 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality reduction with missing values imputation
Jul 02, 2017

In this study, we propose a new statical approach for high-dimensionality reduction of heterogenous data that limits the curse of dimensionality and deals with missing values. To handle these latter, we propose to use the Random Forest imputation's method. The main purpose here is to extract useful information and so reducing the search space to facilitate the data exploration process. Several illustrative numeric examples, using data coming from publicly available machine learning repositories are also included. The experimental component of the study shows the efficiency of the proposed analytical approach.
Classification non supervisée des données hétérogènes à large échelle
Jul 02, 2017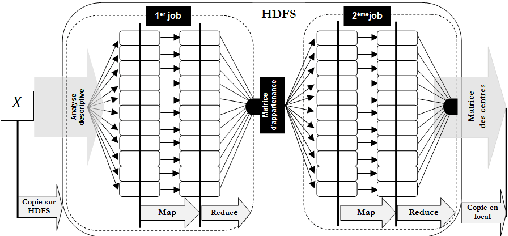
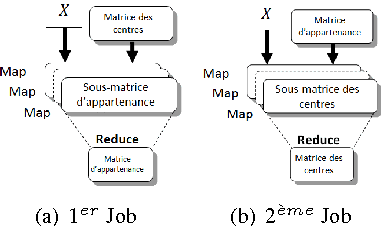


When it comes to cluster massive data, response time, disk access and quality of formed classes becoming major issues for companies. It is in this context that we have come to define a clustering framework for large scale heterogeneous data that contributes to the resolution of these issues. The proposed framework is based on, firstly, the descriptive analysis based on MCA, and secondly, the MapReduce paradigm in a large scale environment. The results are encouraging and prove the efficiency of the hybrid deployment on response quality and time component as on qualitative and quantitative data.
* 6 pages, in French, 8 figures