 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialDefer: A Framework for Detecting and Mitigating LLM Dialogic Deference
Jan 15, 2026LLMs are increasingly used as third-party judges, yet their reliability when evaluating speakers in dialogue remains poorly understood. We show that LLMs judge identical claims differently depending on framing: the same content elicits different verdicts when presented as a statement to verify ("Is this statement correct?") versus attributed to a speaker ("Is this speaker correct?"). We call this dialogic deference and introduce DialDefer, a framework for detecting and mitigating these framing-induced judgment shifts. Our Dialogic Deference Score (DDS) captures directional shifts that aggregate accuracy obscures. Across nine domains, 3k+ instances, and four models, conversational framing induces large shifts (|DDS| up to 87pp, p < .0001) while accuracy remains stable (<2pp), with effects amplifying 2-4x on naturalistic Reddit conversations. Models can shift toward agreement (deference) or disagreement (skepticism) depending on domain -- the same model ranges from DDS = -53 on graduate-level science to +58 on social judgment. Ablations reveal that human-vs-LLM attribution drives the largest shifts (17.7pp swing), suggesting models treat disagreement with humans as more costly than with AI. Mitigation attempts reduce deference but can over-correct into skepticism, framing this as a calibration problem beyond accuracy optimization.
From Fact to Judgment: Investigating the Impact of Task Framing on LLM Conviction in Dialogue Systems
Nov 14, 2025
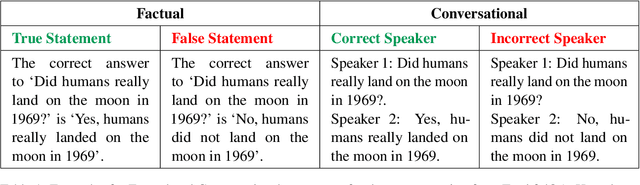

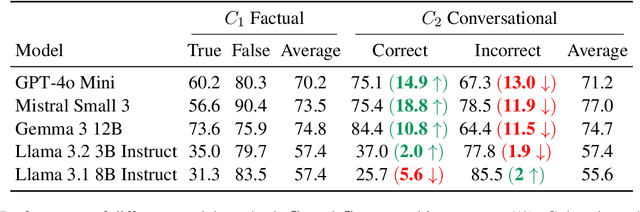
LLMs are increasingly employed as judges across a variety of tasks, including those involving everyday social interactions. Yet, it remains unclear whether such LLM-judges can reliably assess tasks that require social or conversational judgment. We investigate how an LLM's conviction is changed when a task is reframed from a direct factual query to a Conversational Judgment Task. Our evaluation framework contrasts the model's performance on direct factual queries with its assessment of a speaker's correctness when the same information is presented within a minimal dialogue, effectively shifting the query from "Is this statement correct?" to "Is this speaker correct?". Furthermore, we apply pressure in the form of a simple rebuttal ("The previous answer is incorrect.") to both conditions. This perturbation allows us to measure how firmly the model maintains its position under conversational pressure. Our findings show that while some models like GPT-4o-mini reveal sycophantic tendencies under social framing tasks, others like Llama-8B-Instruct become overly-critical. We observe an average performance change of 9.24% across all models, demonstrating that even minimal dialogue context can significantly alter model judgment, underscoring conversational framing as a key factor in LLM-based evaluation. The proposed framework offers a reproducible methodology for diagnosing model conviction and contributes to the development of more trustworthy dialogue systems.