 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaVeRL-SQL: Text-to-SQL via Partial-Match Rewards and Verbal Reinforcement Learning
Sep 08, 2025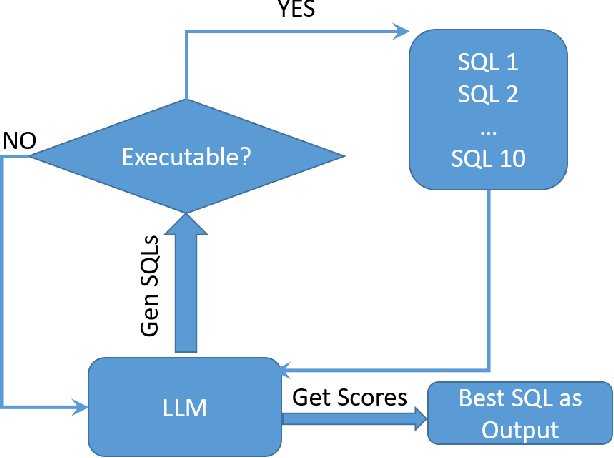
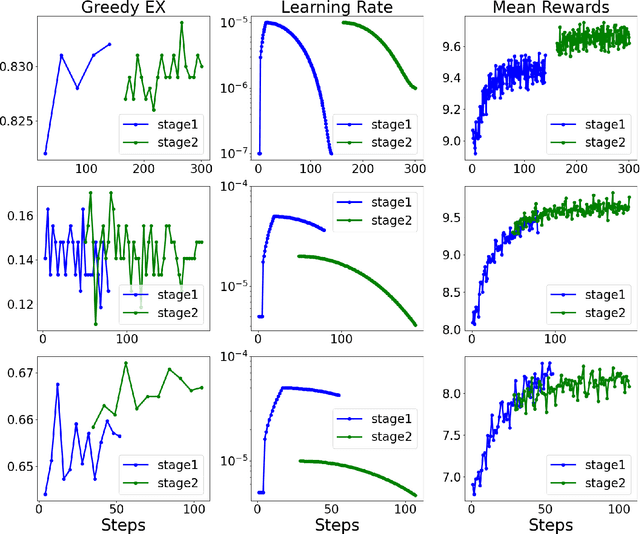
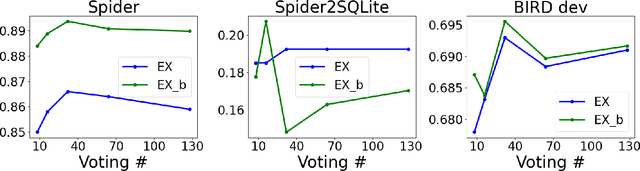
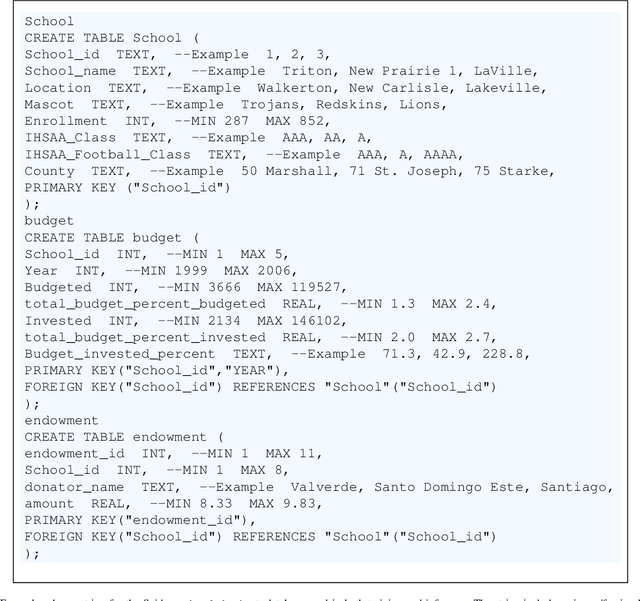
Text-to-SQL models allow users to interact with a database more easily by generating executable SQL statements from natural-language questions. Despite recent successes on simpler databases and questions, current Text-to-SQL methods still suffer from low execution accuracy on industry-scale databases and complex questions involving domain-specific business logic. We present \emph{PaVeRL-SQL}, a framework that combines \emph{Partial-Match Rewards} and \emph{Verbal Reinforcement Learning} to drive self-improvement in reasoning language models (RLMs) for Text-to-SQL. To handle practical use cases, we adopt two pipelines: (1) a newly designed in-context learning framework with group self-evaluation (verbal-RL), using capable open- and closed-source large language models (LLMs) as backbones; and (2) a chain-of-thought (CoT) RL pipeline with a small backbone model (OmniSQL-7B) trained with a specially designed reward function and two-stage RL. These pipelines achieve state-of-the-art (SOTA) results on popular Text-to-SQL benchmarks -- Spider, Spider 2.0, and BIRD. For the industrial-level Spider2.0-SQLite benchmark, the verbal-RL pipeline achieves an execution accuracy 7.4\% higher than SOTA, and the CoT pipeline is 1.4\% higher. RL training with mixed SQL dialects yields strong, threefold gains, particularly for dialects with limited training data. Overall, \emph{PaVeRL-SQL} delivers reliable, SOTA Text-to-SQL under realistic industrial constraints. The code is available at https://github.com/PaVeRL-SQL/PaVeRL-SQL.
Is Everything Fine, Grandma? Acoustic and Linguistic Modeling for Robust Elderly Speech Emotion Recognition
Sep 07, 2020
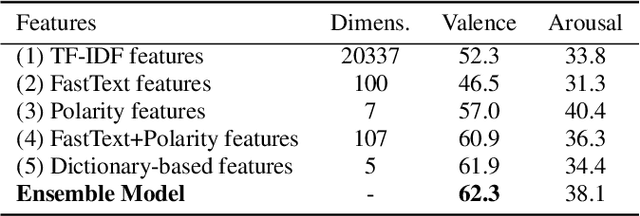

Acoustic and linguistic analysis for elderly emotion recognition is an under-studied and challenging research direction, but essential for the creation of digital assistants for the elderly, as well as unobtrusive telemonitoring of elderly in their residences for mental healthcare purposes. This paper presents our contribution to the INTERSPEECH 2020 Computational Paralinguistics Challenge (ComParE) - Elderly Emotion Sub-Challenge, which is comprised of two ternary classification tasks for arousal and valence recognition. We propose a bi-modal framework, where these tasks are modeled using state-of-the-art acoustic and linguistic features, respectively. In this study, we demonstrate that exploiting task-specific dictionaries and resources can boost the performance of linguistic models, when the amount of labeled data is small. Observing a high mismatch between development and test set performances of various models, we also propose alternative training and decision fusion strategies to better estimate and improve the generalization performance.