 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhylaFlow: Hybrid Flow Matching in Billera-Holmes-Vogtmann Tree Space for Phylogenetic Inference
May 21, 2026Phylogenetic trees are hybrid objects: branch lengths vary continuously, while topologies change discretely through edge contractions and expansions. Billera-Holmes-Vogtmann (BHV) tree space provides a canonical geometry for this structure, representing each resolved topology as a Euclidean orthant and topological changes as motion across shared lower-dimensional boundaries. We introduce PhylaFlow, a hybrid flow-matching model that learns posterior-basin transport in BHV tree space. PhylaFlow is trained on BHV geodesic paths from random starting trees to short-run posterior samples, coupling continuous branch-length motion within orthants with learned boundary events and discrete topology transitions. We evaluate the learned geometry operationally: if the flow reaches posterior-relevant regions, finite-budget Bayesian refinement initialized from, or guided by, its terminal trees should recover posterior-supported topologies more efficiently. Across DS1-DS8 phylogenetic posterior benchmarks, PhylaFlow substantially reduces initial Tree-KL relative to classical initializers. After finite-budget MrBayes refinement, direct PhylaFlow improves early and intermediate topology-recovery trajectories on most datasets, while split-guided PhylaFlow-MCMC obtains the strongest hard-case results. The best PhylaFlow variant outperforms short-warmup on seven of eight datasets and PhyloGFN on five of eight under the same refinement budget. In a joint sequence-conditioned experiment, sequence embeddings steer posterior split recovery, although exact posterior topology recovery remains preliminary. These results show that hybrid flow matching can learn actionable transport in BHV tree space and provide a geometry-aware proposal mechanism for Bayesian phylogenetic inference.
Equitability Analysis of the Maximal Information Coefficient, with Comparisons
Aug 14, 2013
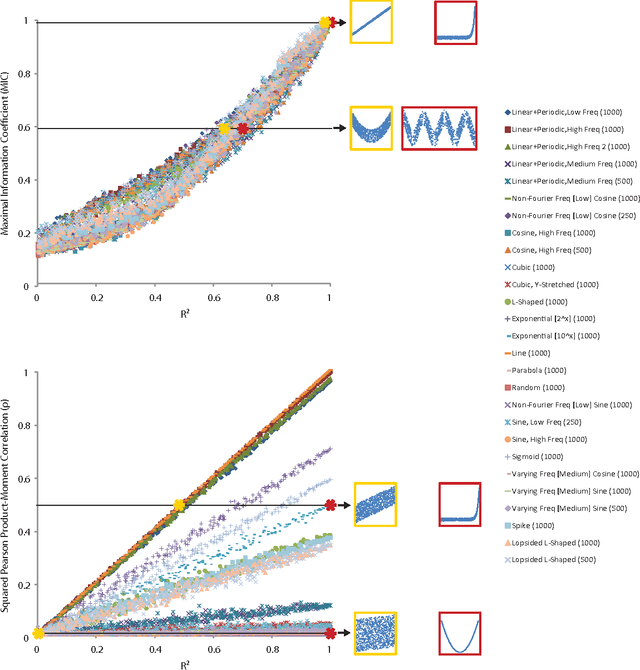
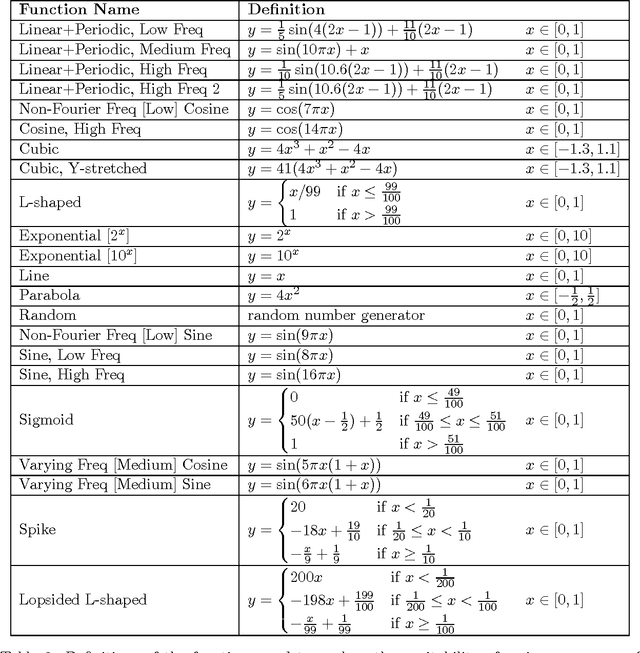
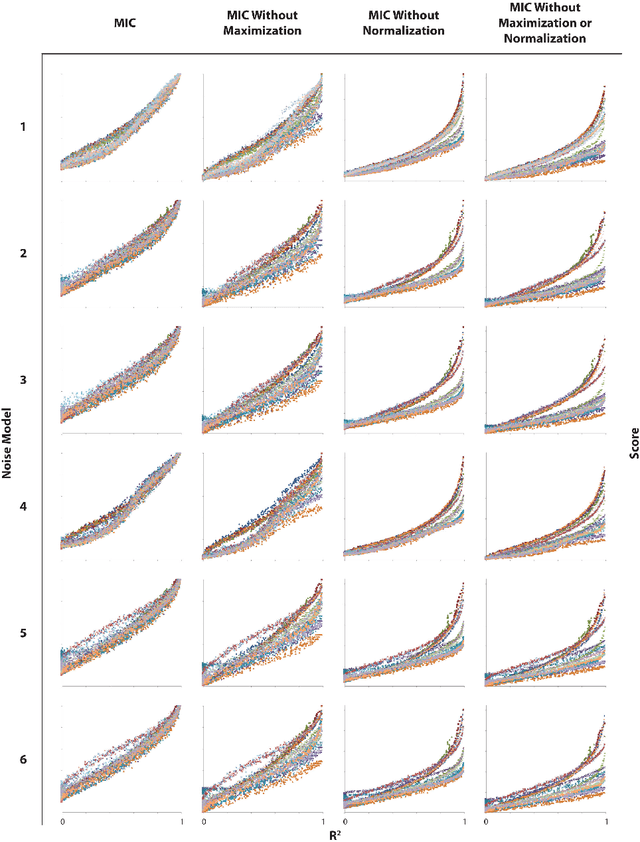
A measure of dependence is said to be equitable if it gives similar scores to equally noisy relationships of different types. Equitability is important in data exploration when the goal is to identify a relatively small set of strongest associations within a dataset as opposed to finding as many non-zero associations as possible, which often are too many to sift through. Thus an equitable statistic, such as the maximal information coefficient (MIC), can be useful for analyzing high-dimensional data sets. Here, we explore both equitability and the properties of MIC, and discuss several aspects of the theory and practice of MIC. We begin by presenting an intuition behind the equitability of MIC through the exploration of the maximization and normalization steps in its definition. We then examine the speed and optimality of the approximation algorithm used to compute MIC, and suggest some directions for improving both. Finally, we demonstrate in a range of noise models and sample sizes that MIC is more equitable than natural alternatives, such as mutual information estimation and distance correlation.