 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2FaceGAN: Face Generation from Fine Grained Textual Descriptions
Nov 26, 2019
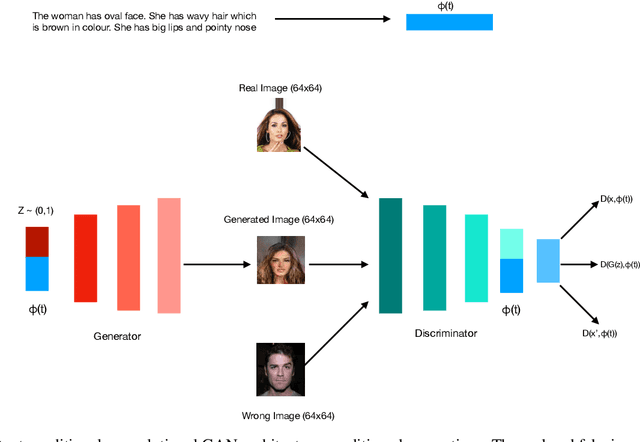

Powerful generative adversarial networks (GAN) have been developed to automatically synthesize realistic images from text. However, most existing tasks are limited to generating simple images such as flowers from captions. In this work, we extend this problem to the less addressed domain of face generation from fine-grained textual descriptions of face, e.g., "A person has curly hair, oval face, and mustache". We are motivated by the potential of automated face generation to impact and assist critical tasks such as criminal face reconstruction. Since current datasets for the task are either very small or do not contain captions, we generate captions for images in the CelebA dataset by creating an algorithm to automatically convert a list of attributes to a set of captions. We then model the highly multi-modal problem of text to face generation as learning the conditional distribution of faces (conditioned on text) in same latent space. We utilize the current state-of-the-art GAN (DC-GAN with GAN-CLS loss) for learning conditional multi-modality. The presence of more fine-grained details and variable length of the captions makes the problem easier for a user but more difficult to handle compared to the other text-to-image tasks. We flipped the labels for real and fake images and added noise in discriminator. Generated images for diverse textual descriptions show promising results. In the end, we show how the widely used inceptions score is not a good metric to evaluate the performance of generative models used for synthesizing faces from text.