 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of data-driven inner speech decoding with same-task EEG-fMRI data fusion and bimodal models
Jun 19, 2023



Decoding inner speech from the brain signal via hybridisation of fMRI and EEG data is explored to investigate the performance benefits over unimodal models. Two different bimodal fusion approaches are examined: concatenation of probability vectors output from unimodal fMRI and EEG machine learning models, and data fusion with feature engineering. Same task inner speech data are recorded from four participants, and different processing strategies are compared and contrasted to previously-employed hybridisation methods. Data across participants are discovered to encode different underlying structures, which results in varying decoding performances between subject-dependent fusion models. Decoding performance is demonstrated as improved when pursuing bimodal fMRI-EEG fusion strategies, if the data show underlying structure.
Puffin: pitch-synchronous neural waveform generation for fullband speech on modest devices
Nov 25, 2022


We present a neural vocoder designed with low-powered Alternative and Augmentative Communication devices in mind. By combining elements of successful modern vocoders with established ideas from an older generation of technology, our system is able to produce high quality synthetic speech at 48kHz on devices where neural vocoders are otherwise prohibitively complex. The system is trained adversarially using differentiable pitch synchronous overlap add, and reduces complexity by relying on pitch synchronous Inverse Short-Time Fourier Transform (ISTFT) to generate speech samples. Our system achieves comparable quality with a strong (HiFi-GAN) baseline while using only a fraction of the compute. We present results of a perceptual evaluation as well as an analysis of system complexity.
Predicting pairwise preferences between TTS audio stimuli using parallel ratings data and anti-symmetric twin neural networks
Sep 22, 2022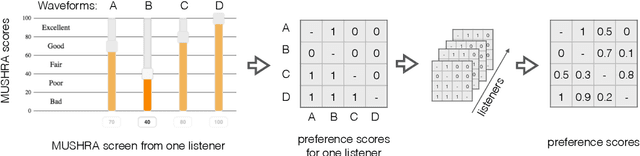
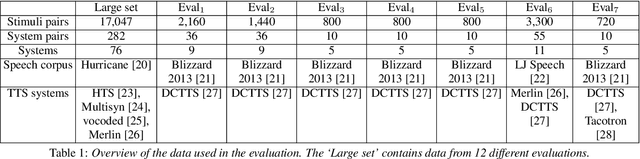
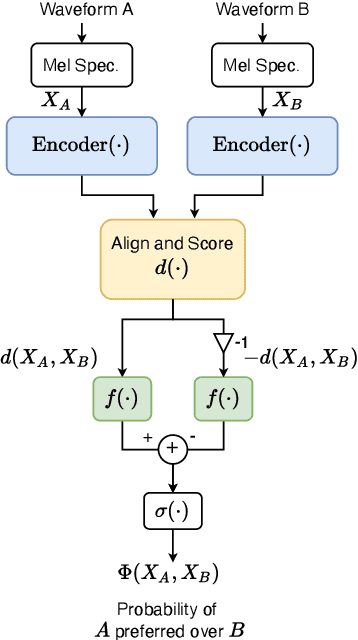
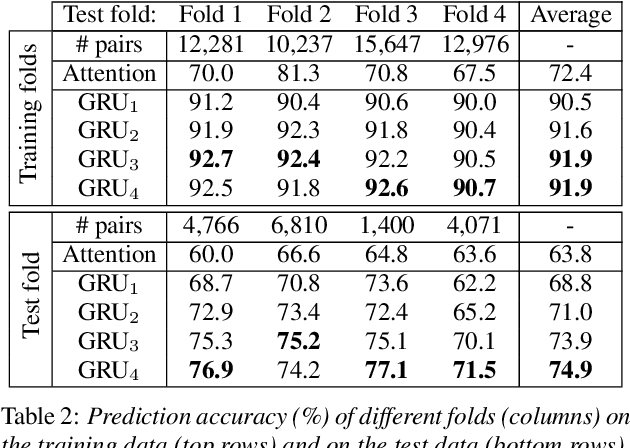
Automatically predicting the outcome of subjective listening tests is a challenging task. Ratings may vary from person to person even if preferences are consistent across listeners. While previous work has focused on predicting listeners' ratings (mean opinion scores) of individual stimuli, we focus on the simpler task of predicting subjective preference given two speech stimuli for the same text. We propose a model based on anti-symmetric twin neural networks, trained on pairs of waveforms and their corresponding preference scores. We explore both attention and recurrent neural nets to account for the fact that stimuli in a pair are not time aligned. To obtain a large training set we convert listeners' ratings from MUSHRA tests to values that reflect how often one stimulus in the pair was rated higher than the other. Specifically, we evaluate performance on data obtained from twelve MUSHRA evaluations conducted over five years, containing different TTS systems, built from data of different speakers. Our results compare favourably to a state-of-the-art model trained to predict MOS scores.
Using generative modelling to produce varied intonation for speech synthesis
Jun 10, 2019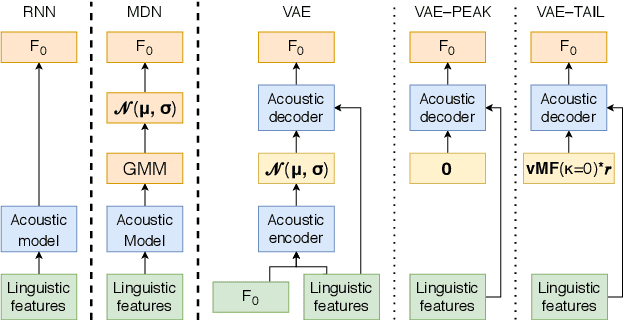
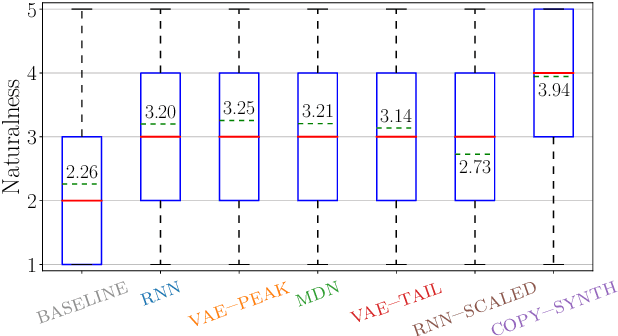
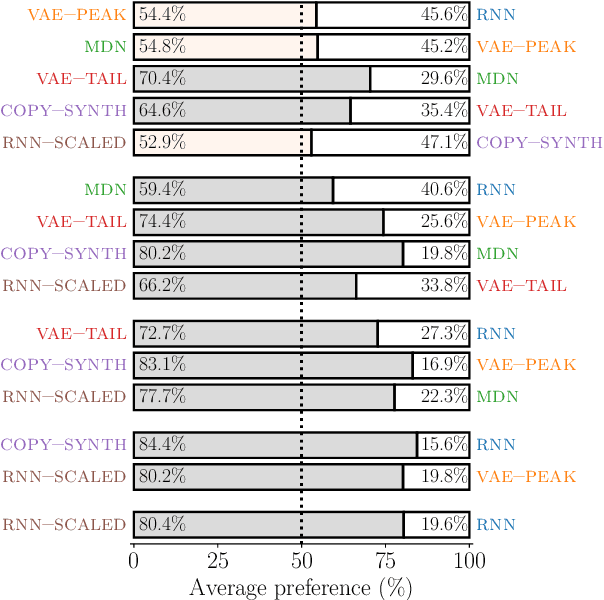

Unlike human speakers, typical text-to-speech (TTS) systems are unable to produce multiple distinct renditions of a given sentence. This has previously been addressed by adding explicit external control. In contrast, generative models are able to capture a distribution over multiple renditions and thus produce varied renditions using sampling. Typical neural TTS models learn the average of the data because they minimise mean squared error. In the context of prosody, taking the average produces flatter, more boring speech: an "average prosody". A generative model that can synthesise multiple prosodies will, by design, not model average prosody. We use variational autoencoders (VAE) which explicitly place the most "average" data close to the mean of the Gaussian prior. We propose that by moving towards the tails of the prior distribution, the model will transition towards generating more idiosyncratic, varied renditions. Focusing here on intonation, we investigate the trade-off between naturalness and intonation variation and find that typical acoustic models can either be natural, or varied, but not both. However, sampling from the tails of the VAE prior produces much more varied intonation than the traditional approaches, whilst maintaining the same level of naturalness.
Median-Based Generation of Synthetic Speech Durations using a Non-Parametric Approach
Nov 11, 2016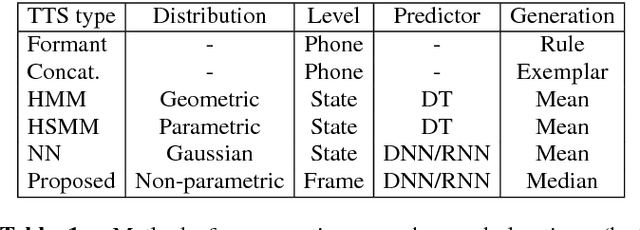
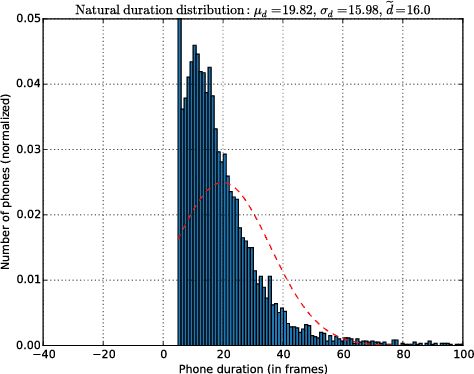
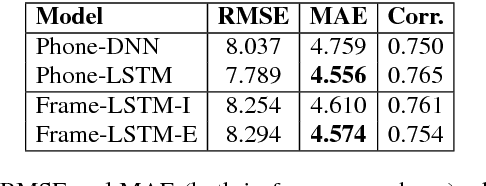
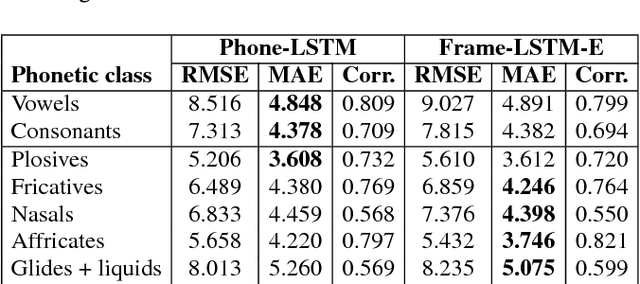
This paper proposes a new approach to duration modelling for statistical parametric speech synthesis in which a recurrent statistical model is trained to output a phone transition probability at each timestep (acoustic frame). Unlike conventional approaches to duration modelling -- which assume that duration distributions have a particular form (e.g., a Gaussian) and use the mean of that distribution for synthesis -- our approach can in principle model any distribution supported on the non-negative integers. Generation from this model can be performed in many ways; here we consider output generation based on the median predicted duration. The median is more typical (more probable) than the conventional mean duration, is robust to training-data irregularities, and enables incremental generation. Furthermore, a frame-level approach to duration prediction is consistent with a longer-term goal of modelling durations and acoustic features together. Results indicate that the proposed method is competitive with baseline approaches in approximating the median duration of held-out natural speech.