 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-Based Differentiable Learning of Non-Parametric Directed Acyclic Graphical Models
Aug 20, 2024



Causal discovery amounts to learning a directed acyclic graph (DAG) that encodes a causal model. This model selection problem can be challenging due to its large combinatorial search space, particularly when dealing with non-parametric causal models. Recent research has sought to bypass the combinatorial search by reformulating causal discovery as a continuous optimization problem, employing constraints that ensure the acyclicity of the graph. In non-parametric settings, existing approaches typically rely on finite-dimensional approximations of the relationships between nodes, resulting in a score-based continuous optimization problem with a smooth acyclicity constraint. In this work, we develop an alternative approximation method by utilizing reproducing kernel Hilbert spaces (RKHS) and applying general sparsity-inducing regularization terms based on partial derivatives. Within this framework, we introduce an extended RKHS representer theorem. To enforce acyclicity, we advocate the log-determinant formulation of the acyclicity constraint and show its stability. Finally, we assess the performance of our proposed RKHS-DAGMA procedure through simulations and illustrative data analyses.
Online nonparametric regression with Sobolev kernels
Feb 06, 2021
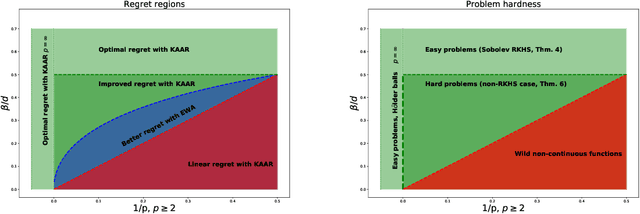


In this work we investigate the variation of the online kernelized ridge regression algorithm in the setting of $d-$dimensional adversarial nonparametric regression. We derive the regret upper bounds on the classes of Sobolev spaces $W_{p}^{\beta}(\mathcal{X})$, $p\geq 2, \beta>\frac{d}{p}$. The upper bounds are supported by the minimax regret analysis, which reveals that in the cases $\beta> \frac{d}{2}$ or $p=\infty$ these rates are (essentially) optimal. Finally, we compare the performance of the kernelized ridge regression forecaster to the known non-parametric forecasters in terms of the regret rates and their computational complexity as well as to the excess risk rates in the setting of statistical (i.i.d.) nonparametric regression.
Efficient Regularized Piecewise-Linear Regression Trees
Jun 29, 2019

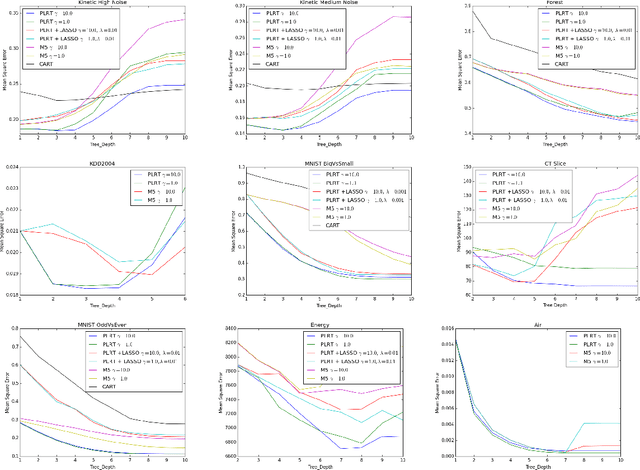
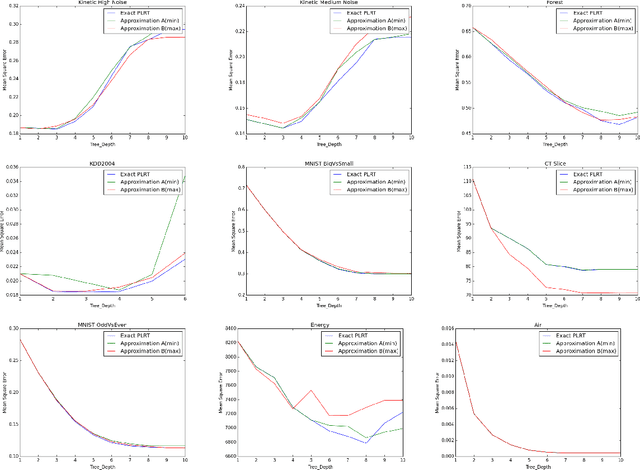
We present a detailed analysis of the class of regression decision tree algorithms which employ a regulized piecewise-linear node-splitting criterion and have regularized linear models at the leaves. From a theoretic standpoint, based on Rademacher complexity framework, we present new high-probability upper bounds for the generalization error for the proposed classes of regularized regression decision tree algorithms, including LASSO-type, and $\ell_{2}$ regularization for linear models at the leaves. Theoretical result are further extended by considering a general type of variable selection procedure. Furthermore, in our work we demonstrate that the class of piecewise-linear regression trees is not only numerically stable but can be made tractable via an algorithmic implementation, presented herein, as well as with the help of modern GPU technology. Empirically, we present results on multiple datasets which highlight the strengths and potential pitfalls, of the proposed tree algorithms compared to baselines which grow trees based on piecewise constant models.
Restless dependent bandits with fading memory
Jun 25, 2019We study the stochastic multi-armed bandit problem in the case when the arm samples are dependent over time and generated from so-called weak $\cC$-mixing processes. We establish a $\cC-$Mix Improved UCB agorithm and provide both problem-dependent and independent regret analysis in two different scenarios. In the first, so-called fast-mixing scenario, we show that pseudo-regret enjoys the same upper bound (up to a factor) as for i.i.d. observations; whereas in the second, slow mixing scenario, we discover a surprising effect, that the regret upper bound is similar to the independent case, with an incremental {\em additive} term which does not depend on the number of arms. The analysis of slow mixing scenario is supported with a minmax lower bound, which (up to a $\log(T)$ factor) matches the obtained upper bound.
Concentration of weakly dependent Banach-valued sums and applications to kernel learning methods
Dec 05, 2017
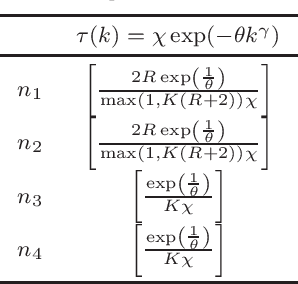
We obtain a new Bernstein-type inequality for sums of Banach-valued random variables satisfying a weak dependence assumption of general type and under certain smoothness assumptions of the underlying Banach norm. We use this inequality in order to investigate in asymptotical regime the error upper bounds for the broad family of spectral regularization methods for reproducing kernel decision rules, when trained on a sample coming from a $\tau-$mixing process.