 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion Generation for Adaptive Education
Jun 08, 2021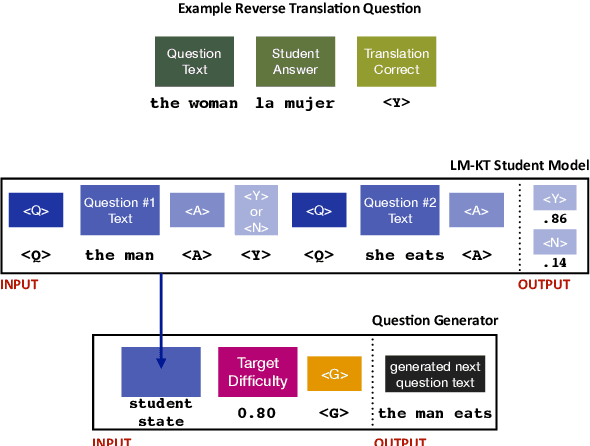
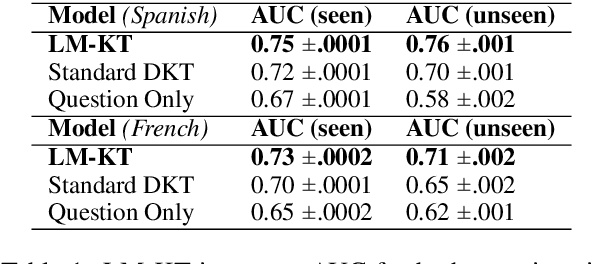
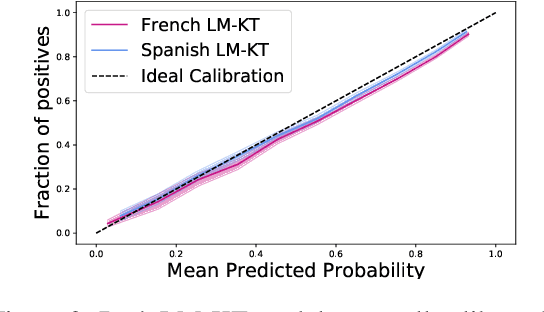
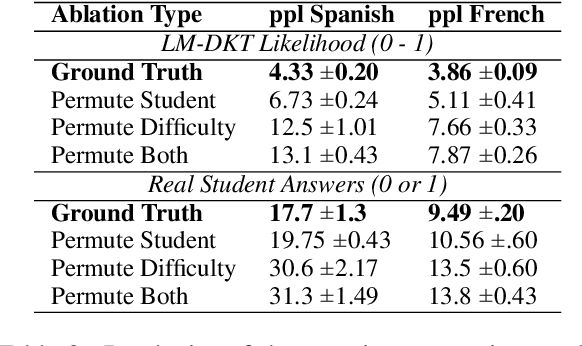
Intelligent and adaptive online education systems aim to make high-quality education available for a diverse range of students. However, existing systems usually depend on a pool of hand-made questions, limiting how fine-grained and open-ended they can be in adapting to individual students. We explore targeted question generation as a controllable sequence generation task. We first show how to fine-tune pre-trained language models for deep knowledge tracing (LM-KT). This model accurately predicts the probability of a student answering a question correctly, and generalizes to questions not seen in training. We then use LM-KT to specify the objective and data for training a model to generate questions conditioned on the student and target difficulty. Our results show we succeed at generating novel, well-calibrated language translation questions for second language learners from a real online education platform.
Emergent Communication of Generalizations
Jun 04, 2021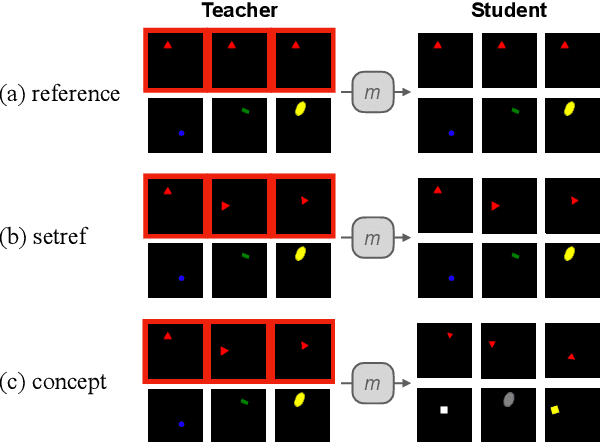
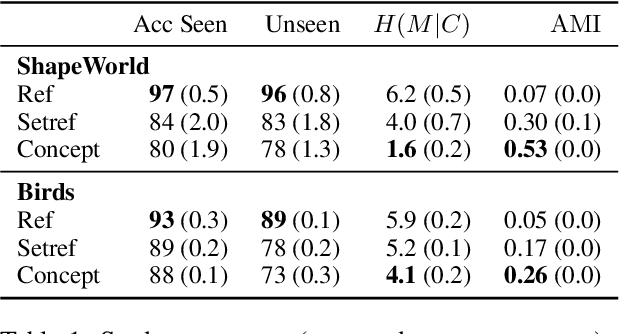

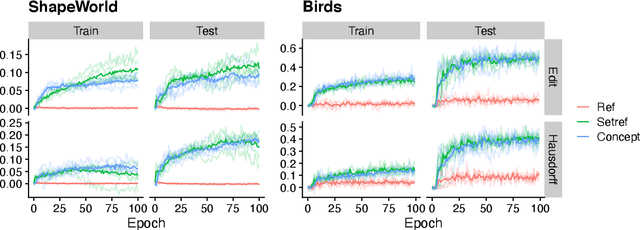
To build agents that can collaborate effectively with others, recent research has trained artificial agents to communicate with each other in Lewis-style referential games. However, this often leads to successful but uninterpretable communication. We argue that this is due to the game objective: communicating about a single object in a shared visual context is prone to overfitting and does not encourage language useful beyond concrete reference. In contrast, human language conveys a rich variety of abstract ideas. To promote such skills, we propose games that require communicating generalizations over sets of objects representing abstract visual concepts, optionally with separate contexts for each agent. We find that these games greatly improve systematicity and interpretability of the learned languages, according to several metrics in the literature. Finally, we propose a method for identifying logical operations embedded in the emergent languages by learning an approximate compositional reconstruction of the language.
Improving Compositionality of Neural Networks by Decoding Representations to Inputs
Jun 01, 2021
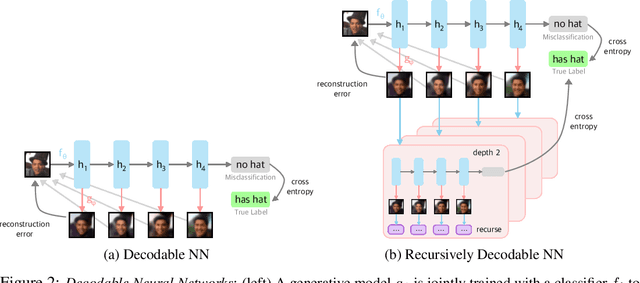
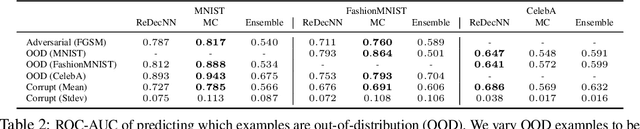

In traditional software programs, we take for granted how easy it is to debug code by tracing program logic from variables back to input, apply unit tests and assertion statements to block erroneous behavior, and compose programs together. But as the programs we write grow more complex, it becomes hard to apply traditional software to applications like computer vision or natural language. Although deep learning programs have demonstrated strong performance on these applications, they sacrifice many of the functionalities of traditional software programs. In this paper, we work towards bridging the benefits of traditional and deep learning programs by jointly training a generative model to constrain neural network activations to "decode" back to inputs. Doing so enables practitioners to probe and track information encoded in activation(s), apply assertion-like constraints on what information is encoded in an activation, and compose separate neural networks together in a plug-and-play fashion. In our experiments, we demonstrate applications of decodable representations to out-of-distribution detection, adversarial examples, calibration, and fairness -- while matching standard neural networks in accuracy.
Language Through a Prism: A Spectral Approach for Multiscale Language Representations
Nov 09, 2020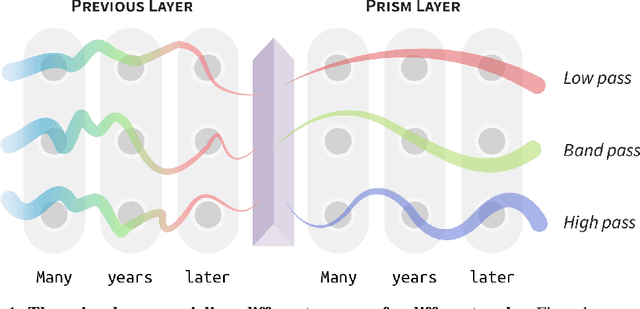
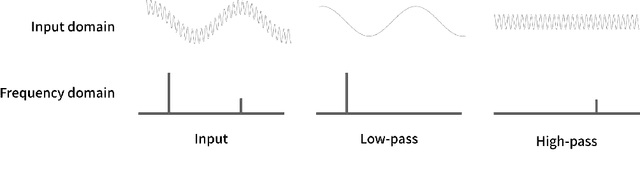
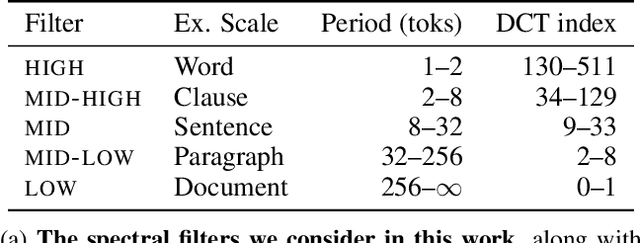
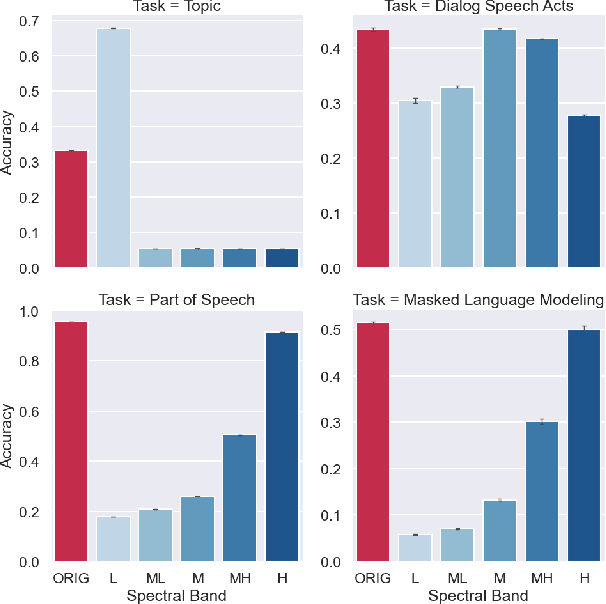
Language exhibits structure at different scales, ranging from subwords to words, sentences, paragraphs, and documents. To what extent do deep models capture information at these scales, and can we force them to better capture structure across this hierarchy? We approach this question by focusing on individual neurons, analyzing the behavior of their activations at different timescales. We show that signal processing provides a natural framework for separating structure across scales, enabling us to 1) disentangle scale-specific information in existing embeddings and 2) train models to learn more about particular scales. Concretely, we apply spectral filters to the activations of a neuron across an input, producing filtered embeddings that perform well on part of speech tagging (word-level), dialog speech acts classification (utterance-level), or topic classification (document-level), while performing poorly on the other tasks. We also present a prism layer for training models, which uses spectral filters to constrain different neurons to model structure at different scales. Our proposed BERT + Prism model can better predict masked tokens using long-range context and produces multiscale representations that perform better at utterance- and document-level tasks. Our methods are general and readily applicable to other domains besides language, such as images, audio, and video.
Viewmaker Networks: Learning Views for Unsupervised Representation Learning
Oct 14, 2020
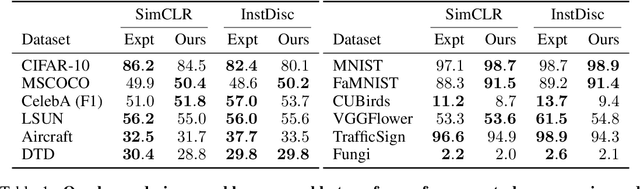
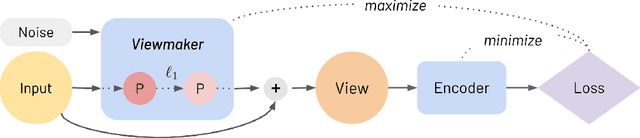
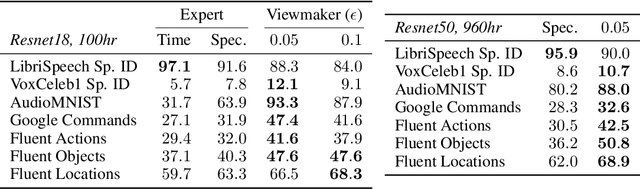
Many recent methods for unsupervised representation learning involve training models to be invariant to different "views," or transformed versions of an input. However, designing these views requires considerable human expertise and experimentation, hindering widespread adoption of unsupervised representation learning methods across domains and modalities. To address this, we propose viewmaker networks: generative models that learn to produce input-dependent views for contrastive learning. We train this network jointly with an encoder network to produce adversarial $\ell_p$ perturbations for an input, which yields challenging yet useful views without extensive human tuning. Our learned views, when applied to CIFAR-10, enable comparable transfer accuracy to the the well-studied augmentations used for the SimCLR model. Our views significantly outperforming baseline augmentations in speech (+9% absolute) and wearable sensor (+17% absolute) domains. We also show how viewmaker views can be combined with handcrafted views to improve robustness to common image corruptions. Our method demonstrates that learned views are a promising way to reduce the amount of expertise and effort needed for unsupervised learning, potentially extending its benefits to a much wider set of domains.
A Simple Framework for Uncertainty in Contrastive Learning
Oct 05, 2020
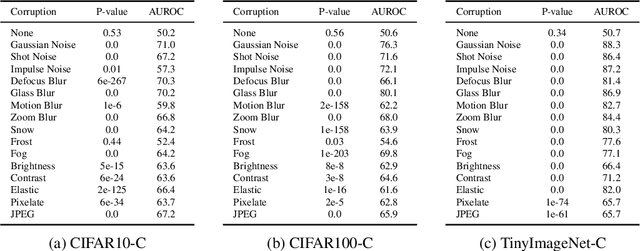
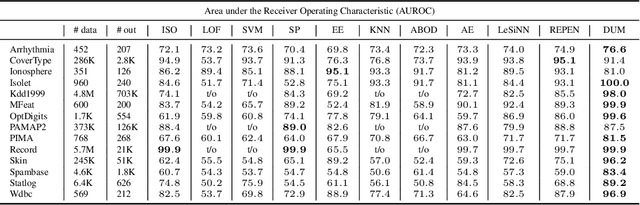

Contrastive approaches to representation learning have recently shown great promise. In contrast to generative approaches, these contrastive models learn a deterministic encoder with no notion of uncertainty or confidence. In this paper, we introduce a simple approach based on "contrasting distributions" that learns to assign uncertainty for pretrained contrastive representations. In particular, we train a deep network from a representation to a distribution in representation space, whose variance can be used as a measure of confidence. In our experiments, we show that this deep uncertainty model can be used (1) to visually interpret model behavior, (2) to detect new noise in the input to deployed models, (3) to detect anomalies, where we outperform 10 baseline methods across 11 tasks with improvements of up to 14% absolute, and (4) to classify out-of-distribution examples where our fully unsupervised model is competitive with supervised methods.
Conditional Negative Sampling for Contrastive Learning of Visual Representations
Oct 05, 2020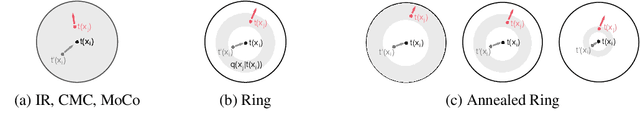
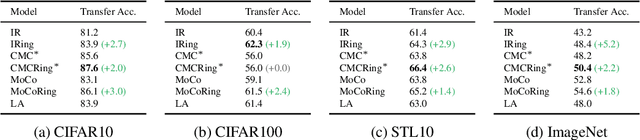

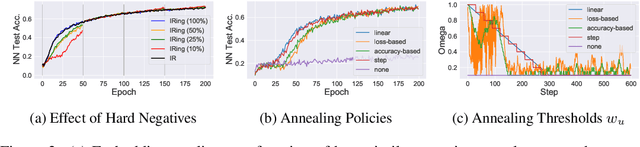
Recent methods for learning unsupervised visual representations, dubbed contrastive learning, optimize the noise-contrastive estimation (NCE) bound on mutual information between two views of an image. NCE uses randomly sampled negative examples to normalize the objective. In this paper, we show that choosing difficult negatives, or those more similar to the current instance, can yield stronger representations. To do this, we introduce a family of mutual information estimators that sample negatives conditionally -- in a "ring" around each positive. We prove that these estimators lower-bound mutual information, with higher bias but lower variance than NCE. Experimentally, we find our approach, applied on top of existing models (IR, CMC, and MoCo) improves accuracy by 2-5% points in each case, measured by linear evaluation on four standard image datasets. Moreover, we find continued benefits when transferring features to a variety of new image distributions from the Meta-Dataset collection and to a variety of downstream tasks such as object detection, instance segmentation, and keypoint detection.
On Mutual Information in Contrastive Learning for Visual Representations
Jun 05, 2020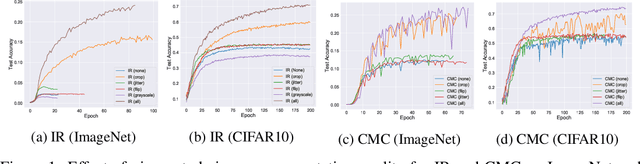
In recent years, several unsupervised, "contrastive" learning algorithms in vision have been shown to learn representations that perform remarkably well on transfer tasks. We show that this family of algorithms maximizes a lower bound on the mutual information between two or more "views" of an image where typical views come from a composition of image augmentations. Our bound generalizes the InfoNCE objective to support negative sampling from a restricted region of "difficult" contrasts. We find that the choice of negative samples and views are critical to the success of these algorithms. Reformulating previous learning objectives in terms of mutual information also simplifies and stabilizes them. In practice, our new objectives yield representations that outperform those learned with previous approaches for transfer to classification, bounding box detection, instance segmentation, and keypoint detection. % experiments show that choosing more difficult negative samples results in a stronger representation, outperforming those learned with IR, LA, and CMC in classification, bounding box detection, instance segmentation, and keypoint detection. The mutual information framework provides a unifying comparison of approaches to contrastive learning and uncovers the choices that impact representation learning.
Investigating Transferability in Pretrained Language Models
Apr 30, 2020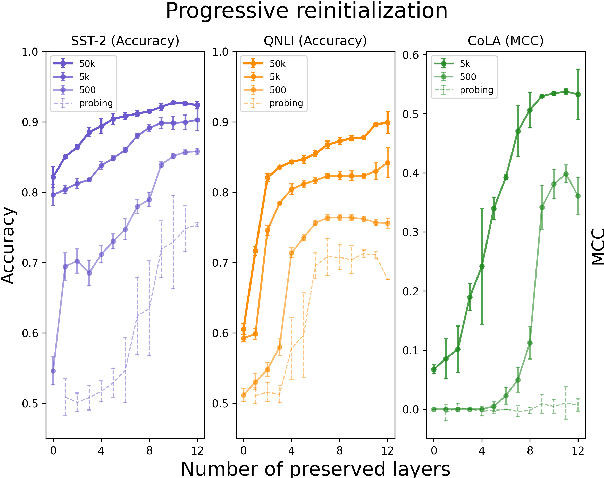
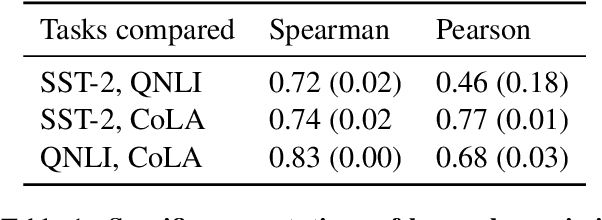
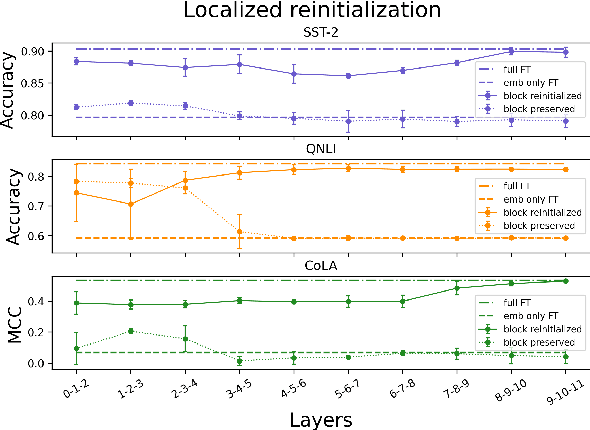
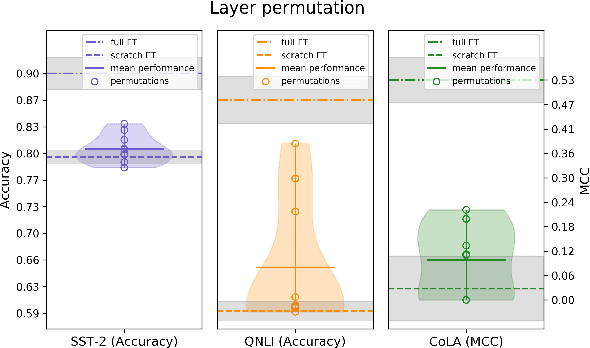
While probing is a common technique for identifying knowledge in the representations of pretrained models, it is unclear whether this technique can explain the downstream success of models like BERT which are trained end-to-end during finetuning. To address this question, we compare probing with a different measure of transferability: the decrease in finetuning performance of a partially-reinitialized model. This technique reveals that in BERT, layers with high probing accuracy on downstream GLUE tasks are neither necessary nor sufficient for high accuracy on those tasks. In addition, dataset size impacts layer transferability: the less finetuning data one has, the more important the middle and later layers of BERT become. Furthermore, BERT does not simply find a better initializer for individual layers; instead, interactions between layers matter and reordering BERT's layers prior to finetuning significantly harms evaluation metrics. These results provide a way of understanding the transferability of parameters in pretrained language models, revealing the fluidity and complexity of transfer learning in these models.
Variational Item Response Theory: Fast, Accurate, and Expressive
Feb 01, 2020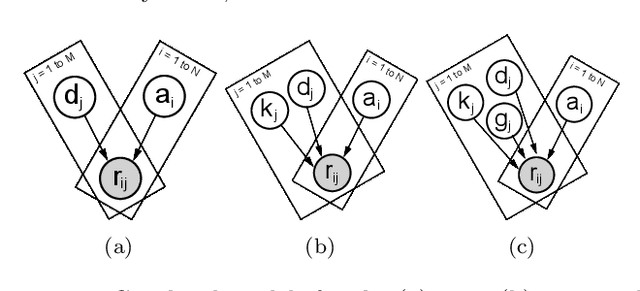
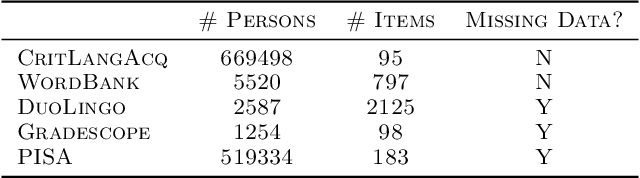
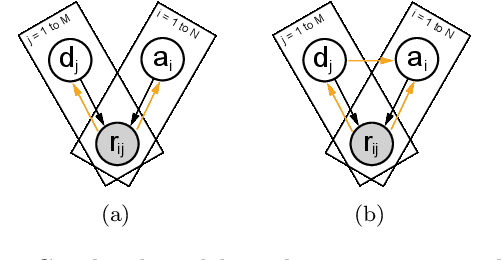
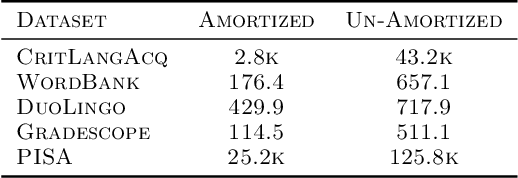
Item Response Theory is a ubiquitous algorithm used around the world to understand humans based on their responses to questions in fields as diverse as education, medicine and psychology. However, for medium to large datasets, contemporary solutions pose a tradeoff: either have bayesian, interpretable, accurate estimates or have fast computation. We introduce variational inference and deep generative models to Item Response Theory to offer the best of both worlds. The resulting algorithm is (a) orders of magnitude faster when inferring on the classical model, (b) naturally extends to more complicated input than binary correct/incorrect, and more expressive deep bayesian models of responses. Applying this method to five large-scale item response datasets from cognitive science and education, we find improvements in imputing missing data and better log likelihoods. The open-source algorithm is immediately usable.