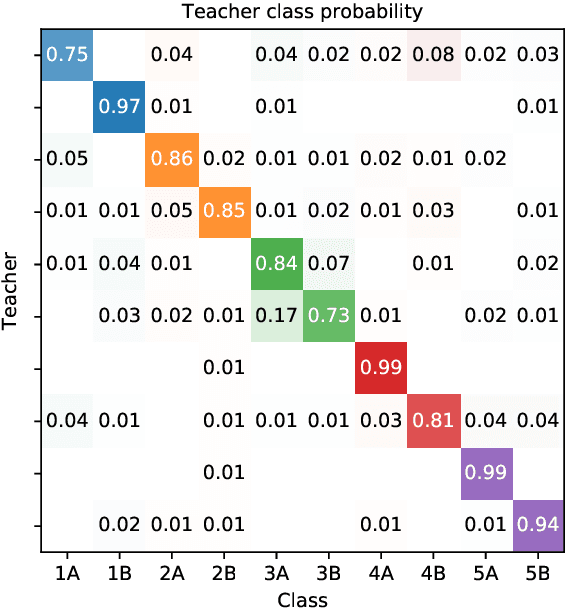
We consider the problem of embedding a dynamic network, to obtain time-evolving vector representations of each node, which can then be used to describe the changes in behaviour of a single node, one or more communities, or the entire graph. Given this open-ended remit, we wish to guarantee stability in the spatio-temporal positioning of the nodes: assigning the same position, up to noise, to nodes behaving similarly at a given time (cross-sectional stability) and a constant position, up to noise, to a single node behaving similarly across different times (longitudinal stability). These properties are defined formally within a generic dynamic latent position model. By showing how this model can be recast as a multilayer random dot product graph, we demonstrate that unfolded adjacency spectral embedding satisfies both stability conditions, allowing, for example, spatio-temporal clustering under the dynamic stochastic block model. We also show how alternative methods, such as omnibus, independent or time-averaged spectral embedding, lack one or the other form of stability.