 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Topological Sorting Criterion for Random Causal Directed Acyclic Graphs
May 07, 2026Random directed acyclic graphs (DAGs) based on imposing an order on Erdős-Rényi and scale free random graphs are widely used for evaluating causal discovery algorithms. We show that in such DAGs, the set of nodes reachable via open paths, termed relatives, increases monotonically along the causal order. We assess the prevalence of this pattern numerically, and demonstrate that it can be exploited for causal order recovery via sorting by the estimated number of relatives. We note that many simulations in the literature feature settings where this yields an excellent proxy for the causal order, and show that a strict increase of relatives along the causal order leads to a singular Markov equivalence class. We propose sampling time-series DAGs as a possible alternative and discuss implications for causal discovery algorithms and their evaluation on synthetic data.
Transductive Conformal Inference for Ranking
Jan 20, 2025



We introduce a method based on Conformal Prediction (CP) to quantify the uncertainty of full ranking algorithms. We focus on a specific scenario where $n + m$ items are to be ranked by some ''black box'' algorithm. It is assumed that the relative (ground truth) ranking of n of them is known. The objective is then to quantify the error made by the algorithm on the ranks of the m new items among the total $(n + m)$. In such a setting, the true ranks of the n original items in the total $(n + m)$ depend on the (unknown) true ranks of the m new ones. Consequently, we have no direct access to a calibration set to apply a classical CP method. To address this challenge, we propose to construct distribution-free bounds of the unknown conformity scores using recent results on the distribution of conformal p-values. Using these scores upper bounds, we provide valid prediction sets for the rank of any item. We also control the false coverage proportion, a crucial quantity when dealing with multiple prediction sets. Finally, we empirically show on both synthetic and real data the efficiency of our CP method.
Estimation of multiple mean vectors in high dimension
Mar 22, 2024



We endeavour to estimate numerous multi-dimensional means of various probability distributions on a common space based on independent samples. Our approach involves forming estimators through convex combinations of empirical means derived from these samples. We introduce two strategies to find appropriate data-dependent convex combination weights: a first one employing a testing procedure to identify neighbouring means with low variance, which results in a closed-form plug-in formula for the weights, and a second one determining weights via minimization of an upper confidence bound on the quadratic risk.Through theoretical analysis, we evaluate the improvement in quadratic risk offered by our methods compared to the empirical means. Our analysis focuses on a dimensional asymptotics perspective, showing that our methods asymptotically approach an oracle (minimax) improvement as the effective dimension of the data increases.We demonstrate the efficacy of our methods in estimating multiple kernel mean embeddings through experiments on both simulated and real-world datasets.
Transductive conformal inference with adaptive scores
Oct 27, 2023Conformal inference is a fundamental and versatile tool that provides distribution-free guarantees for many machine learning tasks. We consider the transductive setting, where decisions are made on a test sample of $m$ new points, giving rise to $m$ conformal $p$-values. {While classical results only concern their marginal distribution, we show that their joint distribution follows a P\'olya urn model, and establish a concentration inequality for their empirical distribution function.} The results hold for arbitrary exchangeable scores, including {\it adaptive} ones that can use the covariates of the test+calibration samples at training stage for increased accuracy. We demonstrate the usefulness of these theoretical results through uniform, in-probability guarantees for two machine learning tasks of current interest: interval prediction for transductive transfer learning and novelty detection based on two-class classification.
Label Shift Quantification with Robustness Guarantees via Distribution Feature Matching
Jul 02, 2023


Quantification learning deals with the task of estimating the target label distribution under label shift. In this paper, we first present a unifying framework, distribution feature matching (DFM), that recovers as particular instances various estimators introduced in previous literature. We derive a general performance bound for DFM procedures, improving in several key aspects upon previous bounds derived in particular cases. We then extend this analysis to study robustness of DFM procedures in the misspecified setting under departure from the exact label shift hypothesis, in particular in the case of contamination of the target by an unknown distribution. These theoretical findings are confirmed by a detailed numerical study on simulated and real-world datasets. We also introduce an efficient, scalable and robust version of kernel-based DFM using the Random Fourier Feature principle.
Covariance Adaptive Best Arm Identification
Jun 05, 2023
We consider the problem of best arm identification in the multi-armed bandit model, under fixed confidence. Given a confidence input $\delta$, the goal is to identify the arm with the highest mean reward with a probability of at least 1 -- $\delta$, while minimizing the number of arm pulls. While the literature provides solutions to this problem under the assumption of independent arms distributions, we propose a more flexible scenario where arms can be dependent and rewards can be sampled simultaneously. This framework allows the learner to estimate the covariance among the arms distributions, enabling a more efficient identification of the best arm. The relaxed setting we propose is relevant in various applications, such as clinical trials, where similarities between patients or drugs suggest underlying correlations in the outcomes. We introduce new algorithms that adapt to the unknown covariance of the arms and demonstrate through theoretical guarantees that substantial improvement can be achieved over the standard setting. Additionally, we provide new lower bounds for the relaxed setting and present numerical simulations that support their theoretical findings.
Fast rates for prediction with limited expert advice
Oct 27, 2021We investigate the problem of minimizing the excess generalization error with respect to the best expert prediction in a finite family in the stochastic setting, under limited access to information. We assume that the learner only has access to a limited number of expert advices per training round, as well as for prediction. Assuming that the loss function is Lipschitz and strongly convex, we show that if we are allowed to see the advice of only one expert per round for T rounds in the training phase, or to use the advice of only one expert for prediction in the test phase, the worst-case excess risk is $\Omega$(1/ $\sqrt$ T) with probability lower bounded by a constant. However, if we are allowed to see at least two actively chosen expert advices per training round and use at least two experts for prediction, the fast rate O(1/T) can be achieved. We design novel algorithms achieving this rate in this setting, and in the setting where the learner has a budget constraint on the total number of observed expert advices, and give precise instance-dependent bounds on the number of training rounds and queries needed to achieve a given generalization error precision.
Topologically penalized regression on manifolds
Oct 26, 2021
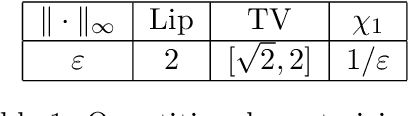
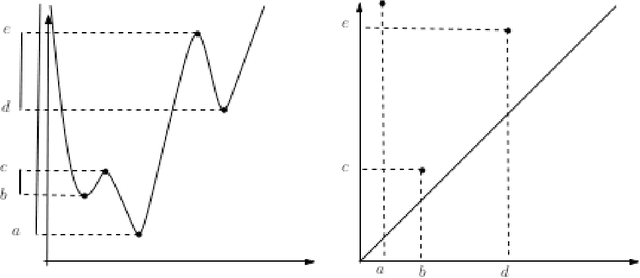

We study a regression problem on a compact manifold M. In order to take advantage of the underlying geometry and topology of the data, the regression task is performed on the basis of the first several eigenfunctions of the Laplace-Beltrami operator of the manifold, that are regularized with topological penalties. The proposed penalties are based on the topology of the sub-level sets of either the eigenfunctions or the estimated function. The overall approach is shown to yield promising and competitive performance on various applications to both synthetic and real data sets. We also provide theoretical guarantees on the regression function estimates, on both its prediction error and its smoothness (in a topological sense). Taken together, these results support the relevance of our approach in the case where the targeted function is "topologically smooth".
Error rate control for classification rules in multiclass mixture models
Sep 29, 2021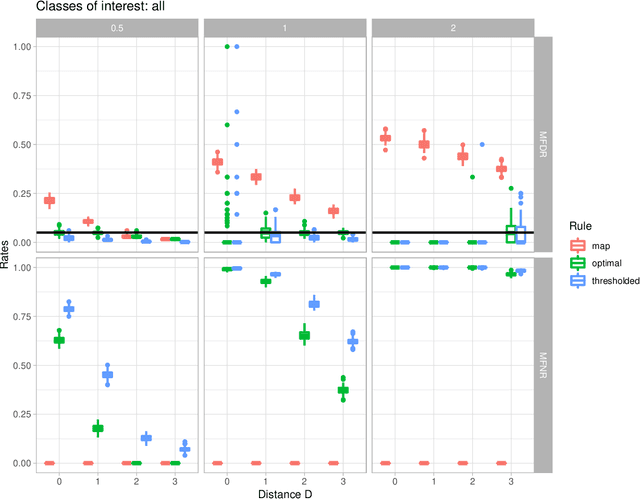
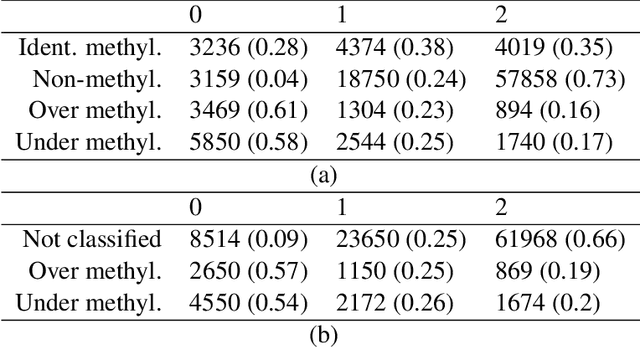
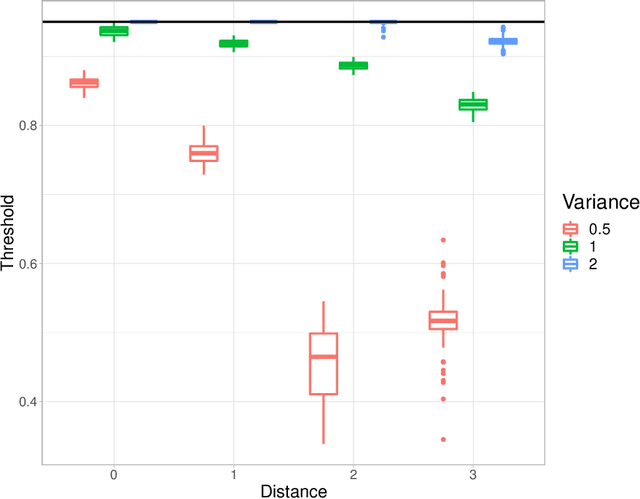
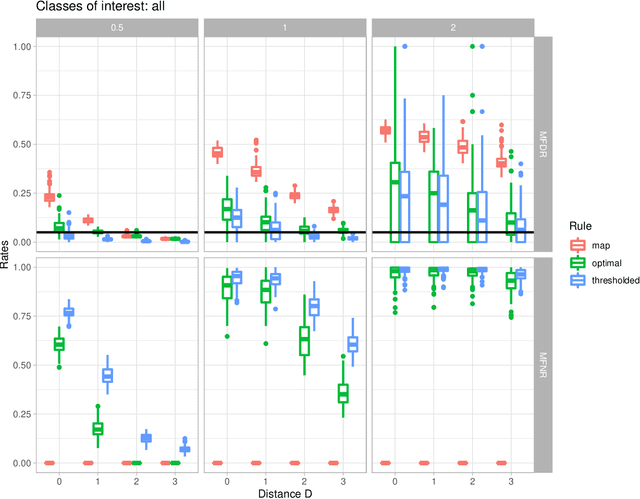
In the context of finite mixture models one considers the problem of classifying as many observations as possible in the classes of interest while controlling the classification error rate in these same classes. Similar to what is done in the framework of statistical test theory, different type I and type II-like classification error rates can be defined, along with their associated optimal rules, where optimality is defined as minimizing type II error rate while controlling type I error rate at some nominal level. It is first shown that finding an optimal classification rule boils down to searching an optimal region in the observation space where to apply the classical Maximum A Posteriori (MAP) rule. Depending on the misclassification rate to be controlled, the shape of the optimal region is provided, along with a heuristic to compute the optimal classification rule in practice. In particular, a multiclass FDR-like optimal rule is defined and compared to the thresholded MAP rules that is used in most applications. It is shown on both simulated and real datasets that the FDR-like optimal rule may be significantly less conservative than the thresholded MAP rule.
Nonasymptotic one-and two-sample tests in high dimension with unknown covariance structure
Sep 01, 2021Let $\mathbf{X} = (X_i)_{1\leq i \leq n}$ be an i.i.d. sample of square-integrable variables in $\mathbb{R}^d$, with common expectation $\mu$ and covariance matrix $\Sigma$, both unknown. We consider the problem of testing if $\mu$ is $\eta$-close to zero, i.e. $\|\mu\| \leq \eta $ against $\|\mu\| \geq (\eta + \delta)$; we also tackle the more general two-sample mean closeness testing problem. The aim of this paper is to obtain nonasymptotic upper and lower bounds on the minimal separation distance $\delta$ such that we can control both the Type I and Type II errors at a given level. The main technical tools are concentration inequalities, first for a suitable estimator of $\|\mu\|^2$ used a test statistic, and secondly for estimating the operator and Frobenius norms of $\Sigma$ coming into the quantiles of said test statistic. These properties are obtained for Gaussian and bounded distributions. A particular attention is given to the dependence in the pseudo-dimension $d_*$ of the distribution, defined as $d_* := \|\Sigma\|_2^2/\|\Sigma\|_\infty^2$. In particular, for $\eta=0$, the minimum separation distance is ${\Theta}(d_*^{\frac{1}{4}}\sqrt{\|\Sigma\|_\infty/n})$, in contrast with the minimax estimation distance for $\mu$, which is ${\Theta}(d_e^{\frac{1}{2}}\sqrt{\|\Sigma\|_\infty/n})$ (where $d_e:=\|\Sigma\|_1/\|\Sigma\|_\infty$). This generalizes a phenomenon spelled out in particular by Baraud (2002).