 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen can unlabeled data improve the learning rate?
May 28, 2019In semi-supervised classification, one is given access both to labeled and unlabeled data. As unlabeled data is typically cheaper to acquire than labeled data, this setup becomes advantageous as soon as one can exploit the unlabeled data in order to produce a better classifier than with labeled data alone. However, the conditions under which such an improvement is possible are not fully understood yet. Our analysis focuses on improvements in the minimax learning rate in terms of the number of labeled examples (with the number of unlabeled examples being allowed to depend on the number of labeled ones). We argue that for such improvements to be realistic and indisputable, certain specific conditions should be satisfied and previous analyses have failed to meet those conditions. We then demonstrate examples where these conditions can be met, in particular showing rate changes from $1/\sqrt{\ell}$ to $e^{-c\ell}$ and from $1/\sqrt{\ell}$ to $1/\ell$. These results improve our understanding of what is and isn't possible in semi-supervised learning.
Practical and Consistent Estimation of f-Divergences
May 27, 2019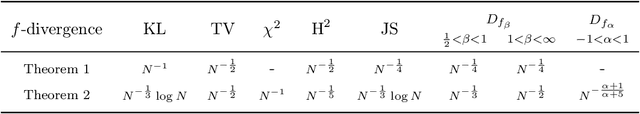
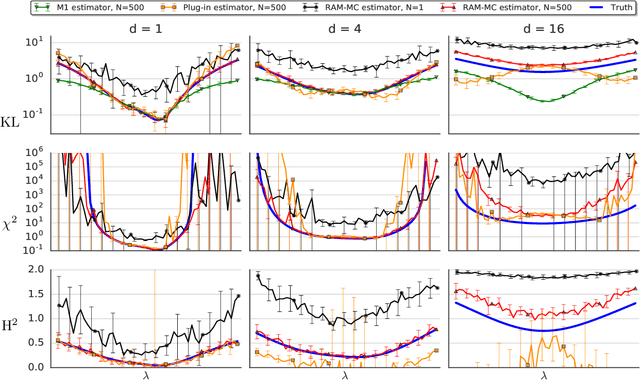
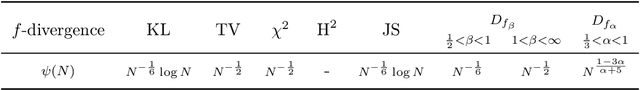
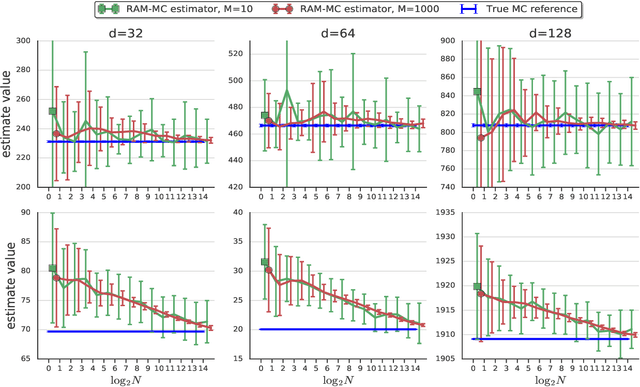
The estimation of an f-divergence between two probability distributions based on samples is a fundamental problem in statistics and machine learning. Most works study this problem under very weak assumptions, in which case it is provably hard. We consider the case of stronger structural assumptions that are commonly satisfied in modern machine learning, including representation learning and generative modelling with autoencoder architectures. Under these assumptions we propose and study an estimator that can be easily implemented, works well in high dimensions, and enjoys faster rates of convergence. We verify the behavior of our estimator empirically in both synthetic and real-data experiments, and discuss its direct implications for total correlation, entropy, and mutual information estimation.
Evaluating Generative Models Using Divergence Frontiers
May 26, 2019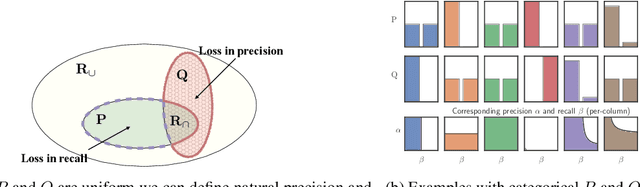
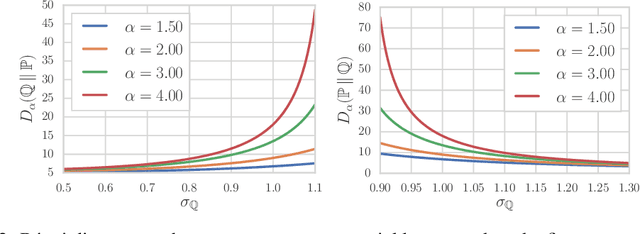
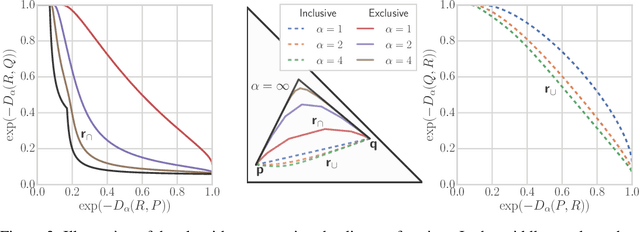
Despite the tremendous progress in the estimation of generative models, the development of tools for diagnosing their failures and assessing their performance has advanced at a much slower pace. Recent developments have investigated metrics that quantify which parts of the true distribution are modeled well, and, on the contrary, what the model fails to capture, akin to precision and recall in information retrieval. In this paper, we present a general evaluation framework for generative models that measures the trade-off between precision and recall using R\'enyi divergences. Our framework provides a novel perspective on existing techniques and extends them to more general domains. As a key advantage, it allows for efficient algorithms that are directly applicable to continuous distributions directly without discretization. We further showcase the proposed techniques on a set of image synthesis models.
The Optimal Approximation Factor in Density Estimation
Feb 10, 2019

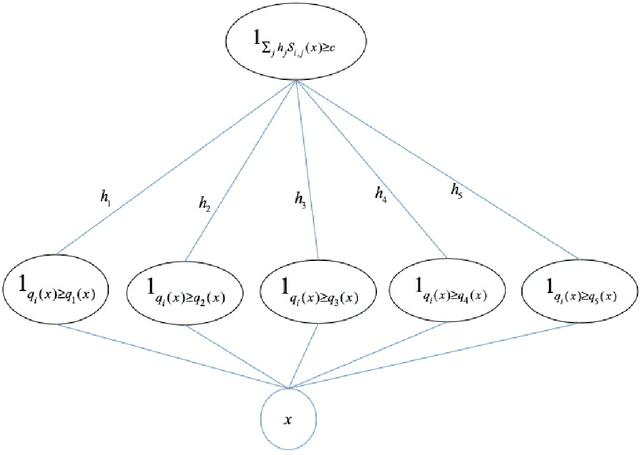
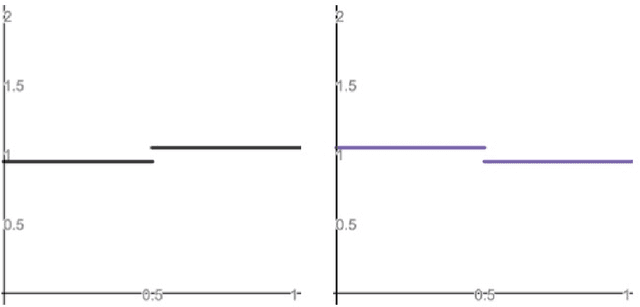
Consider the following problem: given two arbitrary densities $q_1,q_2$ and a sample-access to an unknown target density $p$, find which of the $q_i$'s is closer to $p$ in total variation. A remarkable result due to Yatracos shows that this problem is tractable in the following sense: there exists an algorithm that uses $O(\epsilon^{-2})$ samples from $p$ and outputs~$q_i$ such that with high probability, $TV(q_i,p) \leq 3\cdot\mathsf{opt} + \epsilon$, where $\mathsf{opt}= \min\{TV(q_1,p),TV(q_2,p)\}$. Moreover, this result extends to any finite class of densities $\mathcal{Q}$: there exists an algorithm that outputs the best density in $\mathcal{Q}$ up to a multiplicative approximation factor of 3. We complement and extend this result by showing that: (i) the factor 3 can not be improved if one restricts the algorithm to output a density from $\mathcal{Q}$, and (ii) if one allows the algorithm to output arbitrary densities (e.g.\ a mixture of densities from $\mathcal{Q}$), then the approximation factor can be reduced to 2, which is optimal. In particular this demonstrates an advantage of improper learning over proper in this setup. We develop two approaches to achieve the optimal approximation factor of 2: an adaptive one and a static one. Both approaches are based on a geometric point of view of the problem and rely on estimating surrogate metrics to the total variation. Our sample complexity bounds exploit techniques from {\it Adaptive Data Analysis}.
Passing Tests without Memorizing: Two Models for Fooling Discriminators
Feb 09, 2019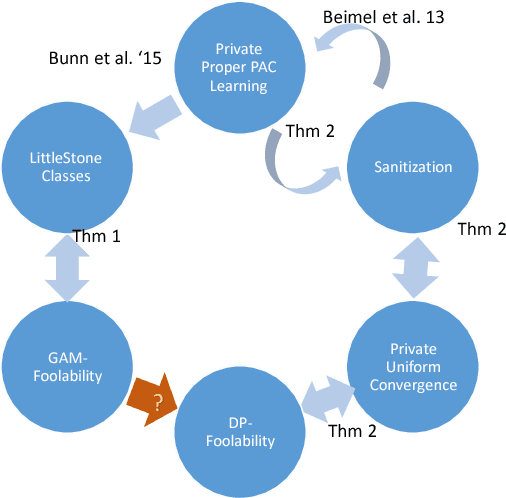
We introduce two mathematical frameworks for foolability in the context of generative distribution learning. In a nuthsell, fooling is an algorithmic task in which the input sample is drawn from some target distribution and the goal is to output a synthetic distribution that is indistinguishable from the target w.r.t to some fixed class of tests. This framework received considerable attention in the context of Generative Adversarial Networks (GANs), a recently proposed approach which achieves impressive empirical results. From a theoretical viewpoint this problem seems difficult to model. This is due to the fact that in its basic form, the notion of foolability is susceptible to a type of overfitting called memorizing. This raises a challenge of devising notions and definitions that separate between fooling algorithms that generate new synthetic data vs. algorithms that merely memorize or copy the training set. The first model we consider is called GAM--Foolability and is inspired by GANs. Here the learner has only an indirect access to the target distribution via a discriminator. The second model, called DP--Foolability, exploits the notion of differential privacy as a candidate criterion for non-memorization. We proceed to characterize foolability within these two models and study their interrelations. We show that DP--Foolability implies GAM--Foolability and prove partial results with respect to the converse. It remains, though, an open question whether GAM--Foolability implies DP--Foolability. We also present an application in the context of differentially private PAC learning. We show that from a statistical perspective, for any class H, learnability by a private proper learner is equivalent to the existence of a private sanitizer for H. This can be seen as an analogue of the equivalence between uniform convergence and learnability in classical PAC learning.
Are GANs Created Equal? A Large-Scale Study
Oct 29, 2018
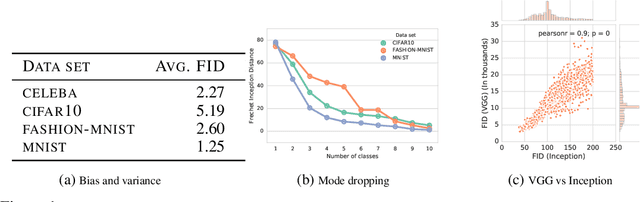
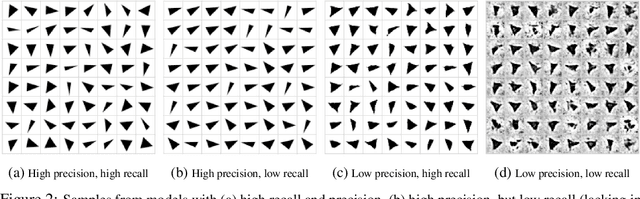
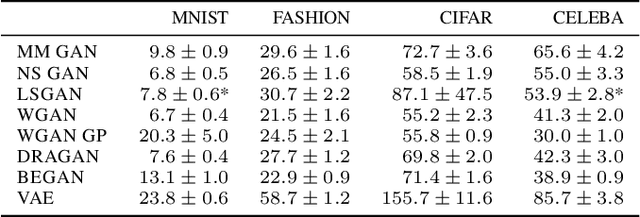
Generative adversarial networks (GAN) are a powerful subclass of generative models. Despite a very rich research activity leading to numerous interesting GAN algorithms, it is still very hard to assess which algorithm(s) perform better than others. We conduct a neutral, multi-faceted large-scale empirical study on state-of-the art models and evaluation measures. We find that most models can reach similar scores with enough hyperparameter optimization and random restarts. This suggests that improvements can arise from a higher computational budget and tuning more than fundamental algorithmic changes. To overcome some limitations of the current metrics, we also propose several data sets on which precision and recall can be computed. Our experimental results suggest that future GAN research should be based on more systematic and objective evaluation procedures. Finally, we did not find evidence that any of the tested algorithms consistently outperforms the non-saturating GAN introduced in \cite{goodfellow2014generative}.
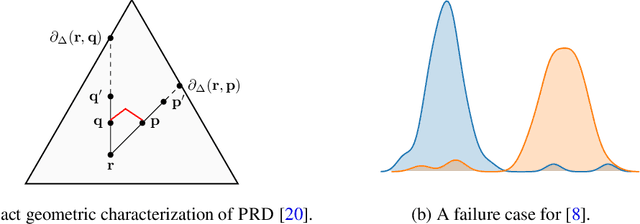
Assessing Generative Models via Precision and Recall
Oct 28, 2018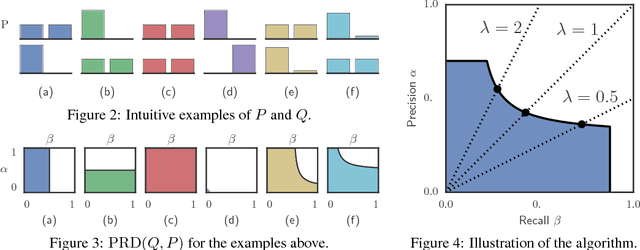
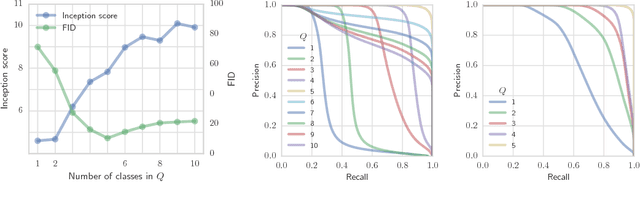
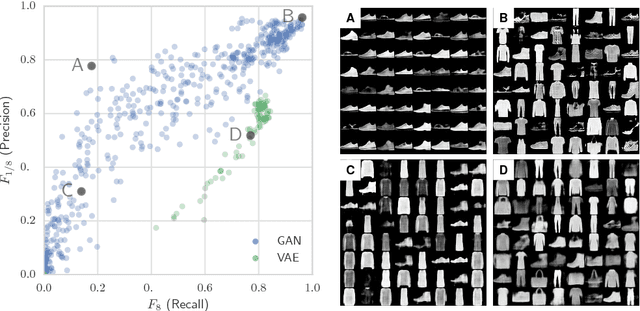
Recent advances in generative modeling have led to an increased interest in the study of statistical divergences as means of model comparison. Commonly used evaluation methods, such as the Frechet Inception Distance (FID), correlate well with the perceived quality of samples and are sensitive to mode dropping. However, these metrics are unable to distinguish between different failure cases since they only yield one-dimensional scores. We propose a novel definition of precision and recall for distributions which disentangles the divergence into two separate dimensions. The proposed notion is intuitive, retains desirable properties, and naturally leads to an efficient algorithm that can be used to evaluate generative models. We relate this notion to total variation as well as to recent evaluation metrics such as Inception Score and FID. To demonstrate the practical utility of the proposed approach we perform an empirical study on several variants of Generative Adversarial Networks and Variational Autoencoders. In an extensive set of experiments we show that the proposed metric is able to disentangle the quality of generated samples from the coverage of the target distribution.
Gradient Descent Quantizes ReLU Network Features
Mar 22, 2018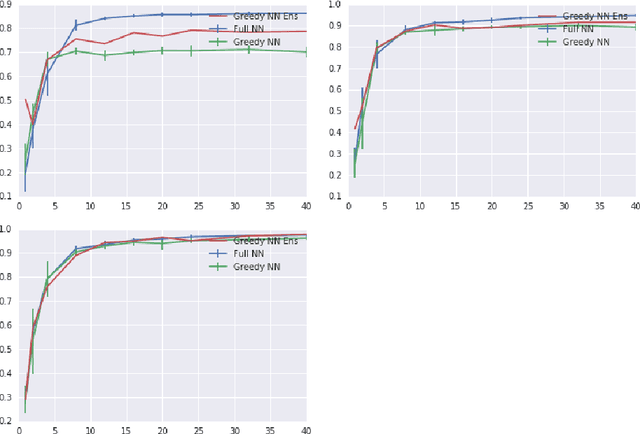
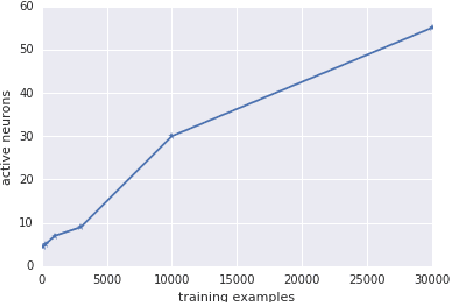
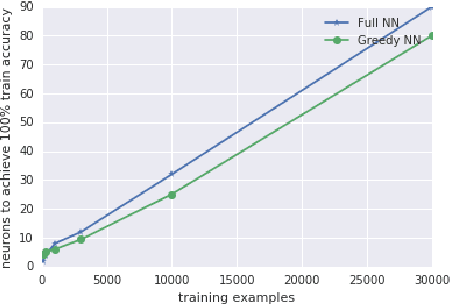
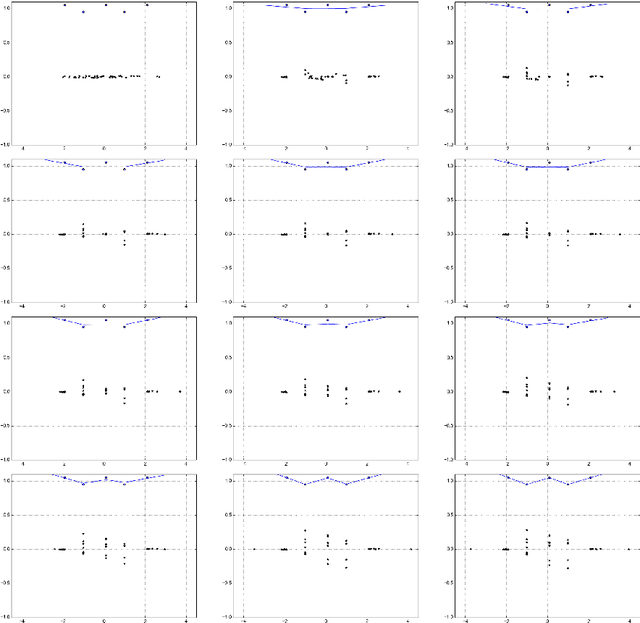
Deep neural networks are often trained in the over-parametrized regime (i.e. with far more parameters than training examples), and understanding why the training converges to solutions that generalize remains an open problem. Several studies have highlighted the fact that the training procedure, i.e. mini-batch Stochastic Gradient Descent (SGD) leads to solutions that have specific properties in the loss landscape. However, even with plain Gradient Descent (GD) the solutions found in the over-parametrized regime are pretty good and this phenomenon is poorly understood. We propose an analysis of this behavior for feedforward networks with a ReLU activation function under the assumption of small initialization and learning rate and uncover a quantization effect: The weight vectors tend to concentrate at a small number of directions determined by the input data. As a consequence, we show that for given input data there are only finitely many, "simple" functions that can be obtained, independent of the network size. This puts these functions in analogy to linear interpolations (for given input data there are finitely many triangulations, which each determine a function by linear interpolation). We ask whether this analogy extends to the generalization properties - while the usual distribution-independent generalization property does not hold, it could be that for e.g. smooth functions with bounded second derivative an approximation property holds which could "explain" generalization of networks (of unbounded size) to unseen inputs.
Wasserstein Auto-Encoders
Mar 12, 2018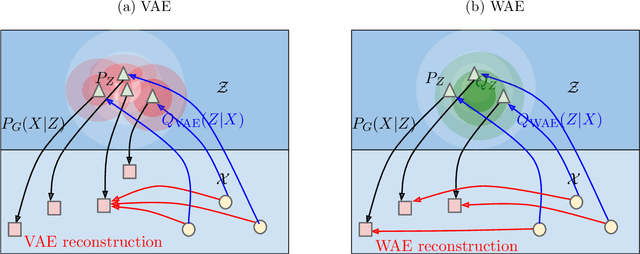
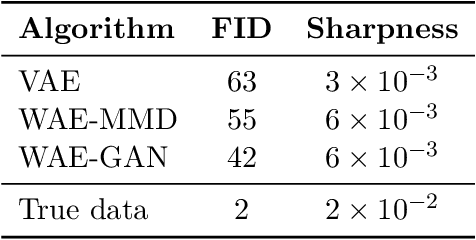


We propose the Wasserstein Auto-Encoder (WAE)---a new algorithm for building a generative model of the data distribution. WAE minimizes a penalized form of the Wasserstein distance between the model distribution and the target distribution, which leads to a different regularizer than the one used by the Variational Auto-Encoder (VAE). This regularizer encourages the encoded training distribution to match the prior. We compare our algorithm with several other techniques and show that it is a generalization of adversarial auto-encoders (AAE). Our experiments show that WAE shares many of the properties of VAEs (stable training, encoder-decoder architecture, nice latent manifold structure) while generating samples of better quality, as measured by the FID score.
Toward Optimal Run Racing: Application to Deep Learning Calibration
Jun 20, 2017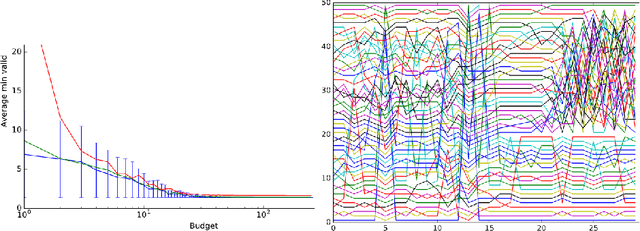
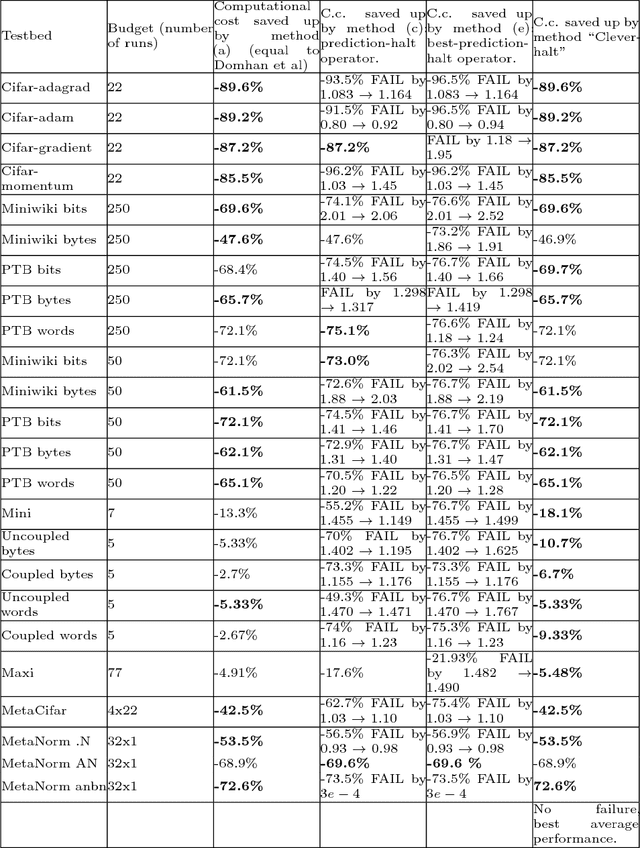
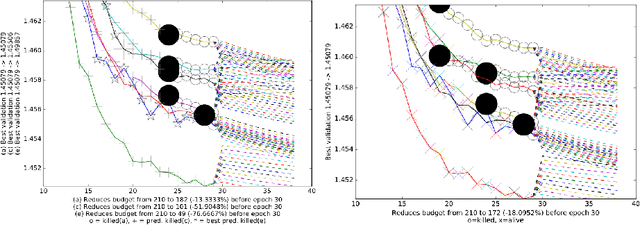
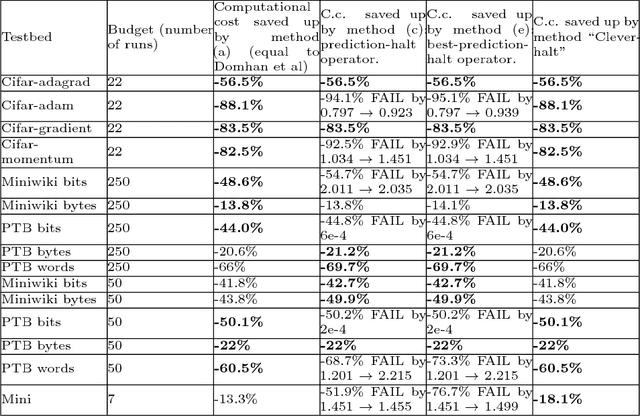
This paper aims at one-shot learning of deep neural nets, where a highly parallel setting is considered to address the algorithm calibration problem - selecting the best neural architecture and learning hyper-parameter values depending on the dataset at hand. The notoriously expensive calibration problem is optimally reduced by detecting and early stopping non-optimal runs. The theoretical contribution regards the optimality guarantees within the multiple hypothesis testing framework. Experimentations on the Cifar10, PTB and Wiki benchmarks demonstrate the relevance of the approach with a principled and consistent improvement on the state of the art with no extra hyper-parameter.