 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Accuracy: Diagnosing Algebraic Reasoning Failures in LLMs Across Nine Complexity Dimensions
Apr 08, 2026Algebraic reasoning remains one of the most informative stress tests for large language models, yet current benchmarks provide no mechanism for attributing failure to a specific cause. When a model fails an algebraic problem, a single accuracy score cannot reveal whether the expression was too deeply nested, the operator too uncommon, the intermediate state count too high, or the dependency chain too long. Prior work has studied individual failure modes in isolation, but no framework has varied each complexity factor independently under strict experimental control. No prior system has offered automatic generation and verification of problems of increasing complexity to track model progress over time. We introduce a nine-dimension algebraic complexity framework in which each factor is varied independently while all others are held fixed, with problem generation and verification handled by a parametric pipeline requiring no human annotation. Each dimension is grounded in a documented LLM failure mode and captures a structurally distinct aspect of algebraic difficulty, including expression nesting depth, simultaneous intermediate result count, sub-expression complexity, operator hardness, and dependent reasoning chain length. We evaluated seven instruction-tuned models spanning 8B to 235B parameters across all nine dimensions and find that working memory is the dominant scale-invariant bottleneck. Every model collapses between 20 and 30 parallel branches regardless of parameter count, pointing to a hard architectural constraint rather than a solvable capacity limitation. Our analysis further identifies a minimal yet diagnostically sufficient subset of five dimensions that together span the full space of documented algebraic failure modes, providing a complete complexity profile of a model's algebraic reasoning capacity.
Reimplementation of Learning to Reweight Examples for Robust Deep Learning
May 11, 2024



Deep neural networks (DNNs) have been used to create models for many complex analysis problems like image recognition and medical diagnosis. DNNs are a popular tool within machine learning due to their ability to model complex patterns and distributions. However, the performance of these networks is highly dependent on the quality of the data used to train the models. Two characteristics of these sets, noisy labels and training set biases, are known to frequently cause poor generalization performance as a result of overfitting to the training set. This paper aims to solve this problem using the approach proposed by Ren et al. (2018) using meta-training and online weight approximation. We will first implement a toy-problem to crudely verify the claims made by the authors of Ren et al. (2018) and then venture into using the approach to solve a real world problem of Skin-cancer detection using an imbalanced image dataset.
Enhancing Low Resource NER Using Assisting Language And Transfer Learning
Jun 10, 2023



Named Entity Recognition (NER) is a fundamental task in NLP that is used to locate the key information in text and is primarily applied in conversational and search systems. In commercial applications, NER or comparable slot-filling methods have been widely deployed for popular languages. NER is used in applications such as human resources, customer service, search engines, content classification, and academia. In this paper, we draw focus on identifying name entities for low-resource Indian languages that are closely related, like Hindi and Marathi. We use various adaptations of BERT such as baseBERT, AlBERT, and RoBERTa to train a supervised NER model. We also compare multilingual models with monolingual models and establish a baseline. In this work, we show the assisting capabilities of the Hindi and Marathi languages for the NER task. We show that models trained using multiple languages perform better than a single language. However, we also observe that blind mixing of all datasets doesn't necessarily provide improvements and data selection methods may be required.
L3Cube-MahaNER: A Marathi Named Entity Recognition Dataset and BERT models
Apr 12, 2022
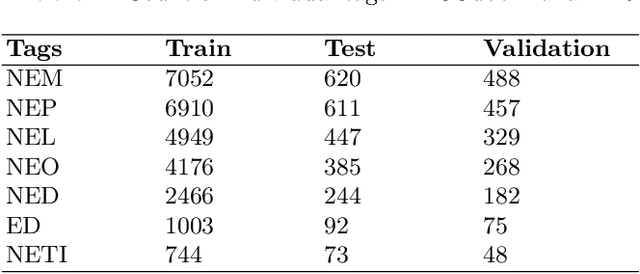
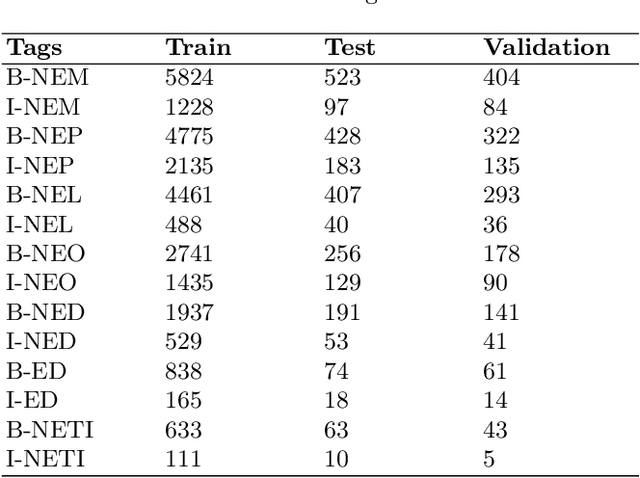
Named Entity Recognition (NER) is a basic NLP task and finds major applications in conversational and search systems. It helps us identify key entities in a sentence used for the downstream application. NER or similar slot filling systems for popular languages have been heavily used in commercial applications. In this work, we focus on Marathi, an Indian language, spoken prominently by the people of Maharashtra state. Marathi is a low resource language and still lacks useful NER resources. We present L3Cube-MahaNER, the first major gold standard named entity recognition dataset in Marathi. We also describe the manual annotation guidelines followed during the process. In the end, we benchmark the dataset on different CNN, LSTM, and Transformer based models like mBERT, XLM-RoBERTa, IndicBERT, MahaBERT, etc. The MahaBERT provides the best performance among all the models. The data and models are available at https://github.com/l3cube-pune/MarathiNLP .
Mono vs Multilingual BERT: A Case Study in Hindi and Marathi Named Entity Recognition
Mar 24, 2022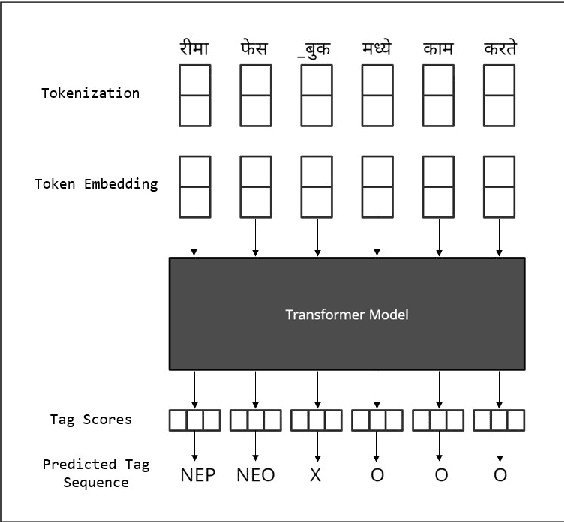

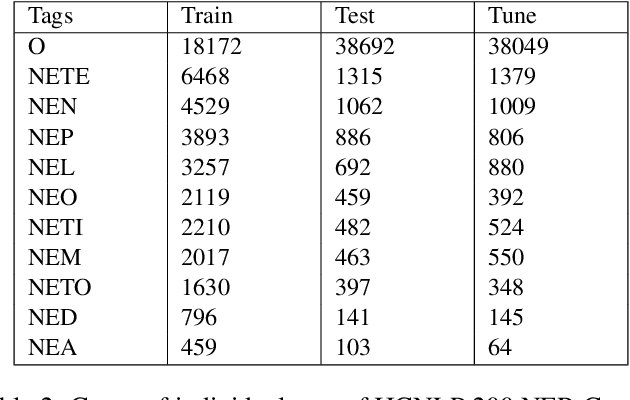
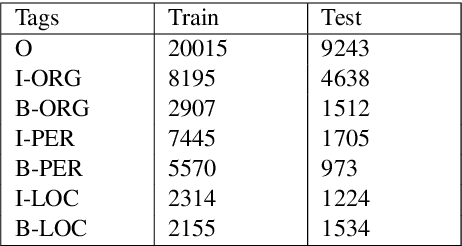
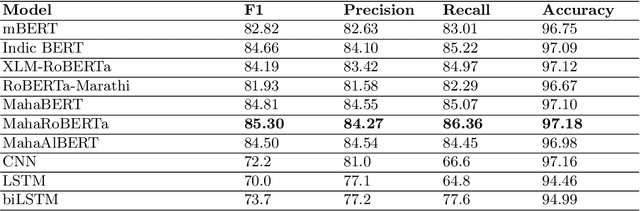
Named entity recognition (NER) is the process of recognising and classifying important information (entities) in text. Proper nouns, such as a person's name, an organization's name, or a location's name, are examples of entities. The NER is one of the important modules in applications like human resources, customer support, search engines, content classification, and academia. In this work, we consider NER for low-resource Indian languages like Hindi and Marathi. The transformer-based models have been widely used for NER tasks. We consider different variations of BERT like base-BERT, RoBERTa, and AlBERT and benchmark them on publicly available Hindi and Marathi NER datasets. We provide an exhaustive comparison of different monolingual and multilingual transformer-based models and establish simple baselines currently missing in the literature. We show that the monolingual MahaRoBERTa model performs the best for Marathi NER whereas the multilingual XLM-RoBERTa performs the best for Hindi NER. We also perform cross-language evaluation and present mixed observations.