 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpinion Mining and Analysis Using Hybrid Deep Neural Networks
Nov 16, 2025



Understanding customer attitudes has become a critical component of decision-making due to the growing influence of social media and e-commerce. Text-based opinions are the most structured, hence playing an important role in sentiment analysis. Most of the existing methods, which include lexicon-based approaches and traditional machine learning techniques, are insufficient for handling contextual nuances and scalability. While the latter has limitations in model performance and generalization, deep learning (DL) has achieved improvement, especially on semantic relationship capturing with recurrent neural networks (RNNs) and convolutional neural networks (CNNs). The aim of the study is to enhance opinion mining by introducing a hybrid deep neural network model that combines a bidirectional gated recurrent unit (BGRU) and long short-term memory (LSTM) layers to improve sentiment analysis, particularly addressing challenges such as contextual nuance, scalability, and class imbalance. To substantiate the efficacy of the proposed model, we conducted comprehensive experiments utilizing benchmark datasets, encompassing IMDB movie critiques and Amazon product evaluations. The introduced hybrid BGRULSTM (HBGRU-LSTM) architecture attained a testing accuracy of 95%, exceeding the performance of traditional DL frameworks such as LSTM (93.06%), CNN+LSTM (93.31%), and GRU+LSTM (92.20%). Moreover, our model exhibited a noteworthy enhancement in recall for negative sentiments, escalating from 86% (unbalanced dataset) to 96% (balanced dataset), thereby ensuring a more equitable and just sentiment classification. Furthermore, the model diminished misclassification loss from 20.24% for unbalanced to 13.3% for balanced dataset, signifying enhanced generalization and resilience.
* 22 pages, 4 figures, 11 tables
Let's Predict Who Will Move to a New Job
Sep 15, 2023Any company's human resources department faces the challenge of predicting whether an applicant will search for a new job or stay with the company. In this paper, we discuss how machine learning (ML) is used to predict who will move to a new job. First, the data is pre-processed into a suitable format for ML models. To deal with categorical features, data encoding is applied and several MLA (ML Algorithms) are performed including Random Forest (RF), Logistic Regression (LR), Decision Tree (DT), and eXtreme Gradient Boosting (XGBoost). To improve the performance of ML models, the synthetic minority oversampling technique (SMOTE) is used to retain them. Models are assessed using decision support metrics such as precision, recall, F1-Score, and accuracy.
* 5 pages, 3 figures
Dimensionality reduction with missing values imputation
Jul 02, 2017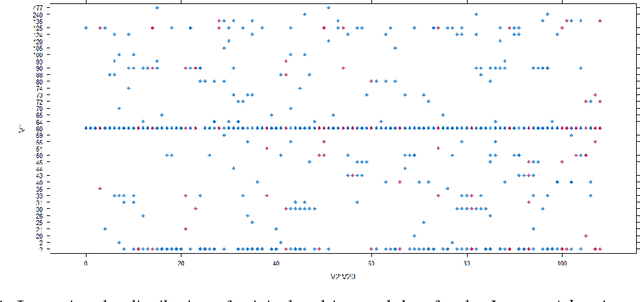
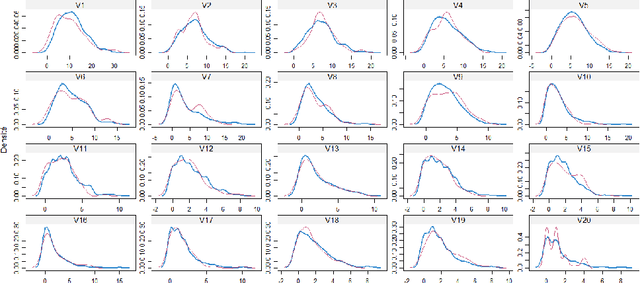

In this study, we propose a new statical approach for high-dimensionality reduction of heterogenous data that limits the curse of dimensionality and deals with missing values. To handle these latter, we propose to use the Random Forest imputation's method. The main purpose here is to extract useful information and so reducing the search space to facilitate the data exploration process. Several illustrative numeric examples, using data coming from publicly available machine learning repositories are also included. The experimental component of the study shows the efficiency of the proposed analytical approach.
Classification non supervisée des données hétérogènes à large échelle
Jul 02, 2017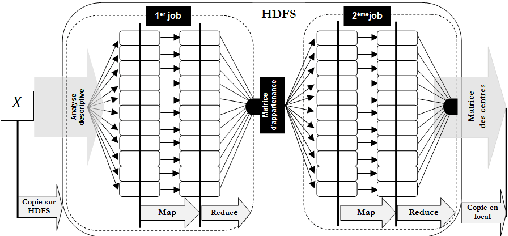
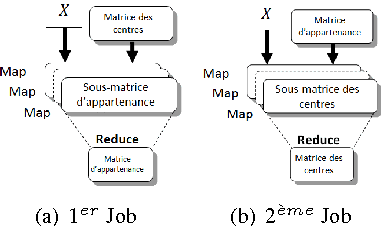


When it comes to cluster massive data, response time, disk access and quality of formed classes becoming major issues for companies. It is in this context that we have come to define a clustering framework for large scale heterogeneous data that contributes to the resolution of these issues. The proposed framework is based on, firstly, the descriptive analysis based on MCA, and secondly, the MapReduce paradigm in a large scale environment. The results are encouraging and prove the efficiency of the hybrid deployment on response quality and time component as on qualitative and quantitative data.
* 6 pages, in French, 8 figures