 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedScribe: Clinically Grounded CT Reporting through Agentic Workflows
May 03, 2026Vision-language models (VLMs) have shown potential for automated radiology report generation, yet existing approaches rely on global embedding compression of volumetric data, often leading to hallucinated findings and limited anatomical grounding in 3D CT imaging. We introduce MedScribe, a hypothesis-driven framework that reformulates report generation as an iterative evidence acquisition process rather than a single-pass encoding task. MedScribe models reporting as a sequential decision process in which a large language model dynamically invokes pathology-specific diagnostic tools to extract localized volumetric features. These structured features are used to query a multidimensional retrieval space aligned with pathology-specific textual evidence. By explicitly accumulating quantitative evidence prior to synthesis, the framework enforces fine-grained grounding and reduces unsupported claims. Without task-specific fine-tuning, MedScribe improves clinical accuracy, factual consistency, and interpretability on CT-RATE and RadChestCT compared to state-of-the-art 2D and 3D VLMs, demonstrating the value of hypothesis-driven reasoning for reliable medical image reporting.
Fed-BioMed: Open, Transparent and Trusted Federated Learning for Real-world Healthcare Applications
Apr 24, 2023



The real-world implementation of federated learning is complex and requires research and development actions at the crossroad between different domains ranging from data science, to software programming, networking, and security. While today several FL libraries are proposed to data scientists and users, most of these frameworks are not designed to find seamless application in medical use-cases, due to the specific challenges and requirements of working with medical data and hospital infrastructures. Moreover, governance, design principles, and security assumptions of these frameworks are generally not clearly illustrated, thus preventing the adoption in sensitive applications. Motivated by the current technological landscape of FL in healthcare, in this document we present Fed-BioMed: a research and development initiative aiming at translating federated learning (FL) into real-world medical research applications. We describe our design space, targeted users, domain constraints, and how these factors affect our current and future software architecture.
Are labels informative in semi-supervised learning? -- Estimating and leveraging the missing-data mechanism
Feb 15, 2023Semi-supervised learning is a powerful technique for leveraging unlabeled data to improve machine learning models, but it can be affected by the presence of ``informative'' labels, which occur when some classes are more likely to be labeled than others. In the missing data literature, such labels are called missing not at random. In this paper, we propose a novel approach to address this issue by estimating the missing-data mechanism and using inverse propensity weighting to debias any SSL algorithm, including those using data augmentation. We also propose a likelihood ratio test to assess whether or not labels are indeed informative. Finally, we demonstrate the performance of the proposed methods on different datasets, in particular on two medical datasets for which we design pseudo-realistic missing data scenarios.
Privacy Preserving Image Registration
May 17, 2022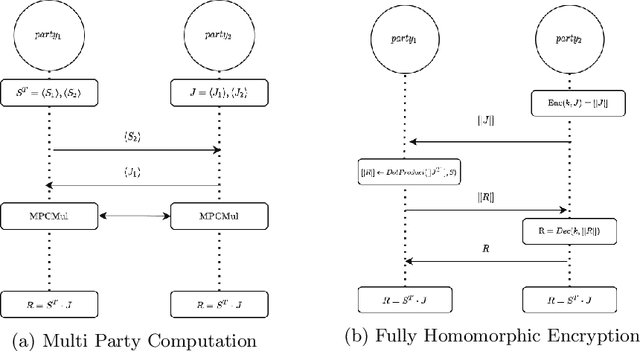
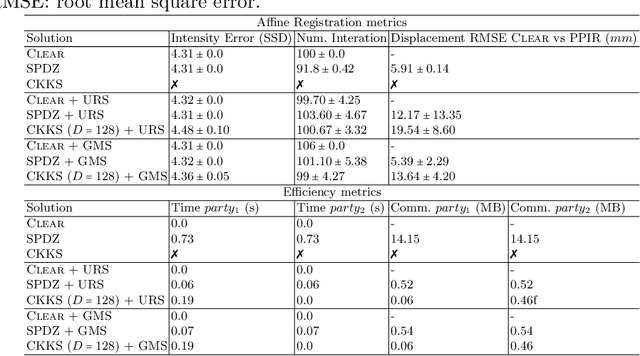
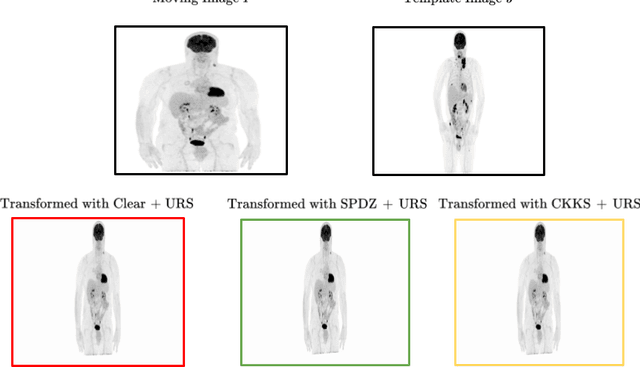
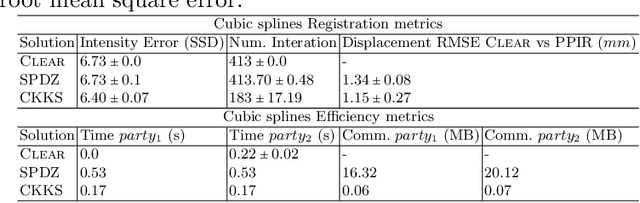
Image registration is a key task in medical imaging applications, allowing to represent medical images in a common spatial reference frame. Current literature on image registration is generally based on the assumption that images are usually accessible to the researcher, from which the spatial transformation is subsequently estimated. This common assumption may not be met in current practical applications, since the sensitive nature of medical images may ultimately require their analysis under privacy constraints, preventing to share the image content in clear form. In this work, we formulate the problem of image registration under a privacy preserving regime, where images are assumed to be confidential and cannot be disclosed in clear. We derive our privacy preserving image registration framework by extending classical registration paradigms to account for advanced cryptographic tools, such as secure multi-party computation and homomorphic encryption, that enable the execution of operations without leaking the underlying data. To overcome the problem of performance and scalability of cryptographic tools in high dimensions, we first propose to optimize the underlying image registration operations using gradient approximations. We further revisit the use of homomorphic encryption and use a packing method to allow the encryption and multiplication of large matrices more efficiently. We demonstrate our privacy preserving framework in linear and non-linear registration problems, evaluating its accuracy and scalability with respect to standard image registration. Our results show that privacy preserving image registration is feasible and can be adopted in sensitive medical imaging applications.
Don't fear the unlabelled: safe deep semi-supervised learning via simple debiasing
Mar 16, 2022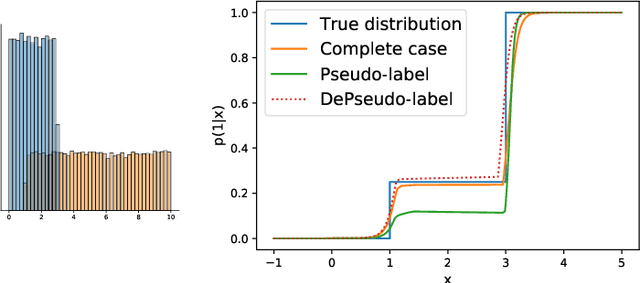
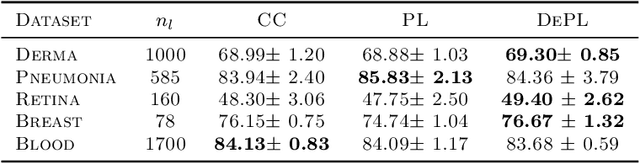
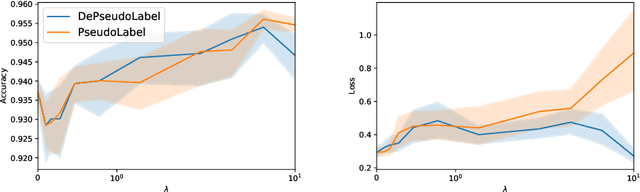
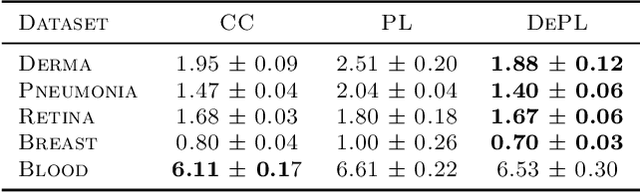
Semi supervised learning (SSL) provides an effective means of leveraging unlabelled data to improve a model's performance. Even though the domain has received a considerable amount of attention in the past years, most methods present the common drawback of being unsafe. By safeness we mean the quality of not degrading a fully supervised model when including unlabelled data. Our starting point is to notice that the estimate of the risk that most discriminative SSL methods minimise is biased, even asymptotically. This bias makes these techniques untrustable without a proper validation set, but we propose a simple way of removing the bias. Our debiasing approach is straightforward to implement, and applicable to most deep SSL methods. We provide simple theoretical guarantees on the safeness of these modified methods, without having to rely on the strong assumptions on the data distribution that SSL theory usually requires. We evaluate debiased versions of different existing SSL methods and show that debiasing can compete with classic deep SSL techniques in various classic settings and even performs well when traditional SSL fails.
GridNet with automatic shape prior registration for automatic MRI cardiac segmentation
Sep 12, 2017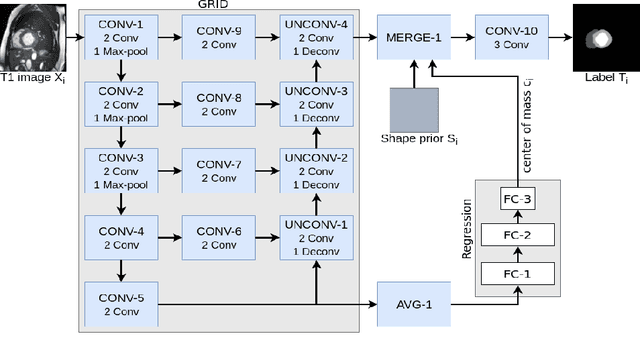
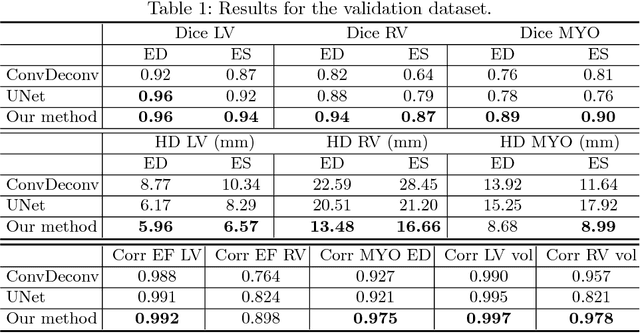
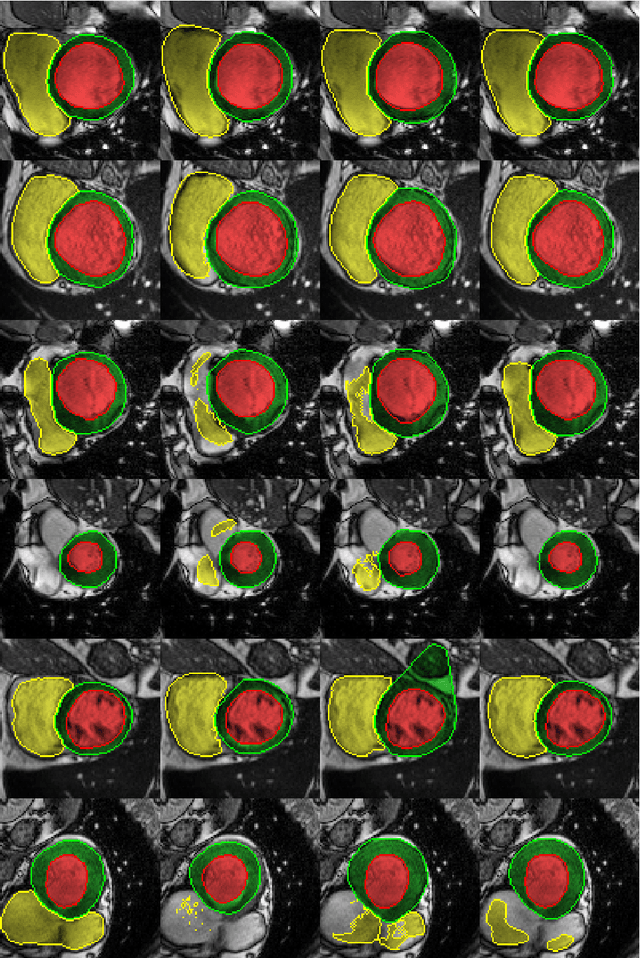
In this paper, we propose a fully automatic MRI cardiac segmentation method based on a novel deep convolutional neural network (CNN) designed for the 2017 ACDC MICCAI challenge. The novelty of our network comes with its embedded shape prior and its loss function tailored to the cardiac anatomy. Our model includes a cardiac centerof-mass regression module which allows for an automatic shape prior registration. Also, since our method processes raw MR images without any manual preprocessing and/or image cropping, our CNN learns both high-level features (useful to distinguish the heart from other organs with a similar shape) and low-level features (useful to get accurate segmentation results). Those features are learned with a multi-resolution conv-deconv "grid" architecture which can be seen as an extension of the U-Net. Experimental results reveal that our method can segment the left and right ventricles as well as the myocardium from a 3D MRI cardiac volume in 0.4 second with an average Dice coefficient of 0.90 and an average Hausdorff distance of 10.4 mm.