 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolutionary Optimization for Pareto Front Learning
Oct 07, 2021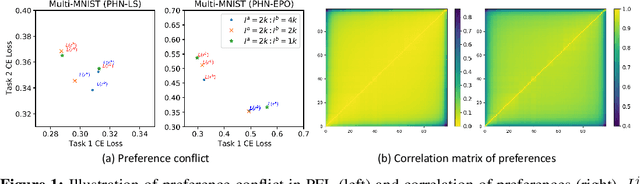
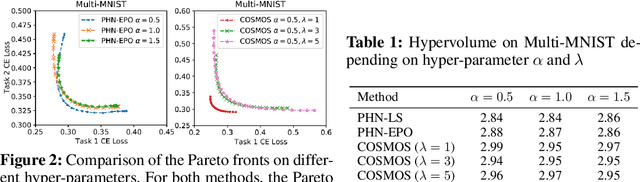
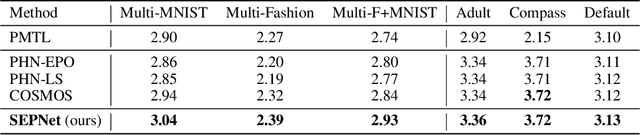
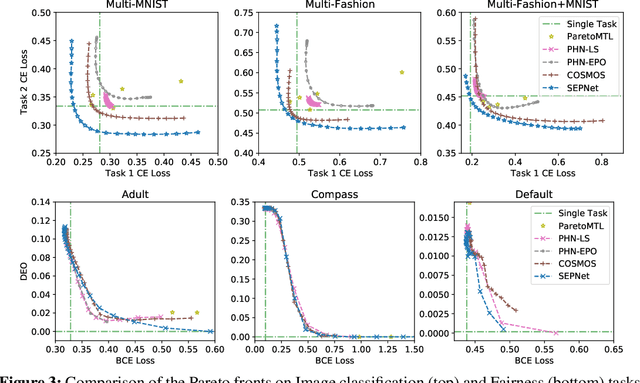
Multi-task learning (MTL), which aims to improve performance by learning multiple tasks simultaneously, inherently presents an optimization challenge due to multiple objectives. Hence, multi-objective optimization (MOO) approaches have been proposed for multitasking problems. Recent MOO methods approximate multiple optimal solutions (Pareto front) with a single unified model, which is collectively referred to as Pareto front learning (PFL). In this paper, we show that PFL can be re-formulated into another MOO problem with multiple objectives, each of which corresponds to different preference weights for the tasks. We leverage an evolutionary algorithm (EA) to propose a method for PFL called self-evolutionary optimization (SEO) by directly maximizing the hypervolume. By using SEO, the neural network learns to approximate the Pareto front conditioned on multiple hyper-parameters that drastically affect the hypervolume. Then, by generating a population of approximations simply by inferencing the network, the hyper-parameters of the network can be optimized by EA. Utilizing SEO for PFL, we also introduce self-evolutionary Pareto networks (SEPNet), enabling the unified model to approximate the entire Pareto front set that maximizes the hypervolume. Extensive experimental results confirm that SEPNet can find a better Pareto front than the current state-of-the-art methods while minimizing the increase in model size and training cost.
Few-Shot Object Detection by Attending to Per-Sample-Prototype
Sep 16, 2021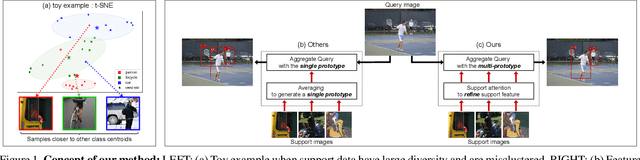

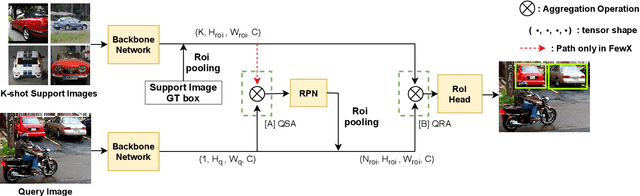

Few-shot object detection aims to detect instances of specific categories in a query image with only a handful of support samples. Although this takes less effort than obtaining enough annotated images for supervised object detection, it results in a far inferior performance compared to the conventional object detection methods. In this paper, we propose a meta-learning-based approach that considers the unique characteristics of each support sample. Rather than simply averaging the information of the support samples to generate a single prototype per category, our method can better utilize the information of each support sample by treating each support sample as an individual prototype. Specifically, we introduce two types of attention mechanisms for aggregating the query and support feature maps. The first is to refine the information of few-shot samples by extracting shared information between the support samples through attention. Second, each support sample is used as a class code to leverage the information by comparing similarities between each support feature and query features. Our proposed method is complementary to the previous methods, making it easy to plug and play for further improvement. We have evaluated our method on PASCAL VOC and COCO benchmarks, and the results verify the effectiveness of our method. In particular, the advantages of our method are maximized when there is more diversity among support data.
Dynamic Collective Intelligence Learning: Finding Efficient Sparse Model via Refined Gradients for Pruned Weights
Sep 10, 2021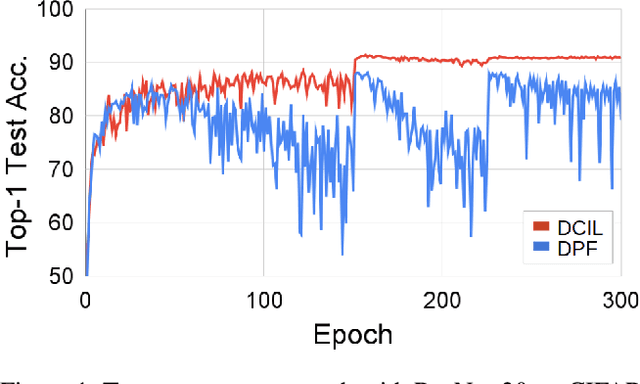
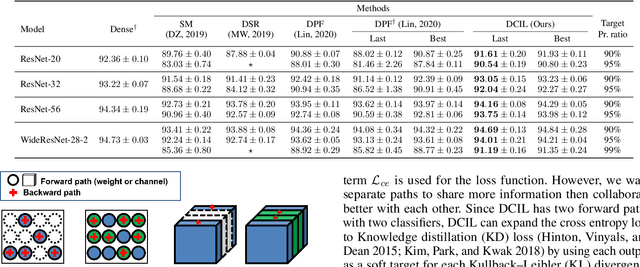
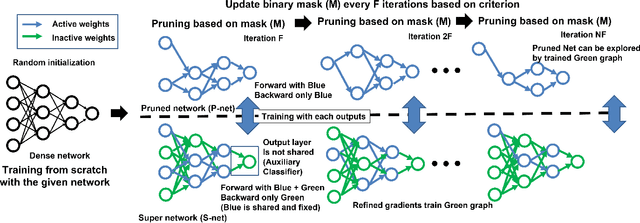
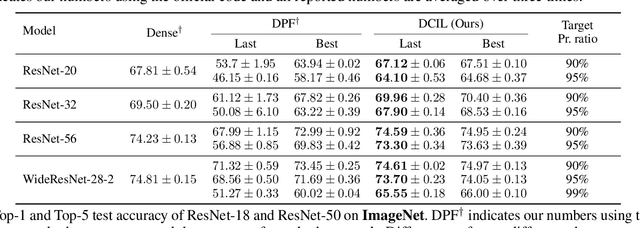
With the growth of deep neural networks (DNN), the number of DNN parameters has drastically increased. This makes DNN models hard to be deployed on resource-limited embedded systems. To alleviate this problem, dynamic pruning methods have emerged, which try to find diverse sparsity patterns during training by utilizing Straight-Through-Estimator (STE) to approximate gradients of pruned weights. STE can help the pruned weights revive in the process of finding dynamic sparsity patterns. However, using these coarse gradients causes training instability and performance degradation owing to the unreliable gradient signal of the STE approximation. In this work, to tackle this issue, we introduce refined gradients to update the pruned weights by forming dual forwarding paths from two sets (pruned and unpruned) of weights. We propose a novel Dynamic Collective Intelligence Learning (DCIL) which makes use of the learning synergy between the collective intelligence of both weight sets. We verify the usefulness of the refined gradients by showing enhancements in the training stability and the model performance on the CIFAR and ImageNet datasets. DCIL outperforms various previously proposed pruning schemes including other dynamic pruning methods with enhanced stability during training.
Normalization Matters in Weakly Supervised Object Localization
Jul 28, 2021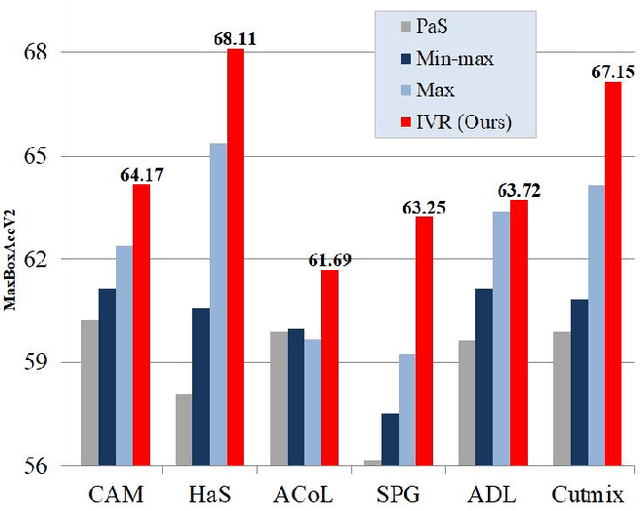
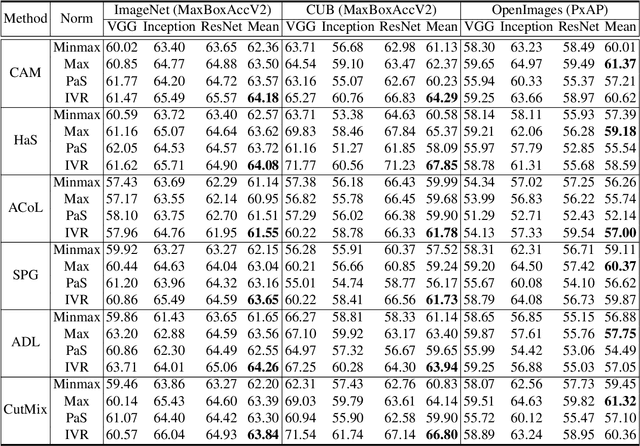
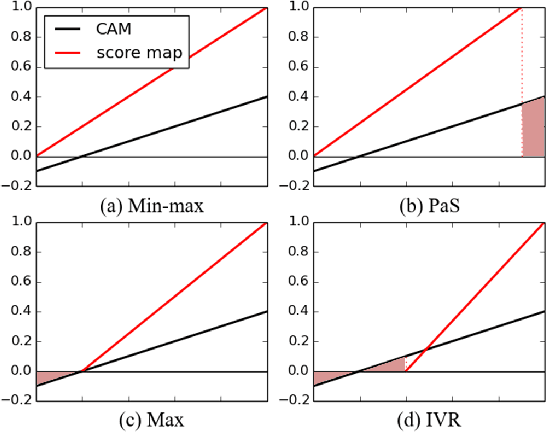
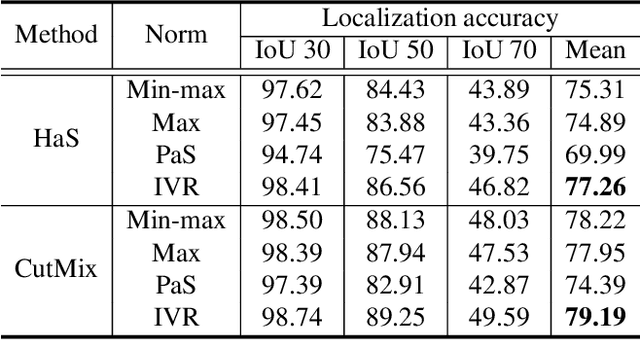
Weakly-supervised object localization (WSOL) enables finding an object using a dataset without any localization information. By simply training a classification model using only image-level annotations, the feature map of the model can be utilized as a score map for localization. In spite of many WSOL methods proposing novel strategies, there has not been any de facto standard about how to normalize the class activation map (CAM). Consequently, many WSOL methods have failed to fully exploit their own capacity because of the misuse of a normalization method. In this paper, we review many existing normalization methods and point out that they should be used according to the property of the given dataset. Additionally, we propose a new normalization method which substantially enhances the performance of any CAM-based WSOL methods. Using the proposed normalization method, we provide a comprehensive evaluation over three datasets (CUB, ImageNet and OpenImages) on three different architectures and observe significant performance gains over the conventional min-max normalization method in all the evaluated cases.
PQK: Model Compression via Pruning, Quantization, and Knowledge Distillation
Jun 25, 2021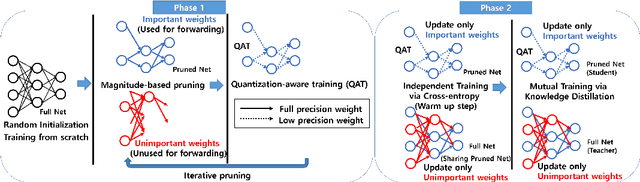
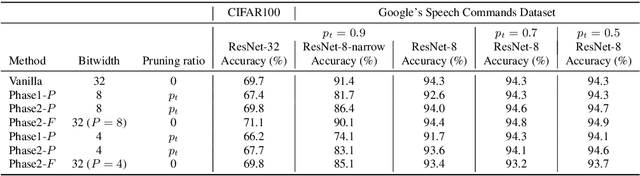
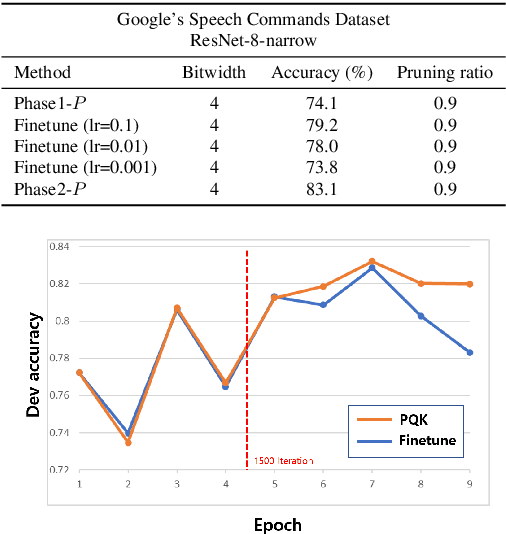
As edge devices become prevalent, deploying Deep Neural Networks (DNN) on edge devices has become a critical issue. However, DNN requires a high computational resource which is rarely available for edge devices. To handle this, we propose a novel model compression method for the devices with limited computational resources, called PQK consisting of pruning, quantization, and knowledge distillation (KD) processes. Unlike traditional pruning and KD, PQK makes use of unimportant weights pruned in the pruning process to make a teacher network for training a better student network without pre-training the teacher model. PQK has two phases. Phase 1 exploits iterative pruning and quantization-aware training to make a lightweight and power-efficient model. In phase 2, we make a teacher network by adding unimportant weights unused in phase 1 to a pruned network. By using this teacher network, we train the pruned network as a student network. In doing so, we do not need a pre-trained teacher network for the KD framework because the teacher and the student networks coexist within the same network. We apply our method to the recognition model and verify the effectiveness of PQK on keyword spotting (KWS) and image recognition.
LFI-CAM: Learning Feature Importance for Better Visual Explanation
May 03, 2021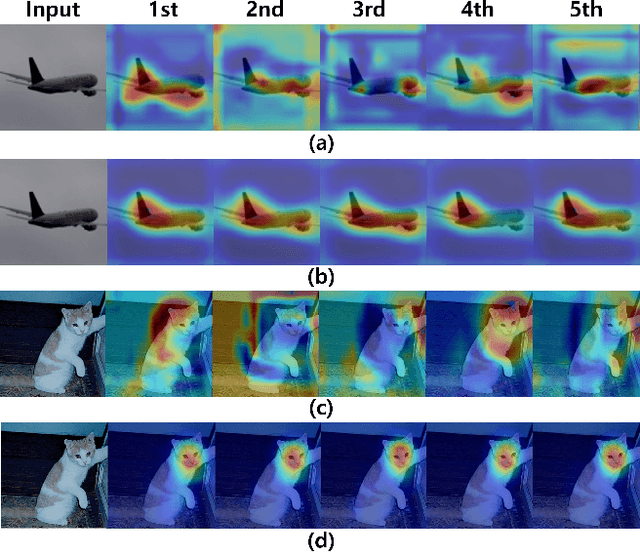
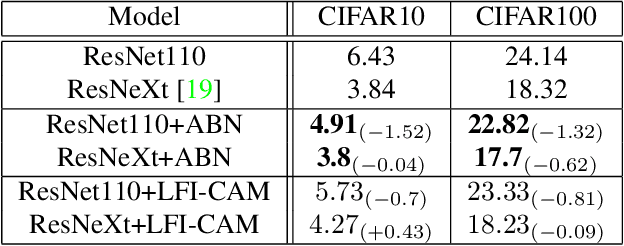
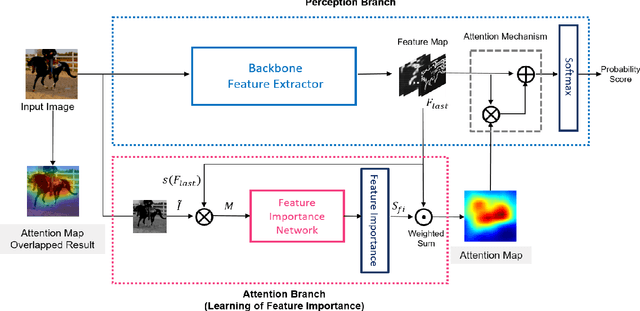
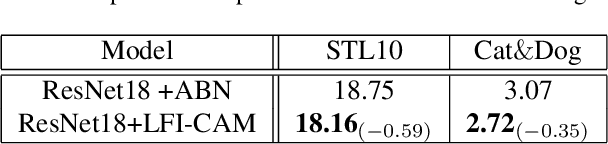
Class Activation Mapping (CAM) is a powerful technique used to understand the decision making of Convolutional Neural Network (CNN) in computer vision. Recently, there have been attempts not only to generate better visual explanations, but also to improve classification performance using visual explanations. However, the previous works still have their own drawbacks. In this paper, we propose a novel architecture, LFI-CAM, which is trainable for image classification and visual explanation in an end-to-end manner. LFI-CAM generates an attention map for visual explanation during forward propagation, at the same time, leverages the attention map to improve the classification performance through the attention mechanism. Our Feature Importance Network (FIN) focuses on learning the feature importance instead of directly learning the attention map to obtain a more reliable and consistent attention map. We confirmed that LFI-CAM model is optimized not only by learning the feature importance but also by enhancing the backbone feature representation to focus more on important features of the input image. Experimental results show that LFI-CAM outperforms the baseline models's accuracy on the classification tasks as well as significantly improves on the previous works in terms of attention map quality and stability over different hyper-parameters.
The U-Net based GLOW for Optical-Flow-free Video Interframe Generation
Apr 06, 2021
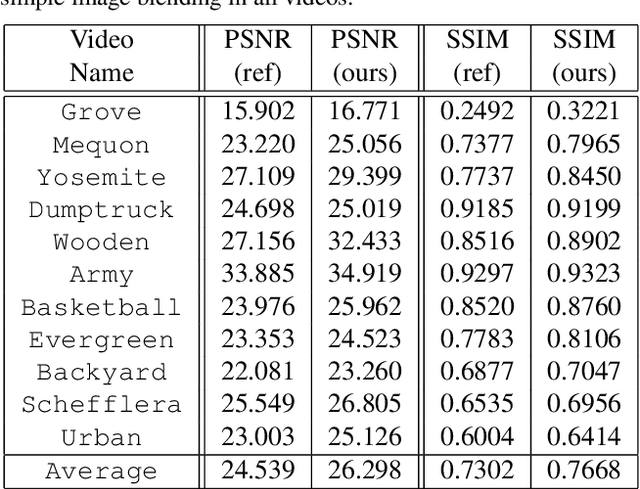
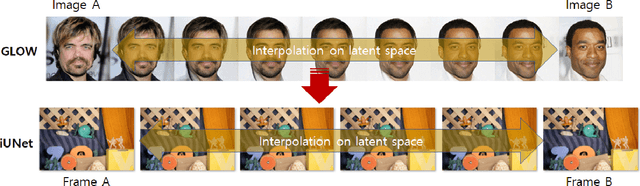
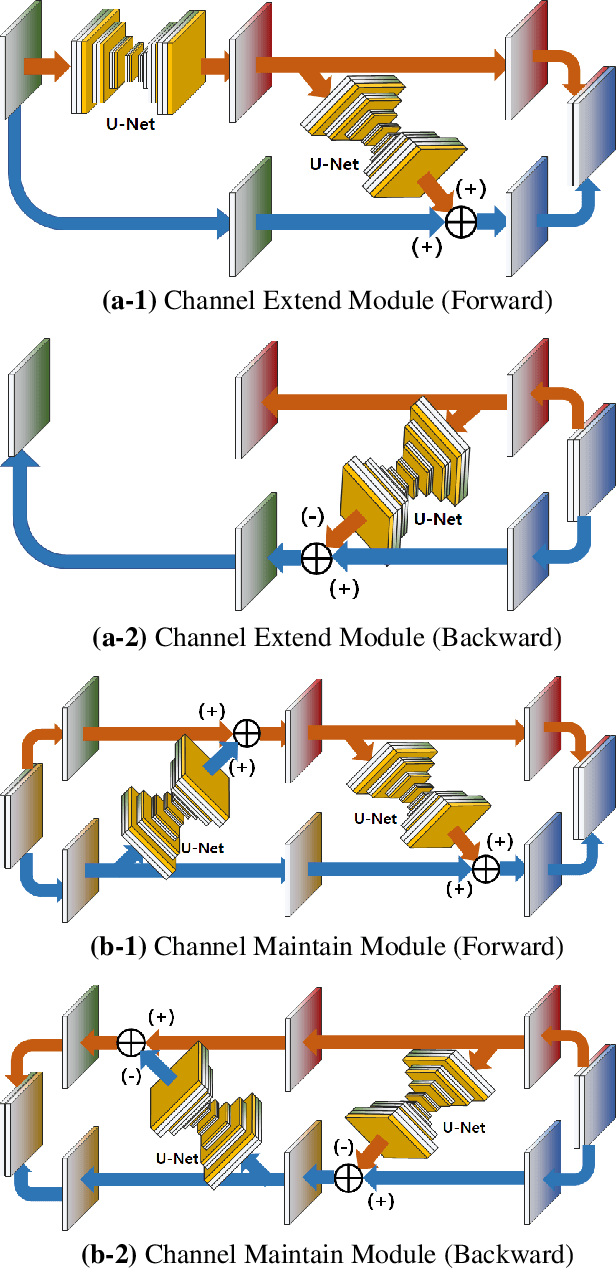
Video frame interpolation is the task of creating an interframe between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow . To enable this , we have tried to use a deep neural network with an invertible structure, and developed an U-Net based Generative Flow which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we \sam {confirmed the feasibility of the proposed algorithm and would like to suggest the U-Net based Generative Flow as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the world's first attempt to use invertible networks instead of optical flows for video interpolation.
Prototype-based Personalized Pruning
Mar 25, 2021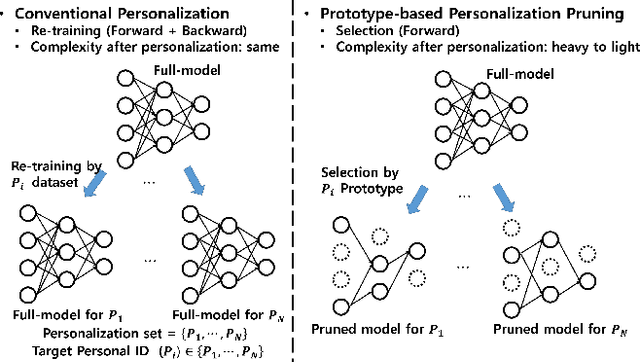
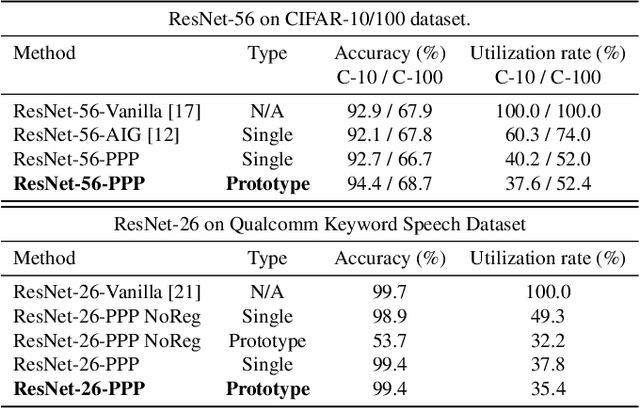
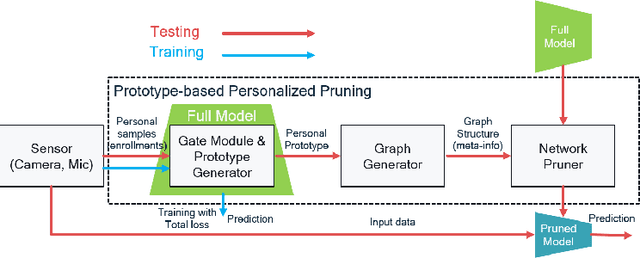
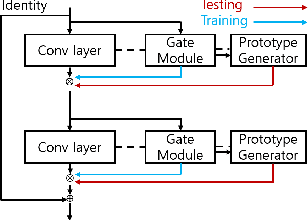
Nowadays, as edge devices such as smartphones become prevalent, there are increasing demands for personalized services. However, traditional personalization methods are not suitable for edge devices because retraining or finetuning is needed with limited personal data. Also, a full model might be too heavy for edge devices with limited resources. Unfortunately, model compression methods which can handle the model complexity issue also require the retraining phase. These multiple training phases generally need huge computational cost during on-device learning which can be a burden to edge devices. In this work, we propose a dynamic personalization method called prototype-based personalized pruning (PPP). PPP considers both ends of personalization and model efficiency. After training a network, PPP can easily prune the network with a prototype representing the characteristics of personal data and it performs well without retraining or finetuning. We verify the usefulness of PPP on a couple of tasks in computer vision and Keyword spotting.
Maximizing Cosine Similarity Between Spatial Features for Unsupervised Domain Adaptation in Semantic Segmentation
Mar 18, 2021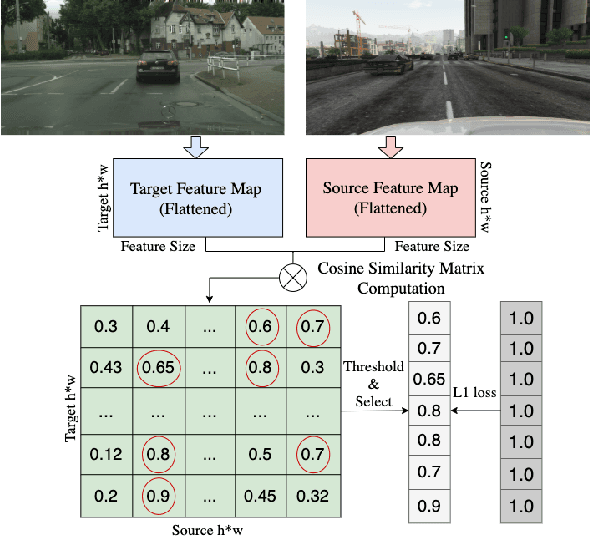
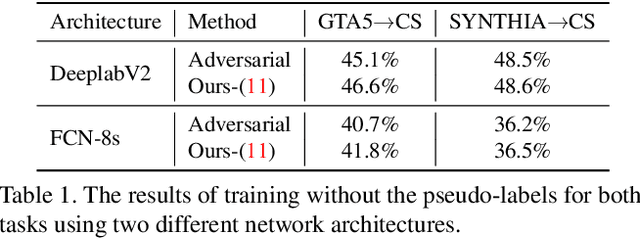
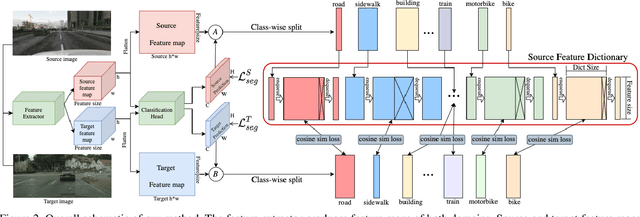
We propose a novel method that tackles the problem of unsupervised domain adaptation for semantic segmentation by maximizing the cosine similarity between the source and the target domain at the feature level. A segmentation network mainly consists of two parts, a feature extractor and a classification head. We expect that if we can make the two domains have small domain gap at the feature level, they would also have small domain discrepancy at the classification head. Our method computes a cosine similarity matrix between the source feature map and the target feature map, then we maximize the elements exceeding a threshold to guide the target features to have high similarity with the most similar source feature. Moreover, we use a class-wise source feature dictionary which stores the latest features of the source domain to prevent the unmatching problem when computing the cosine similarity matrix and be able to compare a target feature with various source features from various images. Through extensive experiments, we verify that our method gains performance on two unsupervised domain adaptation tasks (GTA5$\to$ Cityscaspes and SYNTHIA$\to$ Cityscapes).
Learning Dynamic BERT via Trainable Gate Variables and a Bi-modal Regularizer
Feb 19, 2021
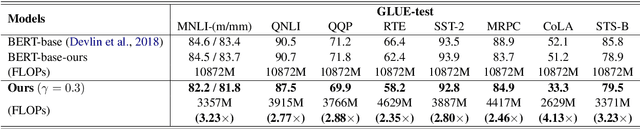
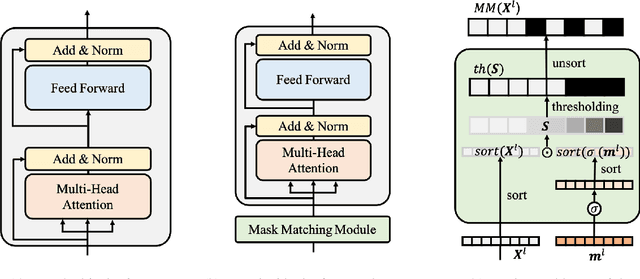
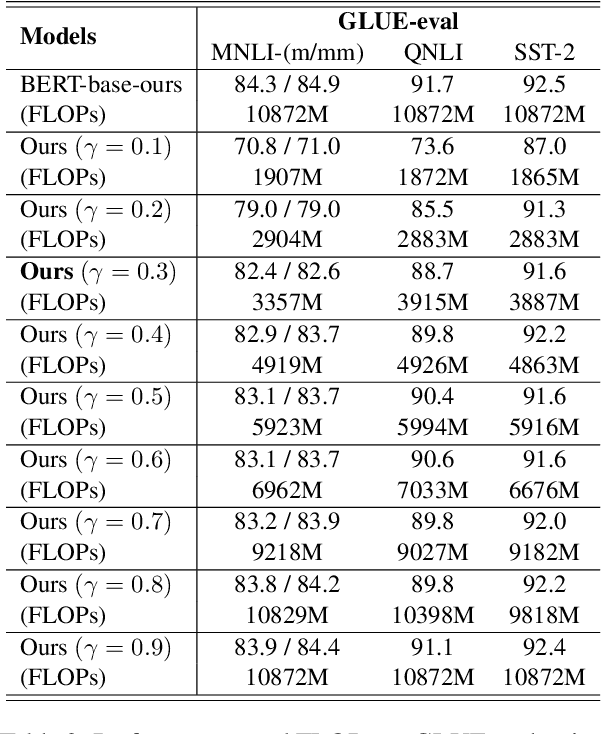
The BERT model has shown significant success on various natural language processing tasks. However, due to the heavy model size and high computational cost, the model suffers from high latency, which is fatal to its deployments on resource-limited devices. To tackle this problem, we propose a dynamic inference method on BERT via trainable gate variables applied on input tokens and a regularizer that has a bi-modal property. Our method shows reduced computational cost on the GLUE dataset with a minimal performance drop. Moreover, the model adjusts with a trade-off between performance and computational cost with the user-specified hyperparameter.