 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-driven Memory Compression for On-device Large Language Models
Jan 24, 2026Large language models (LLMs) often rely on user-specific memories distilled from past interactions to enable personalized generation. A common practice is to concatenate these memories with the input prompt, but this approach quickly exhausts the limited context available in on-device LLMs. Compressing memories by averaging can mitigate context growth, yet it frequently harms performance due to semantic conflicts across heterogeneous memories. In this work, we introduce a clustering-based memory compression strategy that balances context efficiency and personalization quality. Our method groups memories by similarity and merges them within clusters prior to concatenation, thereby preserving coherence while reducing redundancy. Experiments demonstrate that our approach substantially lowers the number of memory tokens while outperforming baseline strategies such as naive averaging or direct concatenation. Furthermore, for a fixed context budget, clustering-driven merging yields more compact memory representations and consistently enhances generation quality.
Data-driven Clustering and Merging of Adapters for On-device Large Language Models
Jan 24, 2026On-device large language models commonly employ task-specific adapters (e.g., LoRAs) to deliver strong performance on downstream tasks. While storing all available adapters is impractical due to memory constraints, mobile devices typically have sufficient capacity to store a limited number of these parameters. This raises a critical challenge: how to select representative adapters that generalize well across multiple tasks - a problem that remains unexplored in existing literature. We propose a novel method D2C for adapter clustering that leverages minimal task-specific examples (e.g., 10 per task) and employs an iterative optimization process to refine cluster assignments. The adapters within each cluster are merged, creating multi-task adapters deployable on resource-constrained devices. Experimental results demonstrate that our method effectively boosts performance for considered storage budgets.
CG-TTRL: Context-Guided Test-Time Reinforcement Learning for On-Device Large Language Models
Nov 09, 2025Test-time Reinforcement Learning (TTRL) has shown promise in adapting foundation models for complex tasks at test-time, resulting in large performance improvements. TTRL leverages an elegant two-phase sampling strategy: first, multi-sampling derives a pseudo-label via majority voting, while subsequent downsampling and reward-based fine-tuning encourages the model to explore and learn diverse valid solutions, with the pseudo-label modulating the reward signal. Meanwhile, in-context learning has been widely explored at inference time and demonstrated the ability to enhance model performance without weight updates. However, TTRL's two-phase sampling strategy under-utilizes contextual guidance, which can potentially improve pseudo-label accuracy in the initial exploitation phase while regulating exploration in the second. To address this, we propose context-guided TTRL (CG-TTRL), integrating context dynamically into both sampling phases and propose a method for efficient context selection for on-device applications. Our evaluations on mathematical and scientific QA benchmarks show CG-TTRL outperforms TTRL (e.g. additional 7% relative accuracy improvement over TTRL), while boosting efficiency by obtaining strong performance after only a few steps of test-time training (e.g. 8% relative improvement rather than 1% over TTRL after 3 steps).
HydraOpt: Navigating the Efficiency-Performance Trade-off of Adapter Merging
Jul 23, 2025Large language models (LLMs) often leverage adapters, such as low-rank-based adapters, to achieve strong performance on downstream tasks. However, storing a separate adapter for each task significantly increases memory requirements, posing a challenge for resource-constrained environments such as mobile devices. Although model merging techniques can reduce storage costs, they typically result in substantial performance degradation. In this work, we introduce HydraOpt, a new model merging technique that capitalizes on the inherent similarities between the matrices of low-rank adapters. Unlike existing methods that produce a fixed trade-off between storage size and performance, HydraOpt allows us to navigate this spectrum of efficiency and performance. Our experiments show that HydraOpt significantly reduces storage size (48% reduction) compared to storing all adapters, while achieving competitive performance (0.2-1.8% drop). Furthermore, it outperforms existing merging techniques in terms of performance at the same or slightly worse storage efficiency.
LoRA.rar: Learning to Merge LoRAs via Hypernetworks for Subject-Style Conditioned Image Generation
Dec 06, 2024



Recent advancements in image generation models have enabled personalized image creation with both user-defined subjects (content) and styles. Prior works achieved personalization by merging corresponding low-rank adaptation parameters (LoRAs) through optimization-based methods, which are computationally demanding and unsuitable for real-time use on resource-constrained devices like smartphones. To address this, we introduce LoRA$.$rar, a method that not only improves image quality but also achieves a remarkable speedup of over $4000\times$ in the merging process. LoRA$.$rar pre-trains a hypernetwork on a diverse set of content-style LoRA pairs, learning an efficient merging strategy that generalizes to new, unseen content-style pairs, enabling fast, high-quality personalization. Moreover, we identify limitations in existing evaluation metrics for content-style quality and propose a new protocol using multimodal large language models (MLLM) for more accurate assessment. Our method significantly outperforms the current state of the art in both content and style fidelity, as validated by MLLM assessments and human evaluations.
Capacity Control is an Effective Memorization Mitigation Mechanism in Text-Conditional Diffusion Models
Oct 29, 2024

In this work, we present compelling evidence that controlling model capacity during fine-tuning can effectively mitigate memorization in diffusion models. Specifically, we demonstrate that adopting Parameter-Efficient Fine-Tuning (PEFT) within the pre-train fine-tune paradigm significantly reduces memorization compared to traditional full fine-tuning approaches. Our experiments utilize the MIMIC dataset, which comprises image-text pairs of chest X-rays and their corresponding reports. The results, evaluated through a range of memorization and generation quality metrics, indicate that PEFT not only diminishes memorization but also enhances downstream generation quality. Additionally, PEFT methods can be seamlessly combined with existing memorization mitigation techniques for further improvement. The code for our experiments is available at: https://github.com/Raman1121/Diffusion_Memorization_HPO
MemControl: Mitigating Memorization in Medical Diffusion Models via Automated Parameter Selection
May 29, 2024



Diffusion models show a remarkable ability in generating images that closely mirror the training distribution. However, these models are prone to training data memorization, leading to significant privacy, ethical, and legal concerns, particularly in sensitive fields such as medical imaging. We hypothesize that memorization is driven by the overparameterization of deep models, suggesting that regularizing model capacity during fine-tuning could be an effective mitigation strategy. Parameter-efficient fine-tuning (PEFT) methods offer a promising approach to capacity control by selectively updating specific parameters. However, finding the optimal subset of learnable parameters that balances generation quality and memorization remains elusive. To address this challenge, we propose a bi-level optimization framework that guides automated parameter selection by utilizing memorization and generation quality metrics as rewards. Our framework successfully identifies the optimal parameter set to be updated to satisfy the generation-memorization tradeoff. We perform our experiments for the specific task of medical image generation and outperform existing state-of-the-art training-time mitigation strategies by fine-tuning as few as 0.019% of model parameters. Furthermore, we show that the strategies learned through our framework are transferable across different datasets and domains. Our proposed framework is scalable to large datasets and agnostic to the choice of reward functions. Finally, we show that our framework can be combined with existing approaches for further memorization mitigation.
VL-ICL Bench: The Devil in the Details of Benchmarking Multimodal In-Context Learning
Mar 19, 2024



Large language models (LLMs) famously exhibit emergent in-context learning (ICL) -- the ability to rapidly adapt to new tasks using few-shot examples provided as a prompt, without updating the model's weights. Built on top of LLMs, vision large language models (VLLMs) have advanced significantly in areas such as recognition, reasoning, and grounding. However, investigations into \emph{multimodal ICL} have predominantly focused on few-shot visual question answering (VQA), and image captioning, which we will show neither exploit the strengths of ICL, nor test its limitations. The broader capabilities and limitations of multimodal ICL remain under-explored. In this study, we introduce a comprehensive benchmark VL-ICL Bench for multimodal in-context learning, encompassing a broad spectrum of tasks that involve both images and text as inputs and outputs, and different types of challenges, from {perception to reasoning and long context length}. We evaluate the abilities of state-of-the-art VLLMs against this benchmark suite, revealing their diverse strengths and weaknesses, and showing that even the most advanced models, such as GPT-4, find the tasks challenging. By highlighting a range of new ICL tasks, and the associated strengths and limitations of existing models, we hope that our dataset will inspire future work on enhancing the in-context learning capabilities of VLLMs, as well as inspire new applications that leverage VLLM ICL. The code and dataset are available at https://github.com/ys-zong/VL-ICL.
Safety Fine-Tuning at No Cost: A Baseline for Vision Large Language Models
Feb 03, 2024

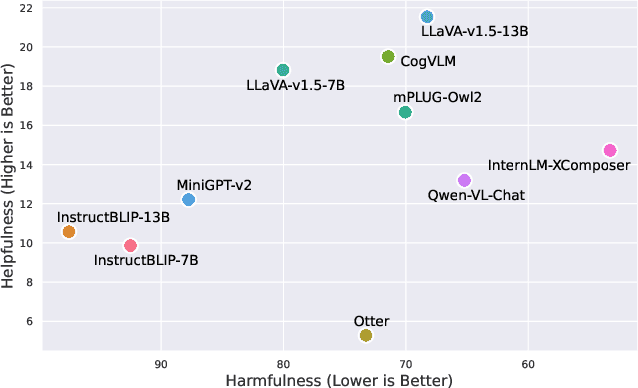
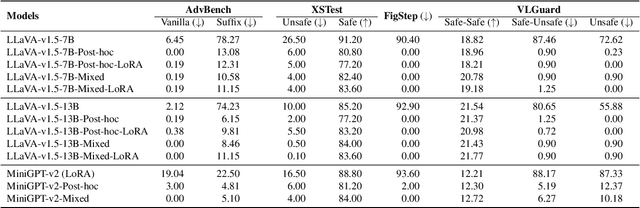
Current vision large language models (VLLMs) exhibit remarkable capabilities yet are prone to generate harmful content and are vulnerable to even the simplest jailbreaking attacks. Our initial analysis finds that this is due to the presence of harmful data during vision-language instruction fine-tuning, and that VLLM fine-tuning can cause forgetting of safety alignment previously learned by the underpinning LLM. To address this issue, we first curate a vision-language safe instruction-following dataset VLGuard covering various harmful categories. Our experiments demonstrate that integrating this dataset into standard vision-language fine-tuning or utilizing it for post-hoc fine-tuning effectively safety aligns VLLMs. This alignment is achieved with minimal impact on, or even enhancement of, the models' helpfulness. The versatility of our safety fine-tuning dataset makes it a valuable resource for safety-testing existing VLLMs, training new models or safeguarding pre-trained VLLMs. Empirical results demonstrate that fine-tuned VLLMs effectively reject unsafe instructions and substantially reduce the success rates of several black-box adversarial attacks, which approach zero in many cases. The code and dataset are available at https://github.com/ys-zong/VLGuard.
FairTune: Optimizing Parameter Efficient Fine Tuning for Fairness in Medical Image Analysis
Oct 08, 2023Training models with robust group fairness properties is crucial in ethically sensitive application areas such as medical diagnosis. Despite the growing body of work aiming to minimise demographic bias in AI, this problem remains challenging. A key reason for this challenge is the fairness generalisation gap: High-capacity deep learning models can fit all training data nearly perfectly, and thus also exhibit perfect fairness during training. In this case, bias emerges only during testing when generalisation performance differs across subgroups. This motivates us to take a bi-level optimisation perspective on fair learning: Optimising the learning strategy based on validation fairness. Specifically, we consider the highly effective workflow of adapting pre-trained models to downstream medical imaging tasks using parameter-efficient fine-tuning (PEFT) techniques. There is a trade-off between updating more parameters, enabling a better fit to the task of interest vs. fewer parameters, potentially reducing the generalisation gap. To manage this tradeoff, we propose FairTune, a framework to optimise the choice of PEFT parameters with respect to fairness. We demonstrate empirically that FairTune leads to improved fairness on a range of medical imaging datasets.