 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaVeRL-SQL: Text-to-SQL via Partial-Match Rewards and Verbal Reinforcement Learning
Sep 08, 2025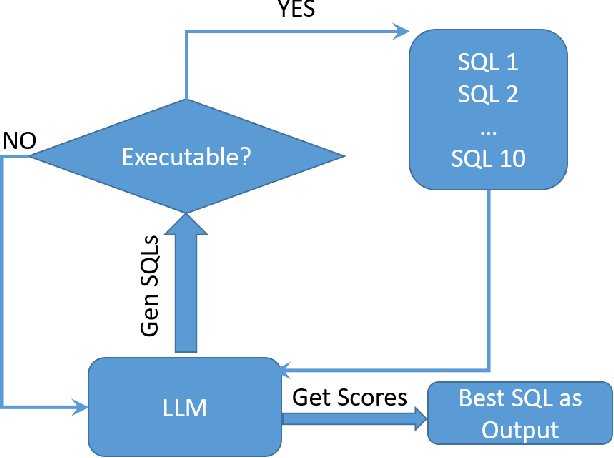
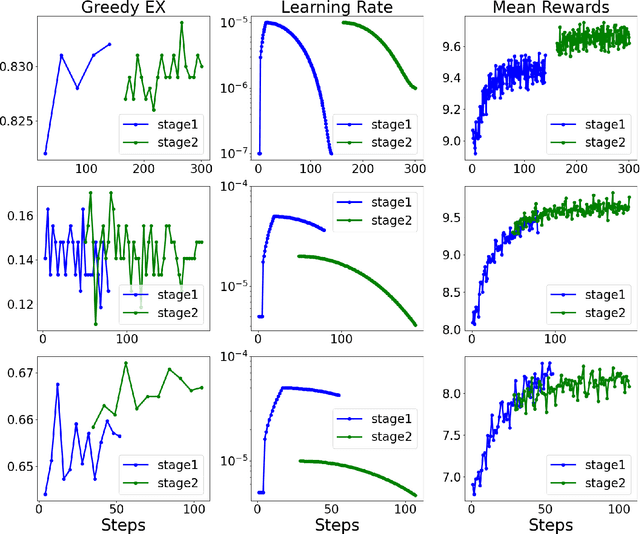
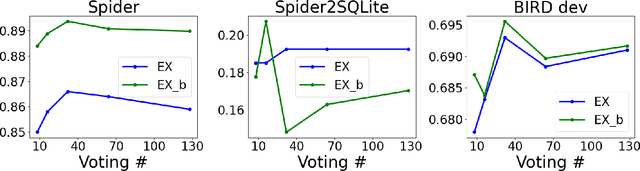
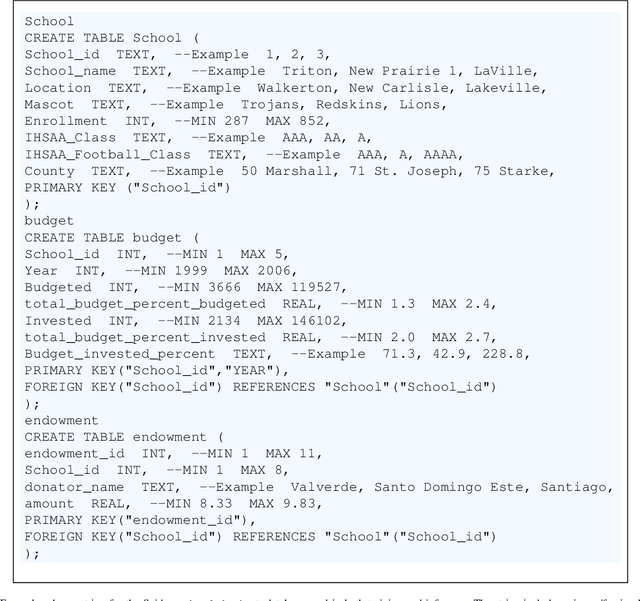
Text-to-SQL models allow users to interact with a database more easily by generating executable SQL statements from natural-language questions. Despite recent successes on simpler databases and questions, current Text-to-SQL methods still suffer from low execution accuracy on industry-scale databases and complex questions involving domain-specific business logic. We present \emph{PaVeRL-SQL}, a framework that combines \emph{Partial-Match Rewards} and \emph{Verbal Reinforcement Learning} to drive self-improvement in reasoning language models (RLMs) for Text-to-SQL. To handle practical use cases, we adopt two pipelines: (1) a newly designed in-context learning framework with group self-evaluation (verbal-RL), using capable open- and closed-source large language models (LLMs) as backbones; and (2) a chain-of-thought (CoT) RL pipeline with a small backbone model (OmniSQL-7B) trained with a specially designed reward function and two-stage RL. These pipelines achieve state-of-the-art (SOTA) results on popular Text-to-SQL benchmarks -- Spider, Spider 2.0, and BIRD. For the industrial-level Spider2.0-SQLite benchmark, the verbal-RL pipeline achieves an execution accuracy 7.4\% higher than SOTA, and the CoT pipeline is 1.4\% higher. RL training with mixed SQL dialects yields strong, threefold gains, particularly for dialects with limited training data. Overall, \emph{PaVeRL-SQL} delivers reliable, SOTA Text-to-SQL under realistic industrial constraints. The code is available at https://github.com/PaVeRL-SQL/PaVeRL-SQL.
Improving Instruction Following in Language Models through Proxy-Based Uncertainty Estimation
May 10, 2024



Assessing response quality to instructions in language models is vital but challenging due to the complexity of human language across different contexts. This complexity often results in ambiguous or inconsistent interpretations, making accurate assessment difficult. To address this issue, we propose a novel Uncertainty-aware Reward Model (URM) that introduces a robust uncertainty estimation for the quality of paired responses based on Bayesian approximation. Trained with preference datasets, our uncertainty-enabled proxy not only scores rewards for responses but also evaluates their inherent uncertainty. Empirical results demonstrate significant benefits of incorporating the proposed proxy into language model training. Our method boosts the instruction following capability of language models by refining data curation for training and improving policy optimization objectives, thereby surpassing existing methods by a large margin on benchmarks such as Vicuna and MT-bench. These findings highlight that our proposed approach substantially advances language model training and paves a new way of harnessing uncertainty within language models.