 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Single Neuron with Gradient Methods
Feb 11, 2020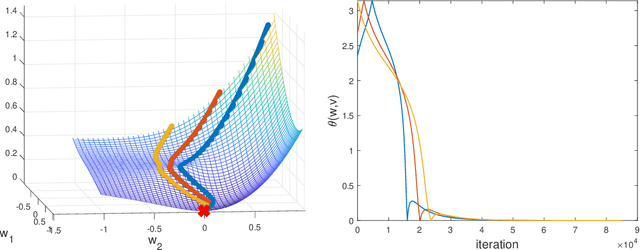
We consider the fundamental problem of learning a single neuron $x \mapsto\sigma(w^\top x)$ using standard gradient methods. As opposed to previous works, which considered specific (and not always realistic) input distributions and activation functions $\sigma(\cdot)$, we ask whether a more general result is attainable, under milder assumptions. On the one hand, we show that some assumptions on the distribution and the activation function are necessary. On the other hand, we prove positive guarantees under mild assumptions, which go beyond those studied in the literature so far. We also point out and study the challenges in further strengthening and generalizing our results.
Proving the Lottery Ticket Hypothesis: Pruning is All You Need
Feb 03, 2020The lottery ticket hypothesis (Frankle and Carbin, 2018), states that a randomly-initialized network contains a small subnetwork such that, when trained in isolation, can compete with the performance of the original network. We prove an even stronger hypothesis (as was also conjectured in Ramanujan et al., 2019), showing that for every bounded distribution and every target network with bounded weights, a sufficiently over-parameterized neural network with random weights contains a subnetwork with roughly the same accuracy as the target network, without any further training.
The Complexity of Finding Stationary Points with Stochastic Gradient Descent
Oct 04, 2019
We study the iteration complexity of stochastic gradient descent (SGD) for minimizing the gradient norm of smooth, possibly nonconvex functions. We provide several results, implying that the classical $\mathcal{O}(\epsilon^{-4})$ upper bound (for making the average gradient norm less than $\epsilon$) cannot be improved upon, unless a combination of additional assumptions is made. Notably, this holds even if we limit ourselves to convex quadratic functions. We also show that for nonconvex functions, the feasibility of minimizing gradients with SGD is surprisingly sensitive to the choice of optimality criteria.
How Good is SGD with Random Shuffling?
Jul 31, 2019
We study the performance of stochastic gradient descent (SGD) on smooth and strongly-convex finite-sum optimization problems. In contrast to the majority of existing theoretical works, which assume that individual functions are sampled with replacement, we focus here on popular but poorly-understood heuristics, which involve going over random permutations of the individual functions. This setting has been investigated in several recent works, but the optimal error rates remains unclear. In this paper, we provide lower bounds on the expected optimization error with these heuristics (using SGD with any constant step size), which elucidate their advantages and disadvantages. In particular, we prove that after $k$ passes over $n$ individual functions, if the functions are re-shuffled after every pass, the best possible optimization error for SGD is at least $\Omega\left(1/(nk)^2+1/nk^3\right)$, which partially corresponds to recently derived upper bounds, and we conjecture to be tight. Moreover, if the functions are only shuffled once, then the lower bound increases to $\Omega(1/nk^2)$. Since there are strictly smaller upper bounds for random reshuffling, this proves an inherent performance gap between SGD with single shuffling and repeated shuffling. As a more minor contribution, we also provide a non-asymptotic $\Omega(1/k^2)$ lower bound (independent of $n$) for cyclic gradient descent, where no random shuffling takes place.
Depth Separations in Neural Networks: What is Actually Being Separated?
May 26, 2019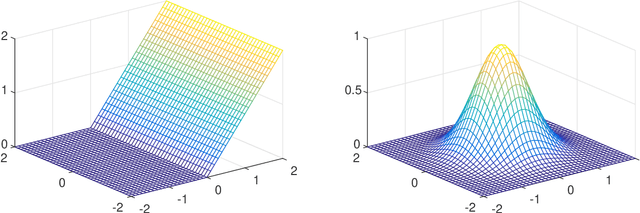
Existing depth separation results for constant-depth networks essentially show that certain radial functions in $\mathbb{R}^d$, which can be easily approximated with depth $3$ networks, cannot be approximated by depth $2$ networks, even up to constant accuracy, unless their size is exponential in $d$. However, the functions used to demonstrate this are rapidly oscillating, with a Lipschitz parameter scaling polynomially with the dimension $d$ (or equivalently, by scaling the function, the hardness result applies to $\mathcal{O}(1)$-Lipschitz functions only when the target accuracy $\epsilon$ is at most $\text{poly}(1/d)$). In this paper, we study whether such depth separations might still hold in the natural setting of $\mathcal{O}(1)$-Lipschitz radial functions, when $\epsilon$ does not scale with $d$. Perhaps surprisingly, we show that the answer is negative: In contrast to the intuition suggested by previous work, it \emph{is} possible to approximate $\mathcal{O}(1)$-Lipschitz radial functions with depth $2$, size $\text{poly}(d)$ networks, for every constant $\epsilon$. We complement it by showing that approximating such functions is also possible with depth $2$, size $\text{poly}(1/\epsilon)$ networks, for every constant $d$. Finally, we show that it is not possible to have polynomial dependence in both $d,1/\epsilon$ simultaneously. Overall, our results indicate that in order to show depth separations for expressing $\mathcal{O}(1)$-Lipschitz functions with constant accuracy -- if at all possible -- one would need fundamentally different techniques than existing ones in the literature.
On the Power and Limitations of Random Features for Understanding Neural Networks
Apr 01, 2019Recently, a spate of papers have provided positive theoretical results for training over-parameterized neural networks (where the network size is larger than what is needed to achieve low error). The key insight is that with sufficient over-parameterization, gradient-based methods will implicitly leave some components of the network relatively unchanged, so the optimization dynamics will behave as if those components are essentially fixed at their initial random values. In fact, fixing these explicitly leads to the well-known approach of learning with random features. In other words, these techniques imply that we can successfully learn with neural networks, whenever we can successfully learn with random features. In this paper, we first review these techniques, providing a simple and self-contained analysis for one-hidden-layer networks. We then argue that despite the impressive positive results, random feature approaches are also inherently limited in what they can explain. In particular, we rigorously show that random features cannot be used to learn even a single ReLU neuron with standard Gaussian inputs, unless the network size (or magnitude of the weights) is exponentially large. Since a single neuron is learnable with gradient-based methods, we conclude that we are still far from a satisfying general explanation for the empirical success of neural networks.
Space lower bounds for linear prediction
Feb 23, 2019We show that fundamental learning tasks, such as finding an approximate linear separator or linear regression, require memory at least \emph{quadratic} in the dimension, in a natural streaming setting. This implies that such problems cannot be solved (at least in this setting) by scalable memory-efficient streaming algorithms. Our results build on a memory lower bound for a simple linear-algebraic problem -- finding orthogonal vectors -- and utilize the estimates on the packing of the Grassmannian, the manifold of all linear subspaces of fixed dimension.
The Complexity of Making the Gradient Small in Stochastic Convex Optimization
Feb 14, 2019
We give nearly matching upper and lower bounds on the oracle complexity of finding $\epsilon$-stationary points ($\| \nabla F(x) \| \leq\epsilon$) in stochastic convex optimization. We jointly analyze the oracle complexity in both the local stochastic oracle model and the global oracle (or, statistical learning) model. This allows us to decompose the complexity of finding near-stationary points into optimization complexity and sample complexity, and reveals some surprising differences between the complexity of stochastic optimization versus learning. Notably, we show that in the global oracle/statistical learning model, only logarithmic dependence on smoothness is required to find a near-stationary point, whereas polynomial dependence on smoothness is necessary in the local stochastic oracle model. In other words, the separation in complexity between the two models can be exponential, and that the folklore understanding that smoothness is required to find stationary points is only weakly true for statistical learning. Our upper bounds are based on extensions of a recent "recursive regularization" technique proposed by Allen-Zhu (2018). We show how to extend the technique to achieve near-optimal rates, and in particular show how to leverage the extra information available in the global oracle model. Our algorithm for the global model can be implemented efficiently through finite sum methods, and suggests an interesting new computational-statistical tradeoff.
Global Non-convex Optimization with Discretized Diffusions
Oct 29, 2018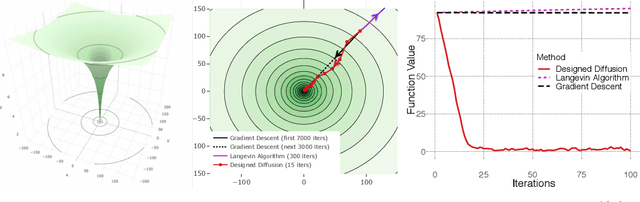
An Euler discretization of the Langevin diffusion is known to converge to the global minimizers of certain convex and non-convex optimization problems. We show that this property holds for any suitably smooth diffusion and that different diffusions are suitable for optimizing different classes of convex and non-convex functions. This allows us to design diffusions suitable for globally optimizing convex and non-convex functions not covered by the existing Langevin theory. Our non-asymptotic analysis delivers computable optimization and integration error bounds based on easily accessed properties of the objective and chosen diffusion. Central to our approach are new explicit Stein factor bounds on the solutions of Poisson equations. We complement these results with improved optimization guarantees for targets other than the standard Gibbs measure.
Are ResNets Provably Better than Linear Predictors?
Sep 27, 2018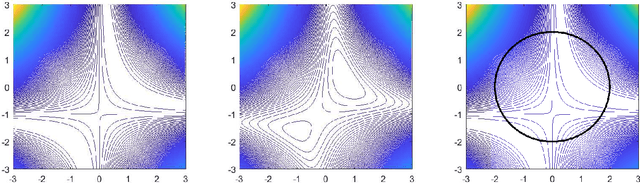
A residual network (or ResNet) is a standard deep neural net architecture, with state-of-the-art performance across numerous applications. The main premise of ResNets is that they allow the training of each layer to focus on fitting just the residual of the previous layer's output and the target output. Thus, we should expect that the trained network is no worse than what we can obtain if we remove the residual layers and train a shallower network instead. However, due to the non-convexity of the optimization problem, it is not at all clear that ResNets indeed achieve this behavior, rather than getting stuck at some arbitrarily poor local minimum. In this paper, we rigorously prove that arbitrarily deep, nonlinear residual units indeed exhibit this behavior, in the sense that the optimization landscape contains no local minima with value above what can be obtained with a linear predictor (namely a 1-layer network). Notably, we show this under minimal or no assumptions on the precise network architecture, data distribution, or loss function used. We also provide a quantitative analysis of approximate stationary points for this problem. Finally, we show that with a certain tweak to the architecture, training the network with standard stochastic gradient descent achieves an objective value close or better than any linear predictor.