 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Preferences for Brands and Cultures in LLMs
Mar 18, 2026Large language models (LLMs) based AI systems increasingly mediate what billions of people see, choose and buy. This creates an urgent need to quantify the systemic risks of LLM-driven market intermediation, including its implications for market fairness, competition, and the diversity of information exposure. This paper introduces ChoiceEval, a reproducible framework for auditing preferences for brands and cultures in large language models (LLMs) under realistic usage conditions. ChoiceEval addresses two core technical challenges: (i) generating realistic, persona-diverse evaluation queries and (ii) converting free-form outputs into comparable choice sets and quantitative preference metrics. For a given topic (e.g. running shoes, hotel chains, travel destinations), the framework segments users into psychographic profiles (e.g., budget-conscious, wellness-focused, convenience), and then derives diverse prompts that reflect real-world advice-seeking and decision-making behaviour. LLM responses are converted into normalised top-k choice sets. Preference and geographic bias are then quantified using comparable metrics across topics and personas. Thus, ChoiceEval provides a scalable audit pipeline for researchers, platforms, and regulators, linking model behaviour to real-world economic outcomes. Applied to Gemini, GPT, and DeepSeek across 10 topics spanning commerce and culture and more than 2,000 questions, ChoiceEval reveals consistent preferences: U.S.-developed models Gemini and GPT show marked favouritism toward American entities, while China-developed DeepSeek exhibits more balanced yet still detectable geographic preferences. These patterns persist across user personas, suggesting systematic rather than incidental effects.
Human Pose Estimation from RGB Input Using Synthetic Training Data
May 27, 2014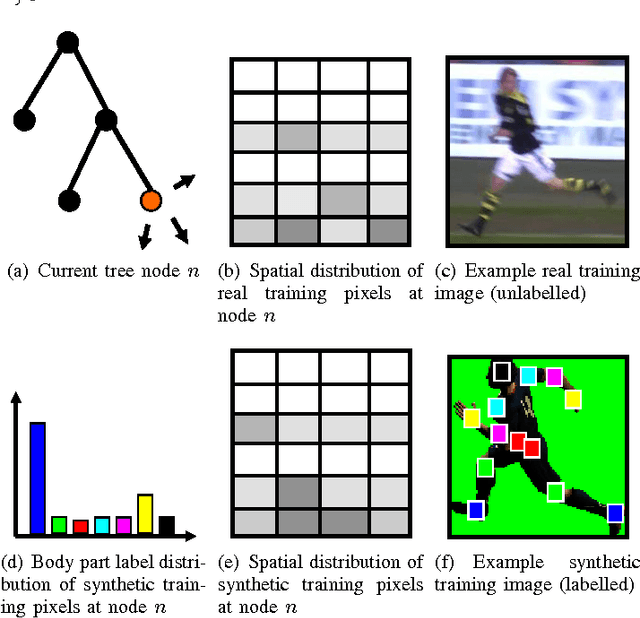
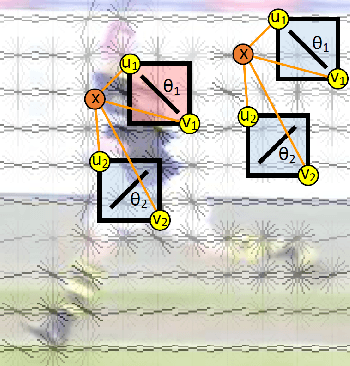

We address the problem of estimating the pose of humans using RGB image input. More specifically, we are using a random forest classifier to classify pixels into joint-based body part categories, much similar to the famous Kinect pose estimator [11], [12]. However, we are using pure RGB input, i.e. no depth. Since the random forest requires a large number of training examples, we are using computer graphics generated, synthetic training data. In addition, we assume that we have access to a large number of real images with bounding box labels, extracted for example by a pedestrian detector or a tracking system. We propose a new objective function for random forest training that uses the weakly labeled data from the target domain to encourage the learner to select features that generalize from the synthetic source domain to the real target domain. We demonstrate on a publicly available dataset [6] that the proposed objective function yields a classifier that significantly outperforms a baseline classifier trained using the standard entropy objective [10].