 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-agent Large Language Model Framework to Automatically Assess Performance of a Clinical AI Triage Tool
Oct 30, 2025Purpose: The purpose of this study was to determine if an ensemble of multiple LLM agents could be used collectively to provide a more reliable assessment of a pixel-based AI triage tool than a single LLM. Methods: 29,766 non-contrast CT head exams from fourteen hospitals were processed by a commercial intracranial hemorrhage (ICH) AI detection tool. Radiology reports were analyzed by an ensemble of eight open-source LLM models and a HIPAA compliant internal version of GPT-4o using a single multi-shot prompt that assessed for presence of ICH. 1,726 examples were manually reviewed. Performance characteristics of the eight open-source models and consensus were compared to GPT-4o. Three ideal consensus LLM ensembles were tested for rating the performance of the triage tool. Results: The cohort consisted of 29,766 head CTs exam-report pairs. The highest AUC performance was achieved with llama3.3:70b and GPT-4o (AUC= 0.78). The average precision was highest for Llama3.3:70b and GPT-4o (AP=0.75 & 0.76). Llama3.3:70b had the highest F1 score (0.81) and recall (0.85), greater precision (0.78), specificity (0.72), and MCC (0.57). Using MCC (95% CI) the ideal combination of LLMs were: Full-9 Ensemble 0.571 (0.552-0.591), Top-3 Ensemble 0.558 (0.537-0.579), Consensus 0.556 (0.539-0.574), and GPT4o 0.522 (0.500-0.543). No statistically significant differences were observed between Top-3, Full-9, and Consensus (p > 0.05). Conclusion: An ensemble of medium to large sized open-source LLMs provides a more consistent and reliable method to derive a ground truth retrospective evaluation of a clinical AI triage tool over a single LLM alone.
Generalization of Artificial Intelligence Models in Medical Imaging: A Case-Based Review
Nov 15, 2022


The discussions around Artificial Intelligence (AI) and medical imaging are centered around the success of deep learning algorithms. As new algorithms enter the market, it is important for practicing radiologists to understand the pitfalls of various AI algorithms. This entails having a basic understanding of how algorithms are developed, the kind of data they are trained on, and the settings in which they will be deployed. As with all new technologies, use of AI should be preceded by a fundamental understanding of the risks and benefits to those it is intended to help. This case-based review is intended to point out specific factors practicing radiologists who intend to use AI should consider.
Automated Segmentation of Vertebrae on Lateral Chest Radiography Using Deep Learning
Jan 05, 2020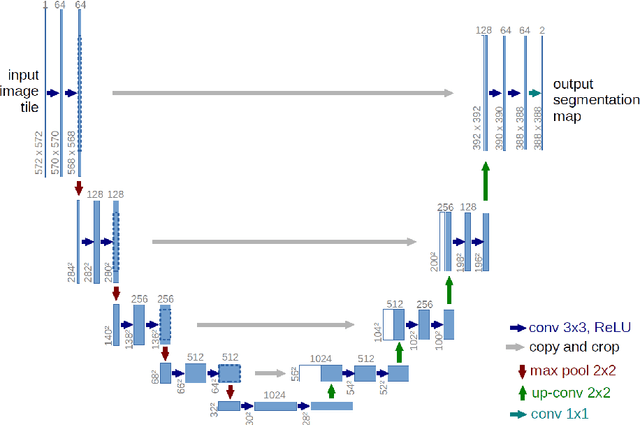
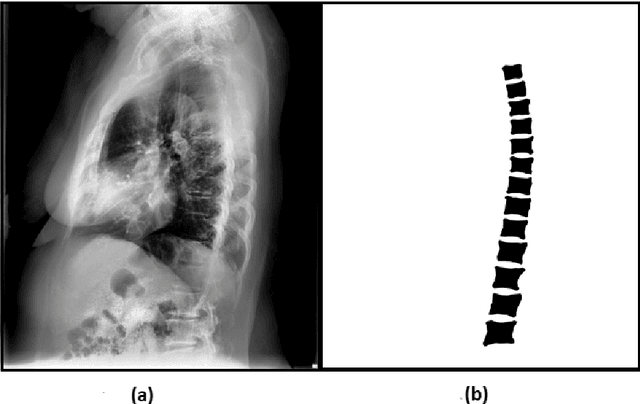
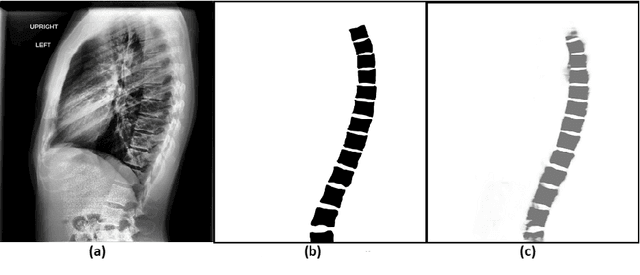
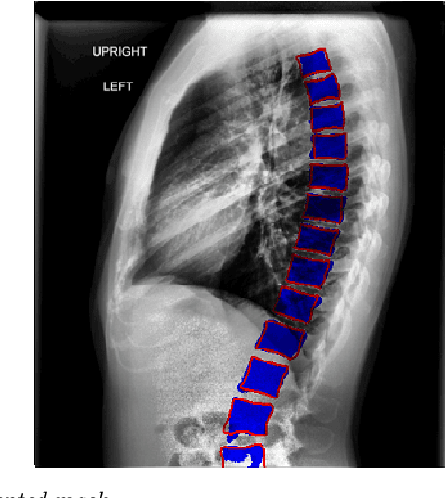
The purpose of this study is to develop an automated algorithm for thoracic vertebral segmentation on chest radiography using deep learning. 124 de-identified lateral chest radiographs on unique patients were obtained. Segmentations of visible vertebrae were manually performed by a medical student and verified by a board-certified radiologist. 74 images were used for training, 10 for validation, and 40 were held out for testing. A U-Net deep convolutional neural network was employed for segmentation, using the sum of dice coefficient and binary cross-entropy as the loss function. On the test set, the algorithm demonstrated an average dice coefficient value of 90.5 and an average intersection-over-union (IoU) of 81.75. Deep learning demonstrates promise in the segmentation of vertebrae on lateral chest radiography.
Application of Deep Learning in Neuroradiology: Automated Detection of Basal Ganglia Hemorrhage using 2D-Convolutional Neural Networks
Oct 27, 2017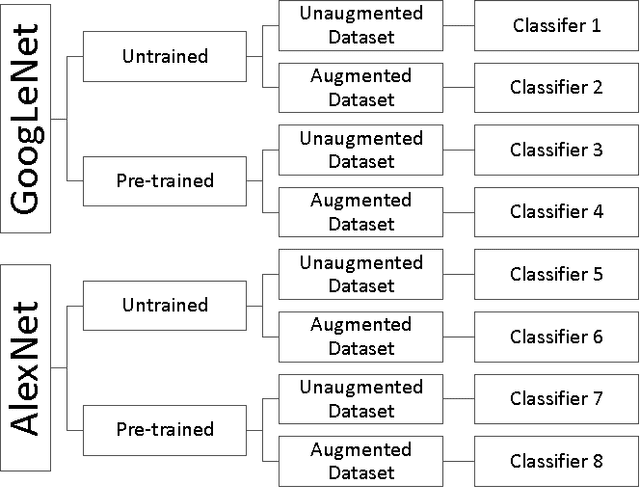
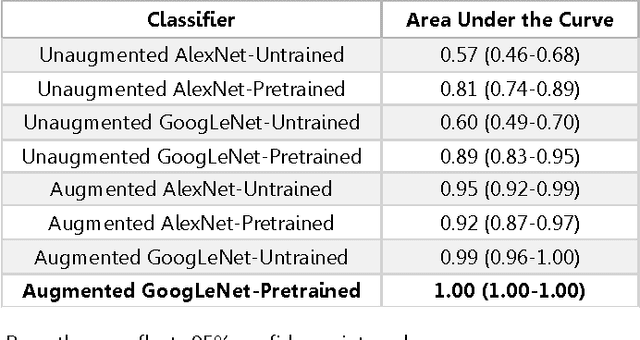
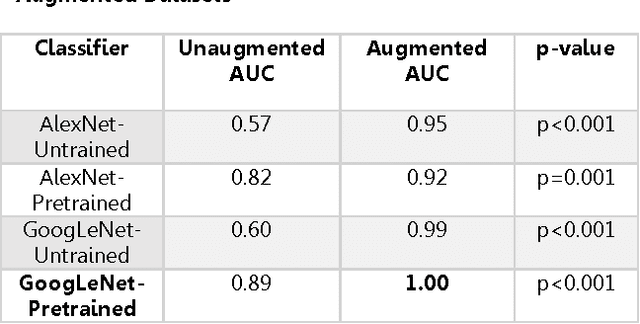
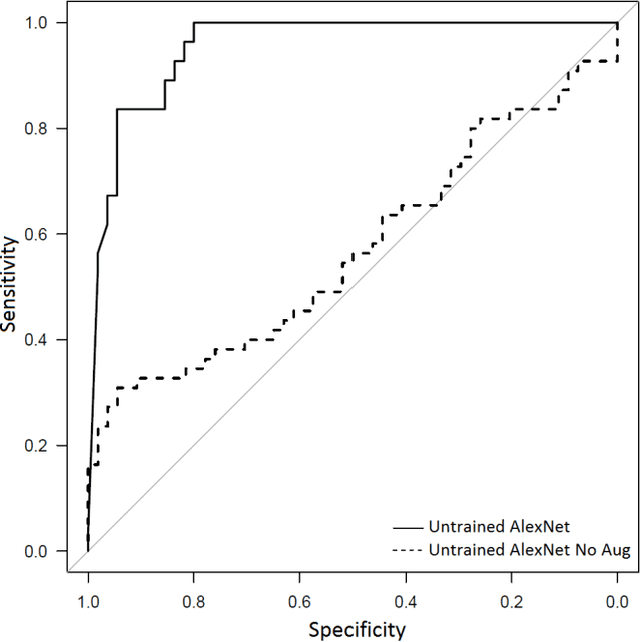
Background: Deep learning techniques have achieved high accuracy in image classification tasks, and there is interest in applicability to neuroimaging critical findings. This study evaluates the efficacy of 2D deep convolutional neural networks (DCNNs) for detecting basal ganglia (BG) hemorrhage on noncontrast head CT. Materials and Methods: 170 unique de-identified HIPAA-compliant noncontrast head CTs were obtained, those with and without BG hemorrhage. 110 cases were held-out for test, and 60 were split into training (45) and validation (15), consisting of 20 right, 20 left, and 20 no BG hemorrhage. Data augmentation was performed to increase size and variation of the training dataset by 48-fold. Two DCNNs were used to classify the images-AlexNet and GoogLeNet-using untrained networks and those pre-trained on ImageNet. Area under the curves (AUC) for the receiver-operator characteristic (ROC) curves were calculated, using the DeLong method for statistical comparison of ROCs. Results: The best performing model was the pre-trained augmented GoogLeNet, which had an AUC of 1.00 in classification of hemorrhage. Preprocessing augmentation increased accuracy for all networks (p<0.001), and pretrained networks outperformed untrained ones (p<0.001) for the unaugmented models. The best performing GoogLeNet model (AUC 1.00) outperformed the best performing AlexNet model (AUC 0.95)(p=0.01). Conclusion: For this dataset, the best performing DCNN identified BG hemorrhage on noncontrast head CT with an AUC of 1.00. Pretrained networks and data augmentation increased classifier accuracy. Future prospective research would be important to determine if the accuracy can be maintained on a larger cohort of patients and for very small hemorrhages.