 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounded Satirical Generation with RAG
May 11, 2026Humor generation remains challenging task for Large Language Models (LLMs), due to their subjective nature. We focus on satire, a form of humor strongly shaped by context. In this work, we present a novel pipeline for grounded satire generation that uses Retrieval-Augmented Generation (RAG) over current news to produce satirical dictionary definitions in the Finnish context. We also introduce a new task-specific evaluation framework and annotate 100 generated definitions with six human annotators, enabling analysis across multiple experimental conditions, including cultural background, source-word type, and the presence or absence of RAG. Our results show that the generated definitions are perceived as more political than humorous. Both topic-based word selection and RAG improve the political relevance of the outputs, but neither yields clear gains in humor generation. In addition, our LLM-as-a-judge evaluation of five state-of-the-art models indicates that LLMs correlate well with human judgments on political relevance, but perform poorly on humor. We release our code and annotated dataset to support further research on grounded satire generation and evaluation.
MAMMOTH: Massively Multilingual Modular Open Translation @ Helsinki
Mar 12, 2024



NLP in the age of monolithic large language models is approaching its limits in terms of size and information that can be handled. The trend goes to modularization, a necessary step into the direction of designing smaller sub-networks and components with specialized functionality. In this paper, we present the MAMMOTH toolkit: a framework designed for training massively multilingual modular machine translation systems at scale, initially derived from OpenNMT-py and then adapted to ensure efficient training across computation clusters. We showcase its efficiency across clusters of A100 and V100 NVIDIA GPUs, and discuss our design philosophy and plans for future information. The toolkit is publicly available online.
Spanish Biomedical and Clinical Language Embeddings
Feb 25, 2021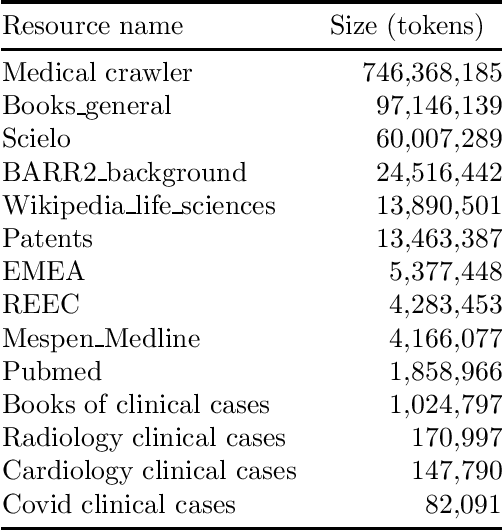
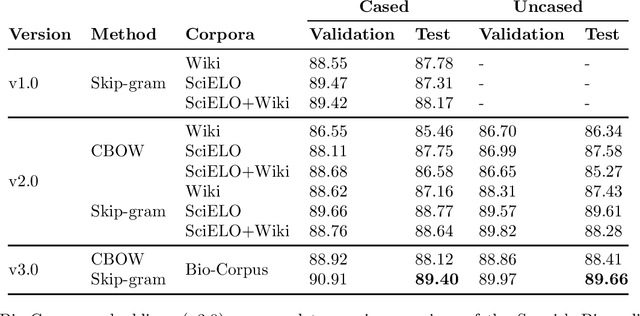
We computed both Word and Sub-word Embeddings using FastText. For Sub-word embeddings we selected Byte Pair Encoding (BPE) algorithm to represent the sub-words. We evaluated the Biomedical Word Embeddings obtaining better results than previous versions showing the implication that with more data, we obtain better representations.