 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoAoA: Few-Shot Angle-of-Arrival Estimation using Prototypical Networks
Apr 15, 2026Angle-of-arrival (AoA) estimation is a crucial function in wireless communications used for localization, beam-forming, interference management, and other applications. Deep learning (DL) solutions have been proposed for AoA to mitigate limitations of traditional AoA estimation techniques such as sensitivity to noise and the inability to generalize across different array characteristics. A challenge, however, of DL-based approaches is their reliance on large data collection campaigns and model training. This paper proposes the application of Prototypical Networks (PN) to address this challenge and utilizes a real-world dataset collected on a software defined radio (SDR) testbed to validate the effectiveness of the proposed solution. Prototypical Networks excel in extracting representative embeddings from unstructured input data, establishing class prototypes during training that can be few-shot trained on unseen classes. We demonstrate the efficacy of PNs for AoA classification using complex IQ samples, focusing on its ability to correctly classify new, unseen angles that the model was not trained on previously. Our results show that training our proposed ProtoAoA on only 23% of the AoA dataset classes can attain a mean absolute error (MAE) of 3 degrees with only 4-shots of training on the unseen angles - and an MAE of 2 degrees with 32-shots of training data. These results demonstrate that the developed prototypical network architecture requires remarkably few data samples to achieve reliable AoA estimation - and highlights its potential for other wireless applications where data availability is limited.
WirelessJEPA: A Multi-Antenna Foundation Model using Spatio-temporal Wireless Latent Predictions
Jan 28, 2026We propose WirelessJEPA, a novel wireless foundation model (WFM) that uses the Joint Embedding Predictive Architecture (JEPA). WirelessJEPA learns general-purpose representations directly from real-world multi-antenna IQ data by predicting latent representations of masked signal regions. This enables multiple diverse downstream tasks without reliance on carefully engineered contrastive augmentations. To adapt JEPA to wireless signals, we introduce a 2D antenna time representation that reshapes multi-antenna IQ streams into structured grids, allowing convolutional processing with block masking and efficient sparse computation over unmasked patches. Building on this representation, we propose novel spatio temporal mask geometries that encode inductive biases across antennas and time. We evaluate WirelessJEPA across six downstream tasks and demonstrate it's robust performance and strong task generalization. Our results establish that JEPA-based learning as a promising direction for building generalizable WFMs.
IQFM A Wireless Foundational Model for I/Q Streams in AI-Native 6G
Jun 07, 2025Foundational models have shown remarkable potential in natural language processing and computer vision, yet remain in their infancy in wireless communications. While a few efforts have explored image-based modalities such as channel state information (CSI) and frequency spectrograms, foundational models that operate directly on raw IQ data remain largely unexplored. This paper presents, IQFM, the first I/Q signal foundational model for wireless communications. IQFM supporting diverse tasks: modulation classification, angle-of-arrival (AoA), beam prediction, and RF fingerprinting, without heavy preprocessing or handcrafted features. We also introduce a task-aware augmentation strategy that categorizes transformations into core augmentations, such as cyclic time shifting, and task-specific augmentations. This strategy forms the basis for structured, task-dependent representation learning within a contrastive self-supervised learning (SSL) framework. Using this strategy, the lightweight encoder, pre-trained via SSL on over-the-air multi-antenna IQ data, achieves up to 99.67% and 65.45% accuracy on modulation and AoA classification, respectively, using only one labeled sample per class, outperforming supervised baselines by up to 7x and 145x. The model also generalizes to out-of-distribution tasks; when adapted to new tasks using only 500 samples per class and minimal parameter updates via LoRA, the same frozen encoder achieves 94.15% on beam prediction (vs. 89.53% supervised), 50.00% on RML2016a modulation classification (vs. 49.30%), and 96.05% on RF fingerprinting (vs. 96.64%). These results demonstrate the potential of raw IQ-based foundational models as efficient, reusable encoders for multi-task learning in AI-native 6G systems.
ProtoBeam: Generalizing Deep Beam Prediction to Unseen Antennas using Prototypical Networks
Jan 06, 2025



Deep learning techniques have recently emerged to efficiently manage mmWave beam transmissions without requiring time consuming beam sweeping strategies. A fundamental challenge in these methods is their dependency on hardware-specific training data and their limited ability to generalize. Large drops in performance are reported in literature when DL models trained in one antenna environment are applied in another. This paper proposes the application of Prototypical Networks to address this challenge and utilizes the DeepBeam real-world dataset to validate the developed solutions. Prototypical Networks excel in extracting features to establish class-specific prototypes during the training, resulting in precise embeddings that encapsulate the defining features of the data. We demonstrate the effectiveness of PN to enable generalization of deep beam predictors across unseen antennas. Our approach, which integrates data normalization and prototype normalization with the PN, achieves an average beam classification accuracy of 74.11 percent when trained and tested on different antenna datasets. This is an improvement of 398 percent compared to baseline performances reported in literature that do not account for such domain shifts. To the best of our knowledge, this work represents the first demonstration of the value of Prototypical Networks for domain adaptation in wireless networks, providing a foundation for future research in this area.
Using Early Exits for Fast Inference in Automatic Modulation Classification
Aug 22, 2023Automatic modulation classification (AMC) plays a critical role in wireless communications by autonomously classifying signals transmitted over the radio spectrum. Deep learning (DL) techniques are increasingly being used for AMC due to their ability to extract complex wireless signal features. However, DL models are computationally intensive and incur high inference latencies. This paper proposes the application of early exiting (EE) techniques for DL models used for AMC to accelerate inference. We present and analyze four early exiting architectures and a customized multi-branch training algorithm for this problem. Through extensive experimentation, we show that signals with moderate to high signal-to-noise ratios (SNRs) are easier to classify, do not require deep architectures, and can therefore leverage the proposed EE architectures. Our experimental results demonstrate that EE techniques can significantly reduce the inference speed of deep neural networks without sacrificing classification accuracy. We also thoroughly study the trade-off between classification accuracy and inference time when using these architectures. To the best of our knowledge, this work represents the first attempt to apply early exiting methods to AMC, providing a foundation for future research in this area.
Feature selection for intrusion detection systems
Jun 28, 2021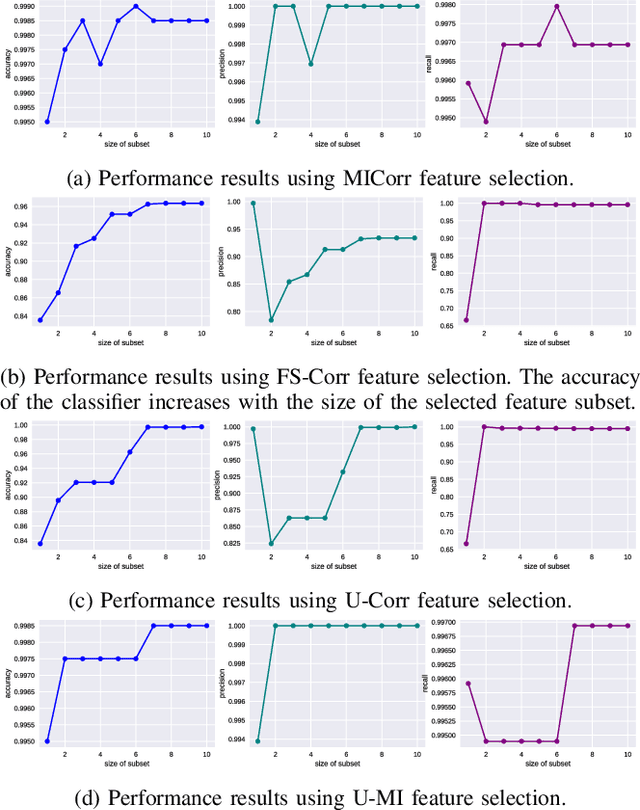
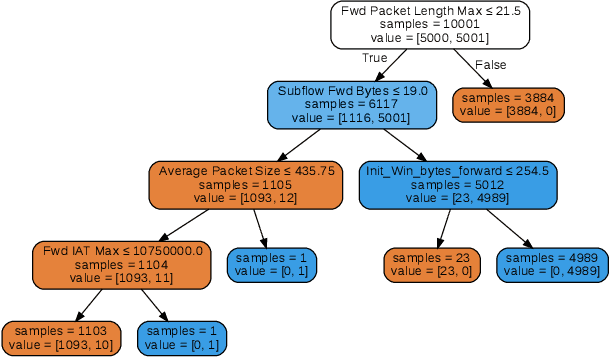
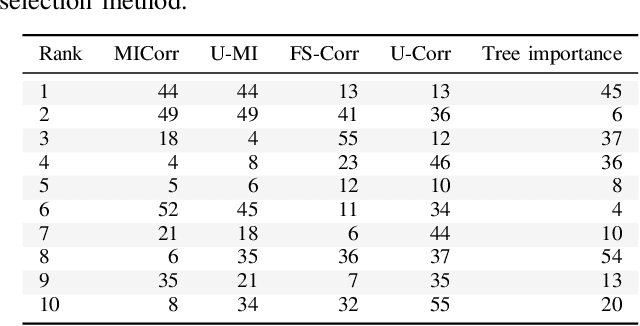
In this paper, we analyze existing feature selection methods to identify the key elements of network traffic data that allow intrusion detection. In addition, we propose a new feature selection method that addresses the challenge of considering continuous input features and discrete target values. We show that the proposed method performs well against the benchmark selection methods. We use our findings to develop a highly effective machine learning-based detection systems that achieves 99.9% accuracy in distinguishing between DDoS and benign signals. We believe that our results can be useful to experts who are interested in designing and building automated intrusion detection systems.