 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopologies of Reasoning: Demystifying Chains, Trees, and Graphs of Thoughts
Jan 25, 2024The field of natural language processing (NLP) has witnessed significant progress in recent years, with a notable focus on improving large language models' (LLM) performance through innovative prompting techniques. Among these, prompt engineering coupled with structures has emerged as a promising paradigm, with designs such as Chain-of-Thought, Tree of Thoughts, or Graph of Thoughts, in which the overall LLM reasoning is guided by a structure such as a graph. As illustrated with numerous examples, this paradigm significantly enhances the LLM's capability to solve numerous tasks, ranging from logical or mathematical reasoning to planning or creative writing. To facilitate the understanding of this growing field and pave the way for future developments, we devise a general blueprint for effective and efficient LLM reasoning schemes. For this, we conduct an in-depth analysis of the prompt execution pipeline, clarifying and clearly defining different concepts. We then build the first taxonomy of structure-enhanced LLM reasoning schemes. We focus on identifying fundamental classes of harnessed structures, and we analyze the representations of these structures, algorithms executed with these structures, and many others. We refer to these structures as reasoning topologies, because their representation becomes to a degree spatial, as they are contained within the LLM context. Our study compares existing prompting schemes using the proposed taxonomy, discussing how certain design choices lead to different patterns in performance and cost. We also outline theoretical underpinnings, relationships between prompting and others parts of the LLM ecosystem such as knowledge bases, and the associated research challenges. Our work will help to advance future prompt engineering techniques.
TransPimLib: A Library for Efficient Transcendental Functions on Processing-in-Memory Systems
Apr 23, 2023



Processing-in-memory (PIM) promises to alleviate the data movement bottleneck in modern computing systems. However, current real-world PIM systems have the inherent disadvantage that their hardware is more constrained than in conventional processors (CPU, GPU), due to the difficulty and cost of building processing elements near or inside the memory. As a result, general-purpose PIM architectures support fairly limited instruction sets and struggle to execute complex operations such as transcendental functions and other hard-to-calculate operations (e.g., square root). These operations are particularly important for some modern workloads, e.g., activation functions in machine learning applications. In order to provide support for transcendental (and other hard-to-calculate) functions in general-purpose PIM systems, we present \emph{TransPimLib}, a library that provides CORDIC-based and LUT-based methods for trigonometric functions, hyperbolic functions, exponentiation, logarithm, square root, etc. We develop an implementation of TransPimLib for the UPMEM PIM architecture and perform a thorough evaluation of TransPimLib's methods in terms of performance and accuracy, using microbenchmarks and three full workloads (Blackscholes, Sigmoid, Softmax). We open-source all our code and datasets at~\url{https://github.com/CMU-SAFARI/transpimlib}.
RedBit: An End-to-End Flexible Framework for Evaluating the Accuracy of Quantized CNNs
Jan 15, 2023



In recent years, Convolutional Neural Networks (CNNs) have become the standard class of deep neural network for image processing, classification and segmentation tasks. However, the large strides in accuracy obtained by CNNs have been derived from increasing the complexity of network topologies, which incurs sizeable performance and energy penalties in the training and inference of CNNs. Many recent works have validated the effectiveness of parameter quantization, which consists in reducing the bit width of the network's parameters, to enable the attainment of considerable performance and energy efficiency gains without significantly compromising accuracy. However, it is difficult to compare the relative effectiveness of different quantization methods. To address this problem, we introduce RedBit, an open-source framework that provides a transparent, extensible and easy-to-use interface to evaluate the effectiveness of different algorithms and parameter configurations on network accuracy. We use RedBit to perform a comprehensive survey of five state-of-the-art quantization methods applied to the MNIST, CIFAR-10 and ImageNet datasets. We evaluate a total of 2300 individual bit width combinations, independently tuning the width of the network's weight and input activation parameters, from 32 bits down to 1 bit (e.g., 8/8, 2/2, 1/32, 1/1, for weights/activations). Upwards of 20000 hours of computing time in a pool of state-of-the-art GPUs were used to generate all the results in this paper. For 1-bit quantization, the accuracy losses for the MNIST, CIFAR-10 and ImageNet datasets range between [0.26%, 0.79%], [9.74%, 32.96%] and [10.86%, 47.36%] top-1, respectively. We actively encourage the reader to download the source code and experiment with RedBit, and to submit their own observed results to our public repository, available at https://github.com/IT-Coimbra/RedBit.
TargetCall: Eliminating the Wasted Computation in Basecalling via Pre-Basecalling Filtering
Dec 09, 2022Basecalling is an essential step in nanopore sequencing analysis where the raw signals of nanopore sequencers are converted into nucleotide sequences, i.e., reads. State-of-the-art basecallers employ complex deep learning models to achieve high basecalling accuracy. This makes basecalling computationally-inefficient and memory-hungry; bottlenecking the entire genome analysis pipeline. However, for many applications, the majority of reads do no match the reference genome of interest (i.e., target reference) and thus are discarded in later steps in the genomics pipeline, wasting the basecalling computation. To overcome this issue, we propose TargetCall, the first fast and widely-applicable pre-basecalling filter to eliminate the wasted computation in basecalling. TargetCall's key idea is to discard reads that will not match the target reference (i.e., off-target reads) prior to basecalling. TargetCall consists of two main components: (1) LightCall, a lightweight neural network basecaller that produces noisy reads; and (2) Similarity Check, which labels each of these noisy reads as on-target or off-target by matching them to the target reference. TargetCall filters out all off-target reads before basecalling; and the highly-accurate but slow basecalling is performed only on the raw signals whose noisy reads are labeled as on-target. Our thorough experimental evaluations using both real and simulated data show that TargetCall 1) improves the end-to-end basecalling performance of the state-of-the-art basecaller by 3.31x while maintaining high (98.88%) sensitivity in keeping on-target reads, 2) maintains high accuracy in downstream analysis, 3) precisely filters out up to 94.71% of off-target reads, and 4) achieves better performance, sensitivity, and generality compared to prior works. We freely open-source TargetCall at https://github.com/CMU-SAFARI/TargetCall.
NEON: Enabling Efficient Support for Nonlinear Operations in Resistive RAM-based Neural Network Accelerators
Nov 10, 2022Resistive Random-Access Memory (RRAM) is well-suited to accelerate neural network (NN) workloads as RRAM-based Processing-in-Memory (PIM) architectures natively support highly-parallel multiply-accumulate (MAC) operations that form the backbone of most NN workloads. Unfortunately, NN workloads such as transformers require support for non-MAC operations (e.g., softmax) that RRAM cannot provide natively. Consequently, state-of-the-art works either integrate additional digital logic circuits to support the non-MAC operations or offload the non-MAC operations to CPU/GPU, resulting in significant performance and energy efficiency overheads due to data movement. In this work, we propose NEON, a novel compiler optimization to enable the end-to-end execution of the NN workload in RRAM. The key idea of NEON is to transform each non-MAC operation into a lightweight yet highly-accurate neural network. Utilizing neural networks to approximate the non-MAC operations provides two advantages: 1) We can exploit the key strength of RRAM, i.e., highly-parallel MAC operation, to flexibly and efficiently execute non-MAC operations in memory. 2) We can simplify RRAM's microarchitecture by eliminating the additional digital logic circuits while reducing the data movement overheads. Acceleration of the non-MAC operations in memory enables NEON to achieve a 2.28x speedup compared to an idealized digital logic-based RRAM. We analyze the trade-offs associated with the transformation and demonstrate feasible use cases for NEON across different substrates.
Accelerating Neural Network Inference with Processing-in-DRAM: From the Edge to the Cloud
Sep 19, 2022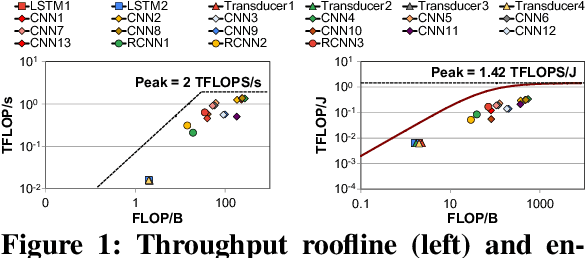
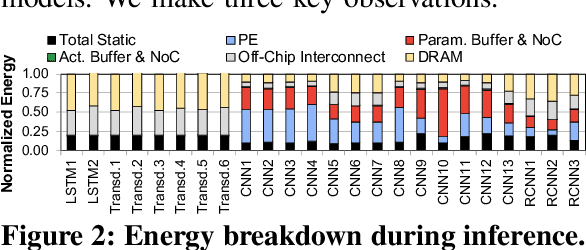
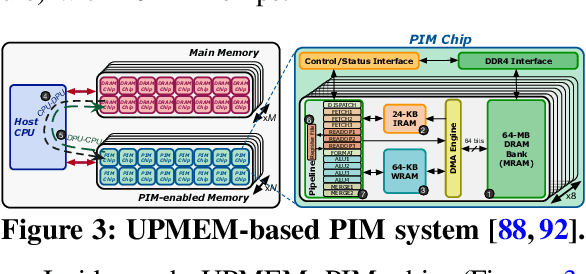
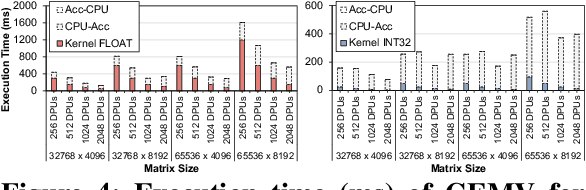
Neural networks (NNs) are growing in importance and complexity. A neural network's performance (and energy efficiency) can be bound either by computation or memory resources. The processing-in-memory (PIM) paradigm, where computation is placed near or within memory arrays, is a viable solution to accelerate memory-bound NNs. However, PIM architectures vary in form, where different PIM approaches lead to different trade-offs. Our goal is to analyze, discuss, and contrast DRAM-based PIM architectures for NN performance and energy efficiency. To do so, we analyze three state-of-the-art PIM architectures: (1) UPMEM, which integrates processors and DRAM arrays into a single 2D chip; (2) Mensa, a 3D-stack-based PIM architecture tailored for edge devices; and (3) SIMDRAM, which uses the analog principles of DRAM to execute bit-serial operations. Our analysis reveals that PIM greatly benefits memory-bound NNs: (1) UPMEM provides 23x the performance of a high-end GPU when the GPU requires memory oversubscription for a general matrix-vector multiplication kernel; (2) Mensa improves energy efficiency and throughput by 3.0x and 3.1x over the Google Edge TPU for 24 Google edge NN models; and (3) SIMDRAM outperforms a CPU/GPU by 16.7x/1.4x for three binary NNs. We conclude that the ideal PIM architecture for NN models depends on a model's distinct attributes, due to the inherent architectural design choices.
LEAPER: Modeling Cloud FPGA-based Systems via Transfer Learning
Aug 22, 2022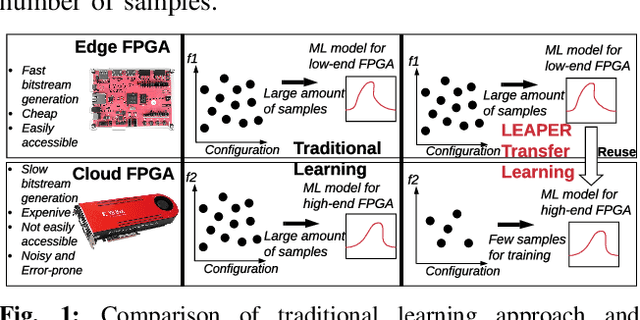
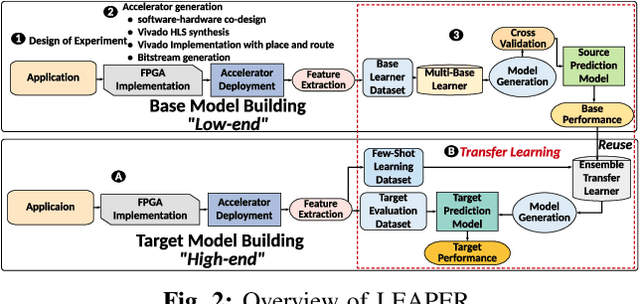
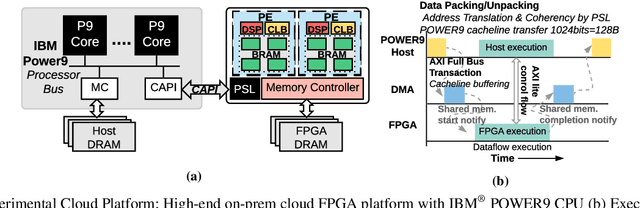
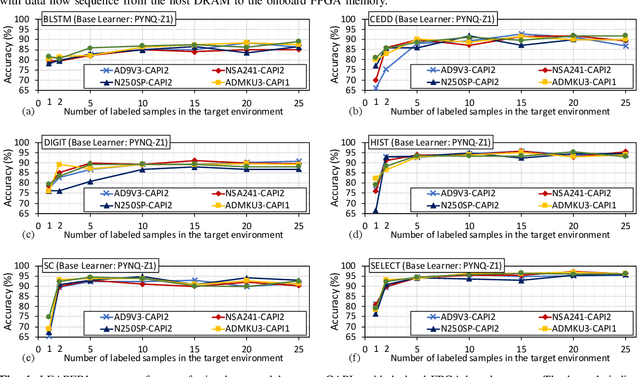
Machine-learning-based models have recently gained traction as a way to overcome the slow downstream implementation process of FPGAs by building models that provide fast and accurate performance predictions. However, these models suffer from two main limitations: (1) training requires large amounts of data (features extracted from FPGA synthesis and implementation reports), which is cost-inefficient because of the time-consuming FPGA design cycle; (2) a model trained for a specific environment cannot predict for a new, unknown environment. In a cloud system, where getting access to platforms is typically costly, data collection for ML models can significantly increase the total cost-ownership (TCO) of a system. To overcome these limitations, we propose LEAPER, a transfer learning-based approach for FPGA-based systems that adapts an existing ML-based model to a new, unknown environment to provide fast and accurate performance and resource utilization predictions. Experimental results show that our approach delivers, on average, 85% accuracy when we use our transferred model for prediction in a cloud environment with 5-shot learning and reduces design-space exploration time by 10x, from days to only a few hours.
ApHMM: Accelerating Profile Hidden Markov Models for Fast and Energy-Efficient Genome Analysis
Jul 20, 2022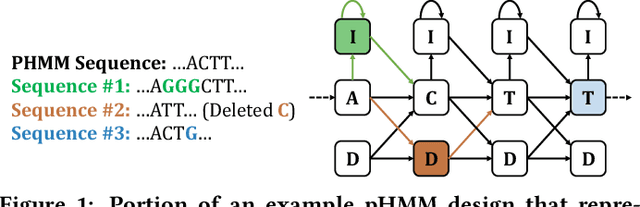
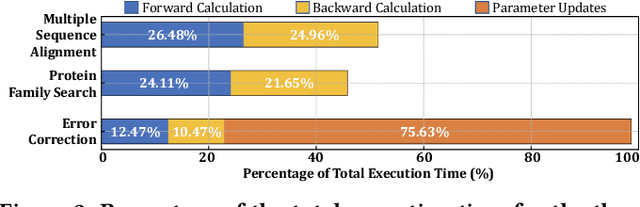
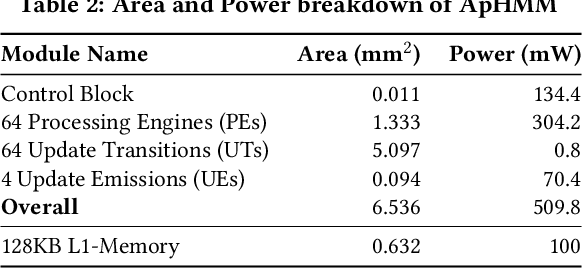
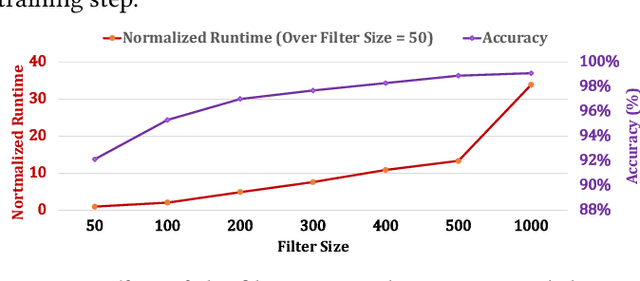
Profile hidden Markov models (pHMMs) are widely used in many bioinformatics applications to accurately identify similarities between biological sequences (e.g., DNA or protein sequences). PHMMs use a commonly-adopted and highly-accurate method, called the Baum-Welch algorithm, to calculate these similarities. However, the Baum-Welch algorithm is computationally expensive, and existing works provide either software- or hardware-only solutions for a fixed pHMM design. When we analyze the state-of-the-art works, we find that there is a pressing need for a flexible, high-performant, and energy-efficient hardware-software co-design to efficiently and effectively solve all the major inefficiencies in the Baum-Welch algorithm for pHMMs. We propose ApHMM, the first flexible acceleration framework that can significantly reduce computational and energy overheads of the Baum-Welch algorithm for pHMMs. ApHMM leverages hardware-software co-design to solve the major inefficiencies in the Baum-Welch algorithm by 1) designing a flexible hardware to support different pHMMs designs, 2) exploiting the predictable data dependency pattern in an on-chip memory with memoization techniques, 3) quickly eliminating negligible computations with a hardware-based filter, and 4) minimizing the redundant computations. We implement our 1) hardware-software optimizations on a specialized hardware and 2) software optimizations for GPUs to provide the first flexible Baum-Welch accelerator for pHMMs. ApHMM provides significant speedups of 15.55x-260.03x, 1.83x-5.34x, and 27.97x compared to CPU, GPU, and FPGA implementations of the Baum-Welch algorithm, respectively. ApHMM outperforms the state-of-the-art CPU implementations of three important bioinformatics applications, 1) error correction, 2) protein family search, and 3) multiple sequence alignment, by 1.29x-59.94x, 1.03x-1.75x, and 1.03x-1.95x, respectively.
An Experimental Evaluation of Machine Learning Training on a Real Processing-in-Memory System
Jul 16, 2022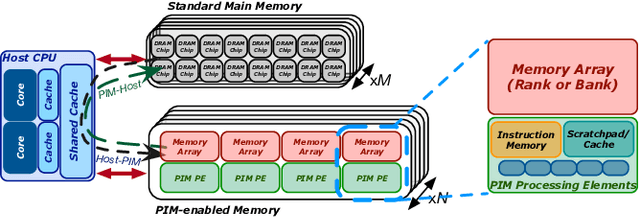
Training machine learning (ML) algorithms is a computationally intensive process, which is frequently memory-bound due to repeatedly accessing large training datasets. As a result, processor-centric systems (e.g., CPU, GPU) suffer from costly data movement between memory units and processing units, which consumes large amounts of energy and execution cycles. Memory-centric computing systems, i.e., with processing-in-memory (PIM) capabilities, can alleviate this data movement bottleneck. Our goal is to understand the potential of modern general-purpose PIM architectures to accelerate ML training. To do so, we (1) implement several representative classic ML algorithms (namely, linear regression, logistic regression, decision tree, K-Means clustering) on a real-world general-purpose PIM architecture, (2) rigorously evaluate and characterize them in terms of accuracy, performance and scaling, and (3) compare to their counterpart implementations on CPU and GPU. Our evaluation on a real memory-centric computing system with more than 2500 PIM cores shows that general-purpose PIM architectures can greatly accelerate memory-bound ML workloads, when the necessary operations and datatypes are natively supported by PIM hardware. For example, our PIM implementation of decision tree is $27\times$ faster than a state-of-the-art CPU version on an 8-core Intel Xeon, and $1.34\times$ faster than a state-of-the-art GPU version on an NVIDIA A100. Our K-Means clustering on PIM is $2.8\times$ and $3.2\times$ than state-of-the-art CPU and GPU versions, respectively. To our knowledge, our work is the first one to evaluate ML training on a real-world PIM architecture. We conclude with key observations, takeaways, and recommendations that can inspire users of ML workloads, programmers of PIM architectures, and hardware designers & architects of future memory-centric computing systems.
COVIDHunter: COVID-19 pandemic wave prediction and mitigation via seasonality-aware modeling
Jun 14, 2022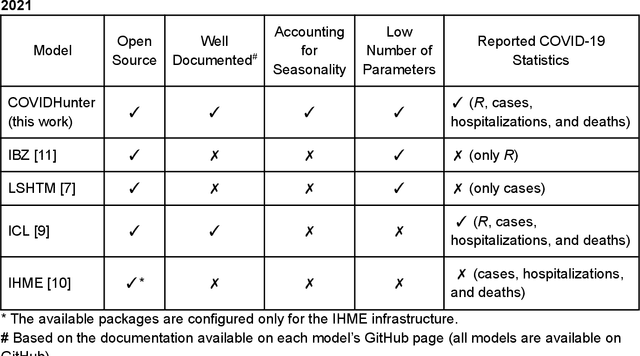
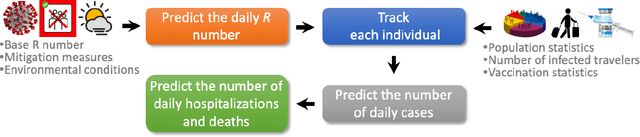
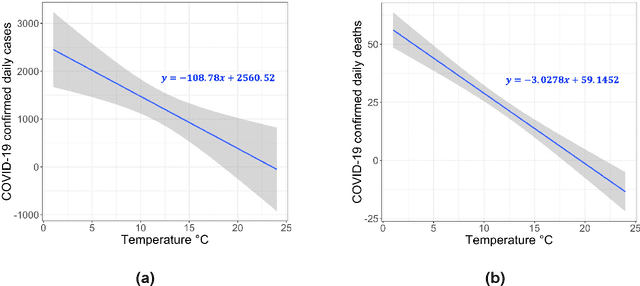
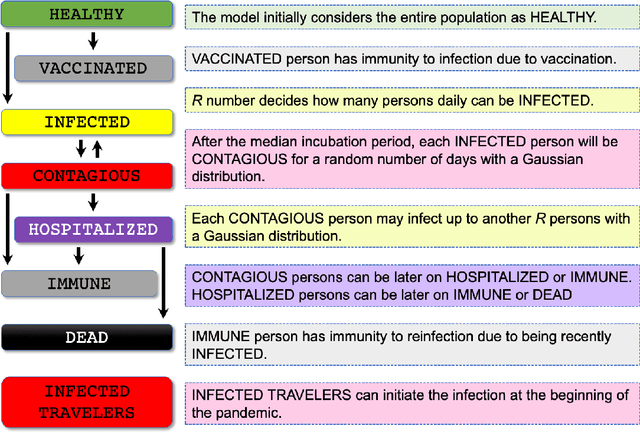
Early detection and isolation of COVID-19 patients are essential for successful implementation of mitigation strategies and eventually curbing the disease spread. With a limited number of daily COVID-19 tests performed in every country, simulating the COVID-19 spread along with the potential effect of each mitigation strategy currently remains one of the most effective ways in managing the healthcare system and guiding policy-makers. We introduce COVIDHunter, a flexible and accurate COVID-19 outbreak simulation model that evaluates the current mitigation measures that are applied to a region, predicts COVID-19 statistics (the daily number of cases, hospitalizations, and deaths), and provides suggestions on what strength the upcoming mitigation measure should be. The key idea of COVIDHunter is to quantify the spread of COVID-19 in a geographical region by simulating the average number of new infections caused by an infected person considering the effect of external factors, such as environmental conditions (e.g., climate, temperature, humidity), different variants of concern, vaccination rate, and mitigation measures. Using Switzerland as a case study, COVIDHunter estimates that we are experiencing a deadly new wave that will peak on 26 January 2022, which is very similar in numbers to the wave we had in February 2020. The policy-makers have only one choice that is to increase the strength of the currently applied mitigation measures for 30 days. Unlike existing models, the COVIDHunter model accurately monitors and predicts the daily number of cases, hospitalizations, and deaths due to COVID-19. Our model is flexible to configure and simple to modify for modeling different scenarios under different environmental conditions and mitigation measures. We release the source code of the COVIDHunter implementation at https://github.com/CMU-SAFARI/COVIDHunter.