 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis of Neural Language Modeling at Multiple Scales
Mar 22, 2018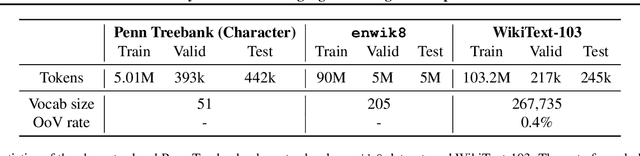
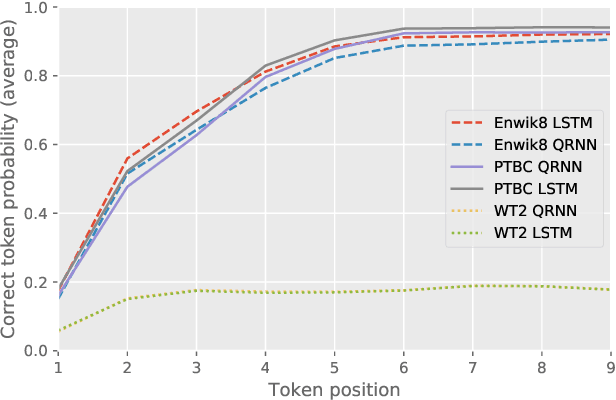
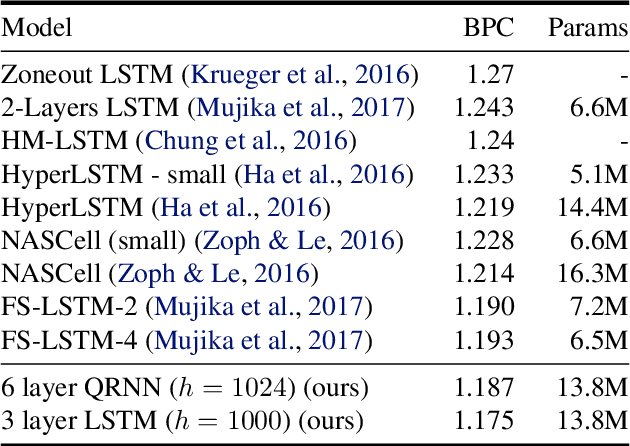
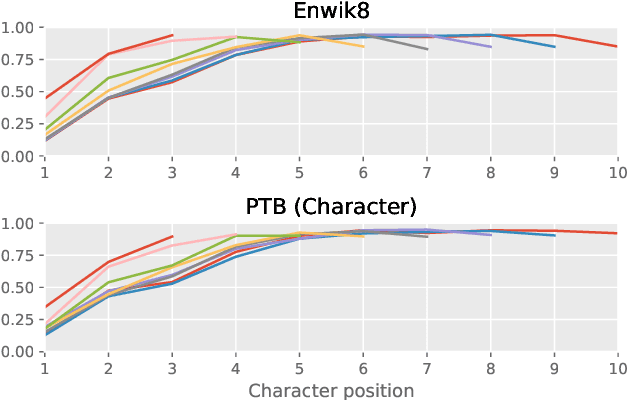
Many of the leading approaches in language modeling introduce novel, complex and specialized architectures. We take existing state-of-the-art word level language models based on LSTMs and QRNNs and extend them to both larger vocabularies as well as character-level granularity. When properly tuned, LSTMs and QRNNs achieve state-of-the-art results on character-level (Penn Treebank, enwik8) and word-level (WikiText-103) datasets, respectively. Results are obtained in only 12 hours (WikiText-103) to 2 days (enwik8) using a single modern GPU.
Improving Generalization Performance by Switching from Adam to SGD
Dec 20, 2017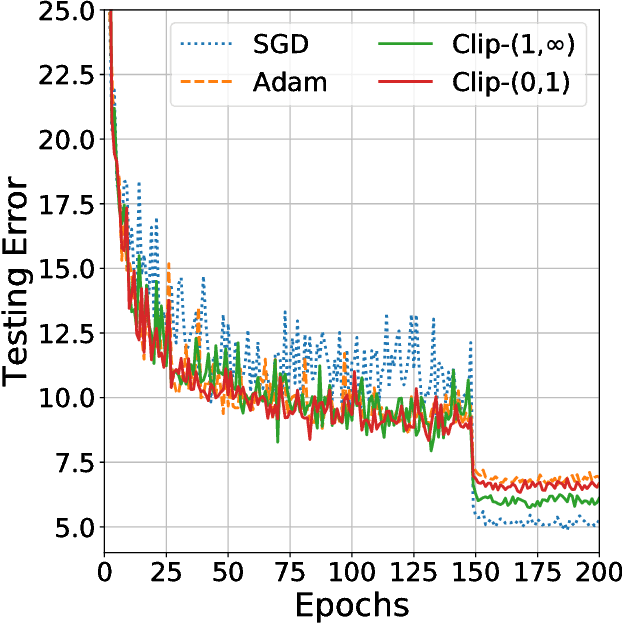
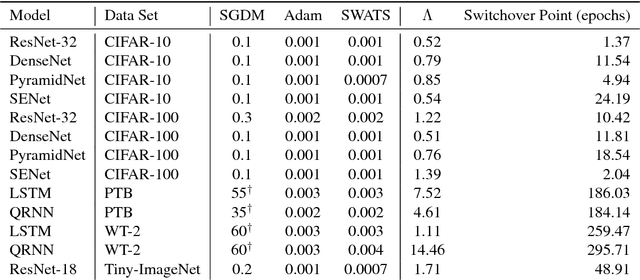
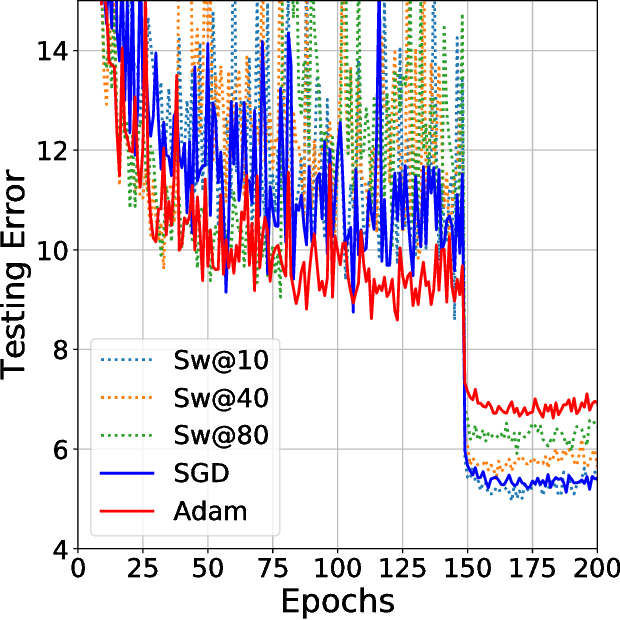
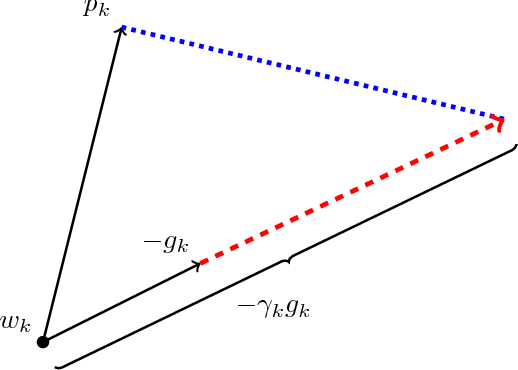
Despite superior training outcomes, adaptive optimization methods such as Adam, Adagrad or RMSprop have been found to generalize poorly compared to Stochastic gradient descent (SGD). These methods tend to perform well in the initial portion of training but are outperformed by SGD at later stages of training. We investigate a hybrid strategy that begins training with an adaptive method and switches to SGD when appropriate. Concretely, we propose SWATS, a simple strategy which switches from Adam to SGD when a triggering condition is satisfied. The condition we propose relates to the projection of Adam steps on the gradient subspace. By design, the monitoring process for this condition adds very little overhead and does not increase the number of hyperparameters in the optimizer. We report experiments on several standard benchmarks such as: ResNet, SENet, DenseNet and PyramidNet for the CIFAR-10 and CIFAR-100 data sets, ResNet on the tiny-ImageNet data set and language modeling with recurrent networks on the PTB and WT2 data sets. The results show that our strategy is capable of closing the generalization gap between SGD and Adam on a majority of the tasks.
Weighted Transformer Network for Machine Translation
Nov 06, 2017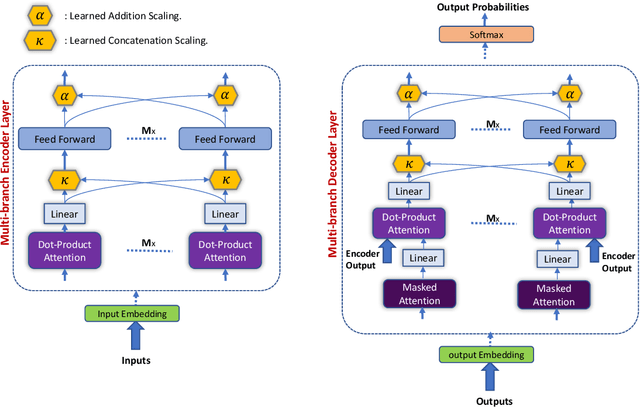
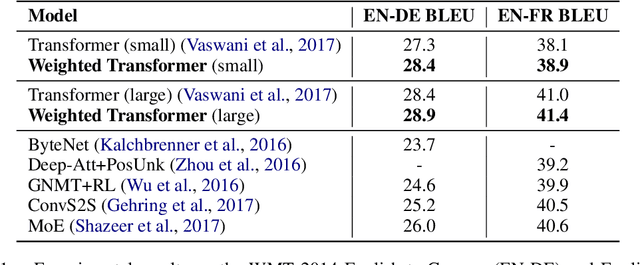
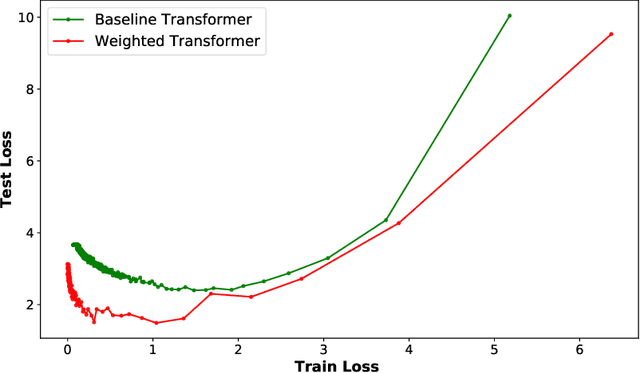
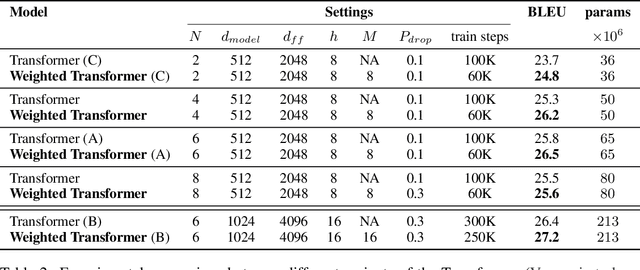
State-of-the-art results on neural machine translation often use attentional sequence-to-sequence models with some form of convolution or recursion. Vaswani et al. (2017) propose a new architecture that avoids recurrence and convolution completely. Instead, it uses only self-attention and feed-forward layers. While the proposed architecture achieves state-of-the-art results on several machine translation tasks, it requires a large number of parameters and training iterations to converge. We propose Weighted Transformer, a Transformer with modified attention layers, that not only outperforms the baseline network in BLEU score but also converges 15-40% faster. Specifically, we replace the multi-head attention by multiple self-attention branches that the model learns to combine during the training process. Our model improves the state-of-the-art performance by 0.5 BLEU points on the WMT 2014 English-to-German translation task and by 0.4 on the English-to-French translation task.
Regularizing and Optimizing LSTM Language Models
Aug 07, 2017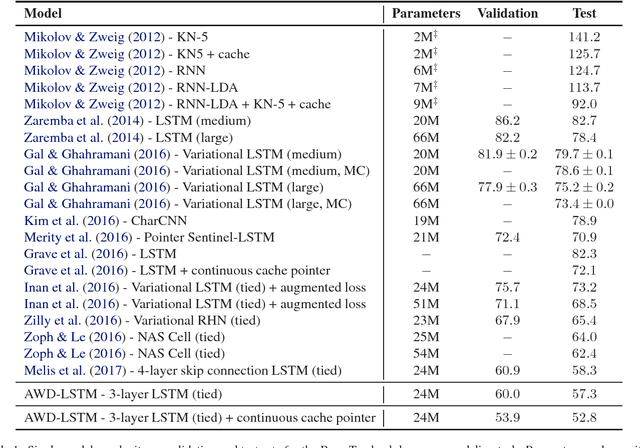

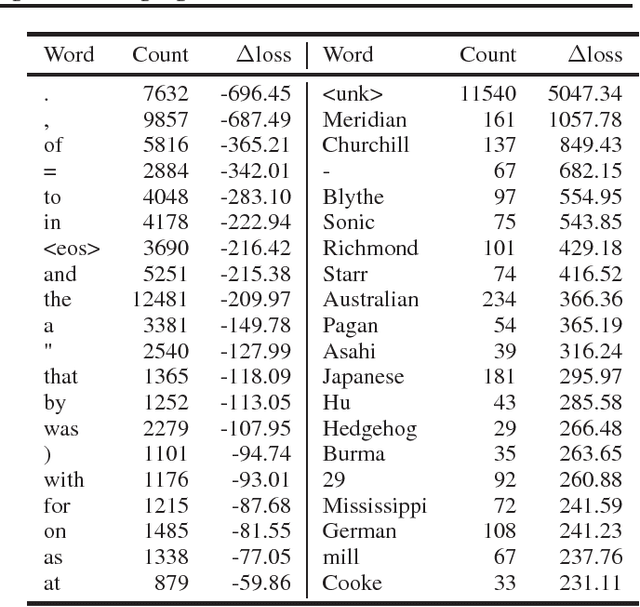
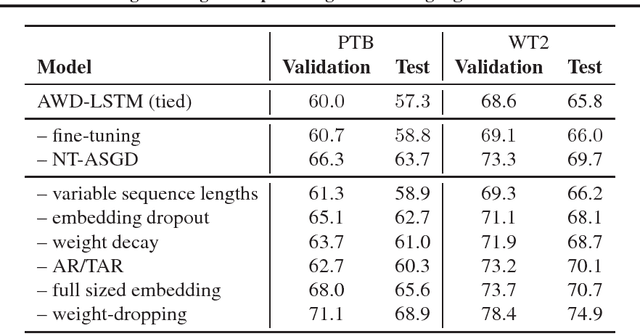
Recurrent neural networks (RNNs), such as long short-term memory networks (LSTMs), serve as a fundamental building block for many sequence learning tasks, including machine translation, language modeling, and question answering. In this paper, we consider the specific problem of word-level language modeling and investigate strategies for regularizing and optimizing LSTM-based models. We propose the weight-dropped LSTM which uses DropConnect on hidden-to-hidden weights as a form of recurrent regularization. Further, we introduce NT-ASGD, a variant of the averaged stochastic gradient method, wherein the averaging trigger is determined using a non-monotonic condition as opposed to being tuned by the user. Using these and other regularization strategies, we achieve state-of-the-art word level perplexities on two data sets: 57.3 on Penn Treebank and 65.8 on WikiText-2. In exploring the effectiveness of a neural cache in conjunction with our proposed model, we achieve an even lower state-of-the-art perplexity of 52.8 on Penn Treebank and 52.0 on WikiText-2.
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Feb 09, 2017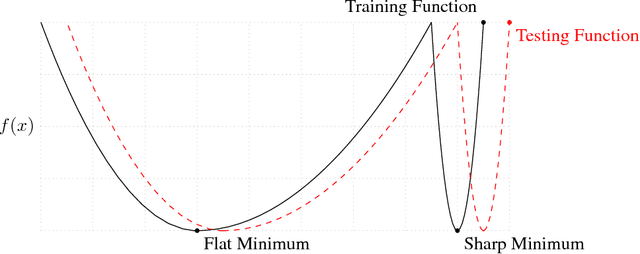
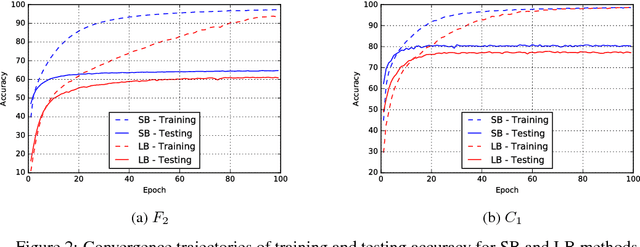
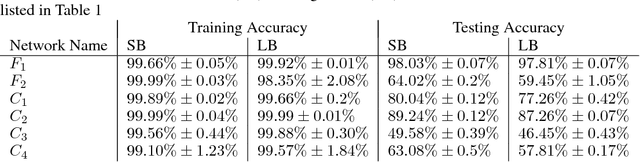
The stochastic gradient descent (SGD) method and its variants are algorithms of choice for many Deep Learning tasks. These methods operate in a small-batch regime wherein a fraction of the training data, say $32$-$512$ data points, is sampled to compute an approximation to the gradient. It has been observed in practice that when using a larger batch there is a degradation in the quality of the model, as measured by its ability to generalize. We investigate the cause for this generalization drop in the large-batch regime and present numerical evidence that supports the view that large-batch methods tend to converge to sharp minimizers of the training and testing functions - and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers, and our experiments support a commonly held view that this is due to the inherent noise in the gradient estimation. We discuss several strategies to attempt to help large-batch methods eliminate this generalization gap.
adaQN: An Adaptive Quasi-Newton Algorithm for Training RNNs
Feb 23, 2016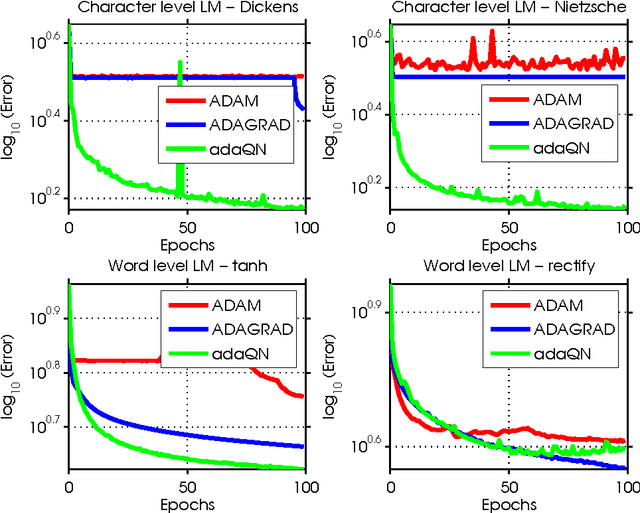
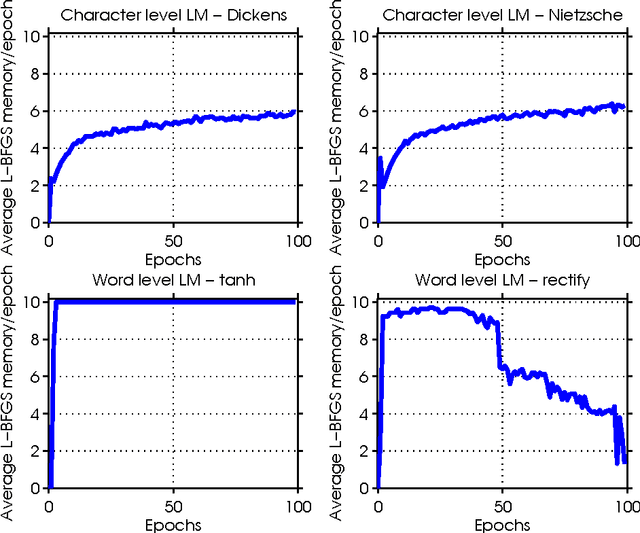
Recurrent Neural Networks (RNNs) are powerful models that achieve exceptional performance on several pattern recognition problems. However, the training of RNNs is a computationally difficult task owing to the well-known "vanishing/exploding" gradient problem. Algorithms proposed for training RNNs either exploit no (or limited) curvature information and have cheap per-iteration complexity, or attempt to gain significant curvature information at the cost of increased per-iteration cost. The former set includes diagonally-scaled first-order methods such as ADAGRAD and ADAM, while the latter consists of second-order algorithms like Hessian-Free Newton and K-FAC. In this paper, we present adaQN, a stochastic quasi-Newton algorithm for training RNNs. Our approach retains a low per-iteration cost while allowing for non-diagonal scaling through a stochastic L-BFGS updating scheme. The method uses a novel L-BFGS scaling initialization scheme and is judicious in storing and retaining L-BFGS curvature pairs. We present numerical experiments on two language modeling tasks and show that adaQN is competitive with popular RNN training algorithms.