 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTRL: A Conditional Transformer Language Model for Controllable Generation
Sep 20, 2019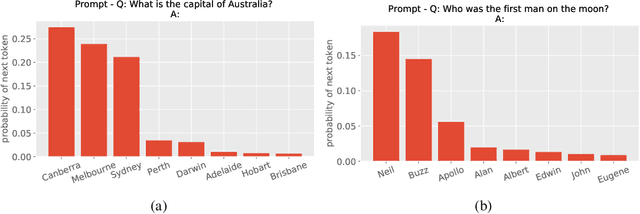



Large-scale language models show promising text generation capabilities, but users cannot easily control particular aspects of the generated text. We release CTRL, a 1.63 billion-parameter conditional transformer language model, trained to condition on control codes that govern style, content, and task-specific behavior. Control codes were derived from structure that naturally co-occurs with raw text, preserving the advantages of unsupervised learning while providing more explicit control over text generation. These codes also allow CTRL to predict which parts of the training data are most likely given a sequence. This provides a potential method for analyzing large amounts of data via model-based source attribution. We have released multiple full-sized, pretrained versions of CTRL at https://github.com/salesforce/ctrl.
Pretrained AI Models: Performativity, Mobility, and Change
Sep 07, 2019
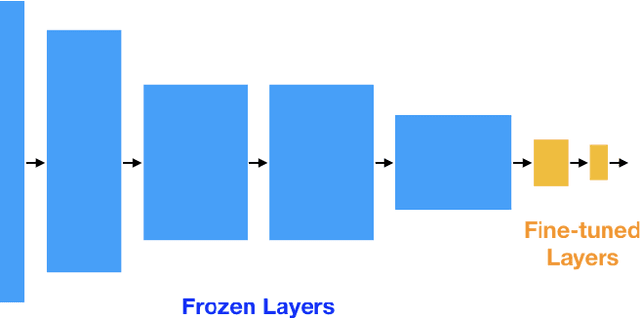
The paradigm of pretrained deep learning models has recently emerged in artificial intelligence practice, allowing deployment in numerous societal settings with limited computational resources, but also embedding biases and enabling unintended negative uses. In this paper, we treat pretrained models as objects of study and discuss the ethical impacts of their sociological position. We discuss how pretrained models are developed and compared under the common task framework, but that this may make self-regulation inadequate. Further how pretrained models may have a performative effect on society that exacerbates biases. We then discuss how pretrained models move through actor networks as a kind of computationally immutable mobile, but that users also act as agents of technological change by reinterpreting them via fine-tuning and transfer. We further discuss how users may use pretrained models in malicious ways, drawing a novel connection between the responsible innovation and user-centered innovation literatures. We close by discussing how this sociological understanding of pretrained models can inform AI governance frameworks for fairness, accountability, and transparency.
Neural Text Summarization: A Critical Evaluation
Aug 23, 2019
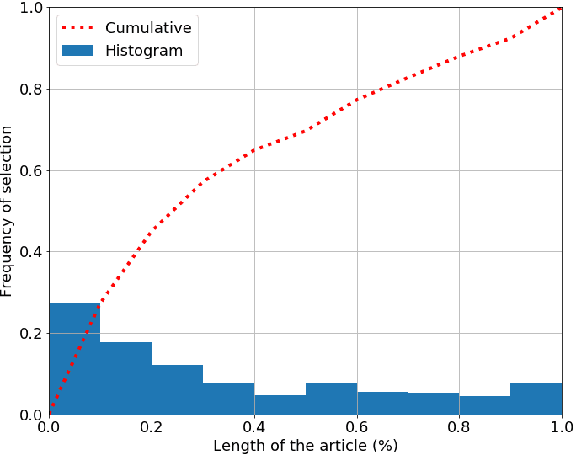
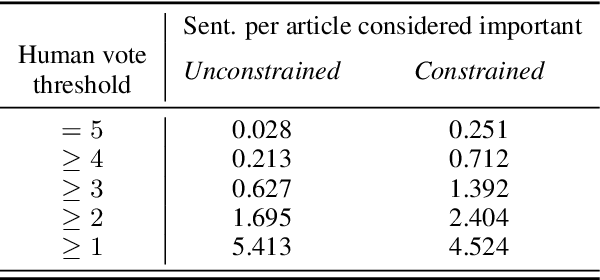
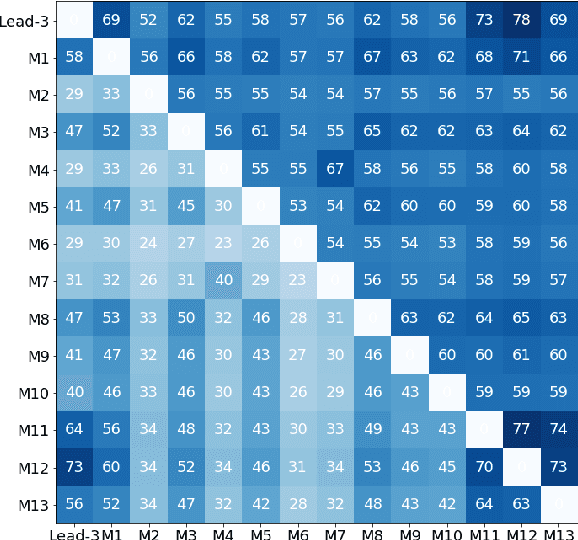
Text summarization aims at compressing long documents into a shorter form that conveys the most important parts of the original document. Despite increased interest in the community and notable research effort, progress on benchmark datasets has stagnated. We critically evaluate key ingredients of the current research setup: datasets, evaluation metrics, and models, and highlight three primary shortcomings: 1) automatically collected datasets leave the task underconstrained and may contain noise detrimental to training and evaluation, 2) current evaluation protocol is weakly correlated with human judgment and does not account for important characteristics such as factual correctness, 3) models overfit to layout biases of current datasets and offer limited diversity in their outputs.
XLDA: Cross-Lingual Data Augmentation for Natural Language Inference and Question Answering
May 27, 2019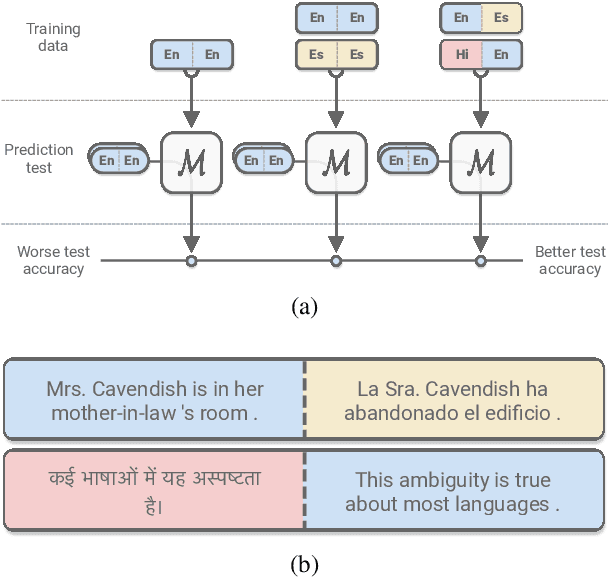
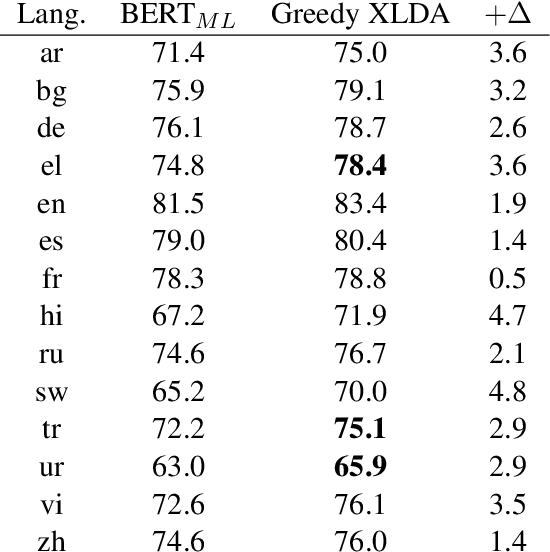
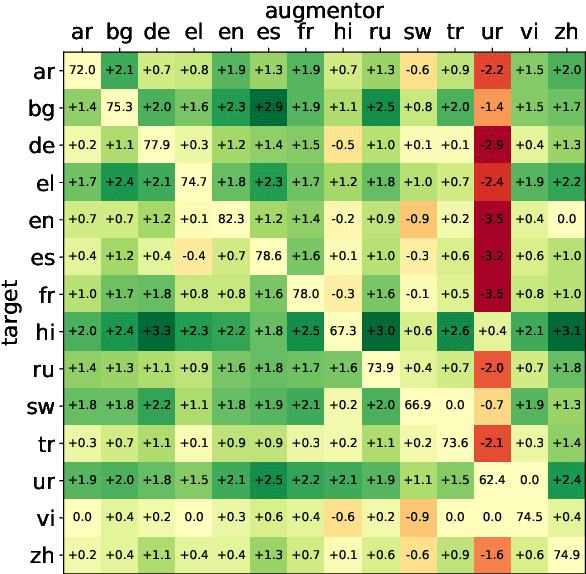
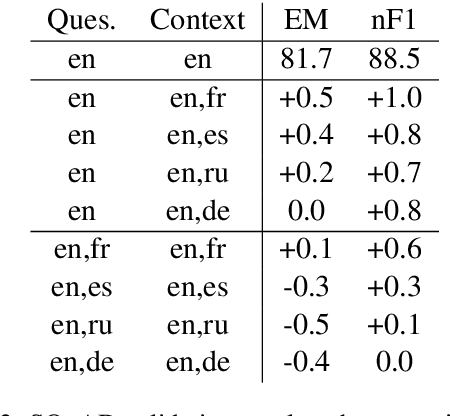
While natural language processing systems often focus on a single language, multilingual transfer learning has the potential to improve performance, especially for low-resource languages. We introduce XLDA, cross-lingual data augmentation, a method that replaces a segment of the input text with its translation in another language. XLDA enhances performance of all 14 tested languages of the cross-lingual natural language inference (XNLI) benchmark. With improvements of up to $4.8\%$, training with XLDA achieves state-of-the-art performance for Greek, Turkish, and Urdu. XLDA is in contrast to, and performs markedly better than, a more naive approach that aggregates examples in various languages in a way that each example is solely in one language. On the SQuAD question answering task, we see that XLDA provides a $1.0\%$ performance increase on the English evaluation set. Comprehensive experiments suggest that most languages are effective as cross-lingual augmentors, that XLDA is robust to a wide range of translation quality, and that XLDA is even more effective for randomly initialized models than for pretrained models.
Unifying Question Answering and Text Classification via Span Extraction
Apr 19, 2019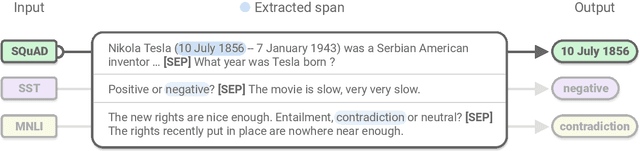

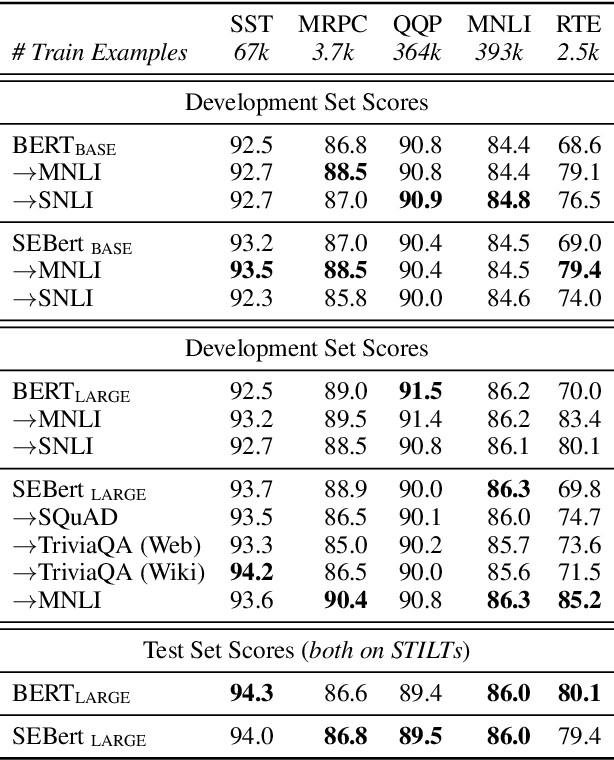

Even as pre-trained language encoders such as BERT are shared across many tasks, the output layers of question answering and text classification models are significantly different. Span decoders are frequently used for question answering and fixed-class, classification layers for text classification. We show that this distinction is not necessary, and that both can be unified as span extraction. A unified, span-extraction approach leads to superior or comparable performance in multi-task learning, low-data and supplementary supervised pretraining experiments on several text classification and question answering benchmarks.
Coarse-grain Fine-grain Coattention Network for Multi-evidence Question Answering
Jan 03, 2019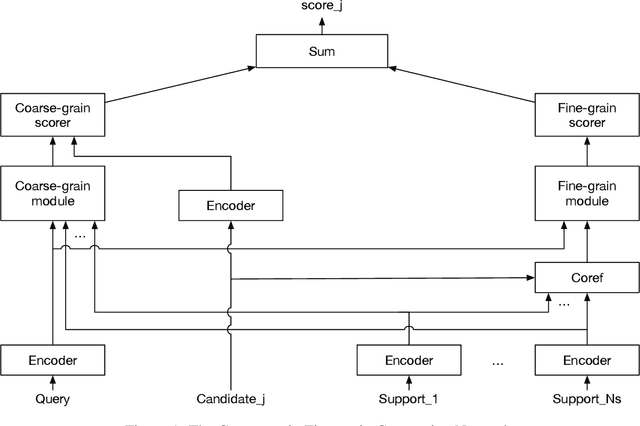
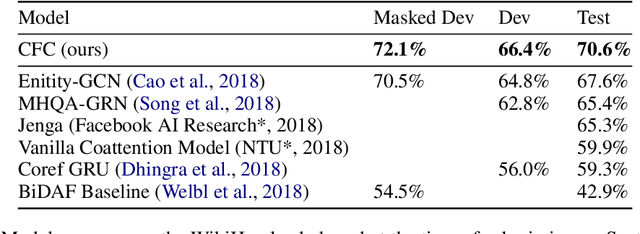
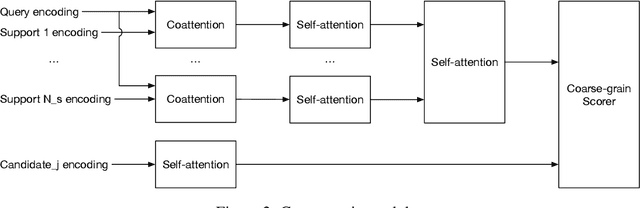
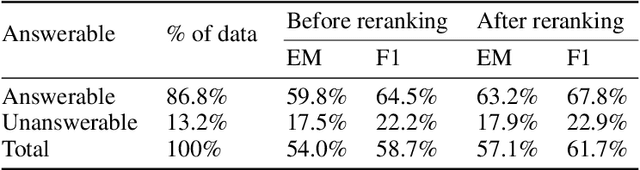
End-to-end neural models have made significant progress in question answering, however recent studies show that these models implicitly assume that the answer and evidence appear close together in a single document. In this work, we propose the Coarse-grain Fine-grain Coattention Network (CFC), a new question answering model that combines information from evidence across multiple documents. The CFC consists of a coarse-grain module that interprets documents with respect to the query then finds a relevant answer, and a fine-grain module which scores each candidate answer by comparing its occurrences across all of the documents with the query. We design these modules using hierarchies of coattention and self-attention, which learn to emphasize different parts of the input. On the Qangaroo WikiHop multi-evidence question answering task, the CFC obtains a new state-of-the-art result of 70.6% on the blind test set, outperforming the previous best by 3% accuracy despite not using pretrained contextual encoders.
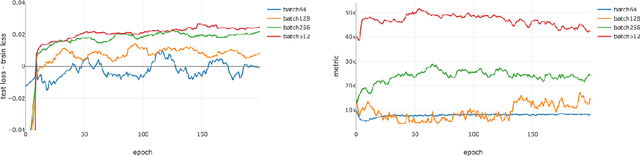
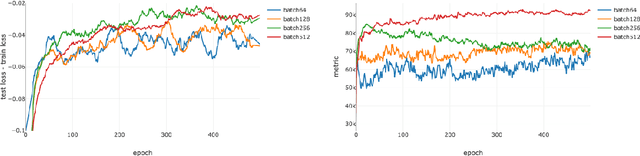
A Closer Look at Deep Learning Heuristics: Learning rate restarts, Warmup and Distillation
Oct 29, 2018
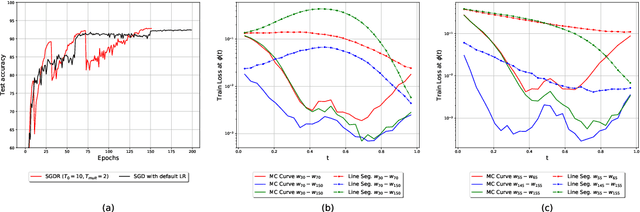
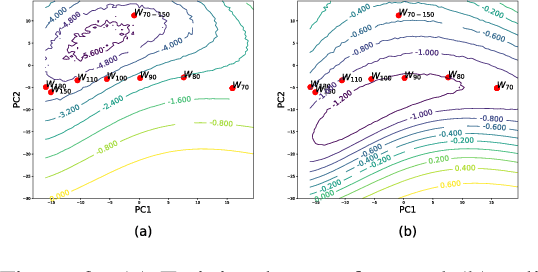
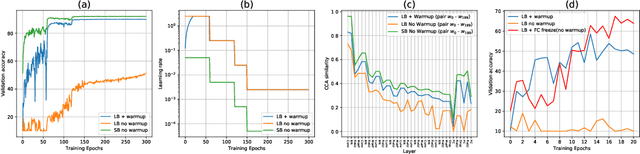
The convergence rate and final performance of common deep learning models have significantly benefited from heuristics such as learning rate schedules, knowledge distillation, skip connections, and normalization layers. In the absence of theoretical underpinnings, controlled experiments aimed at explaining these strategies can aid our understanding of deep learning landscapes and the training dynamics. Existing approaches for empirical analysis rely on tools of linear interpolation and visualizations with dimensionality reduction, each with their limitations. Instead, we revisit such analysis of heuristics through the lens of recently proposed methods for loss surface and representation analysis, viz., mode connectivity and canonical correlation analysis (CCA), and hypothesize reasons for the success of the heuristics. In particular, we explore knowledge distillation and learning rate heuristics of (cosine) restarts and warmup using mode connectivity and CCA. Our empirical analysis suggests that: (a) the reasons often quoted for the success of cosine annealing are not evidenced in practice; (b) that the effect of learning rate warmup is to prevent the deeper layers from creating training instability; and (c) that the latent knowledge shared by the teacher is primarily disbursed to the deeper layers.
Identifying Generalization Properties in Neural Networks
Sep 19, 2018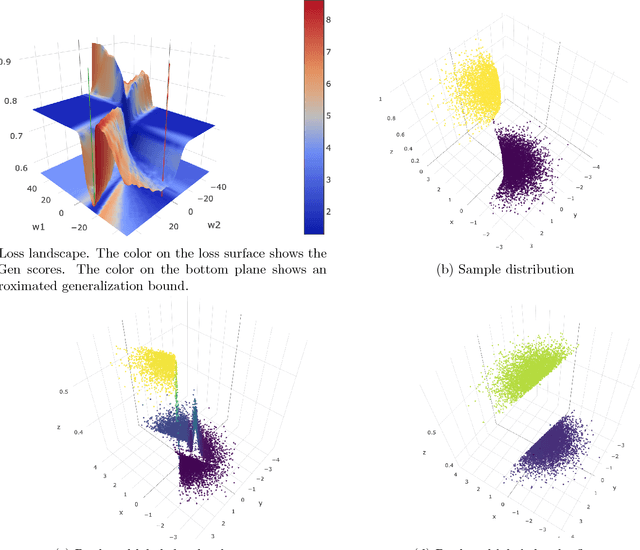
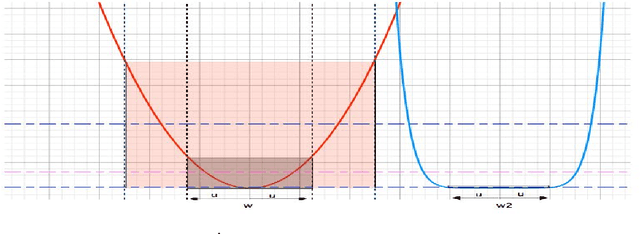
While it has not yet been proven, empirical evidence suggests that model generalization is related to local properties of the optima which can be described via the Hessian. We connect model generalization with the local property of a solution under the PAC-Bayes paradigm. In particular, we prove that model generalization ability is related to the Hessian, the higher-order "smoothness" terms characterized by the Lipschitz constant of the Hessian, and the scales of the parameters. Guided by the proof, we propose a metric to score the generalization capability of the model, as well as an algorithm that optimizes the perturbed model accordingly.
The Natural Language Decathlon: Multitask Learning as Question Answering
Jun 20, 2018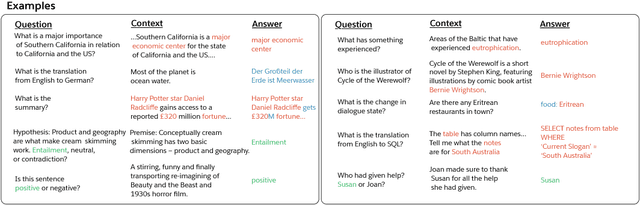
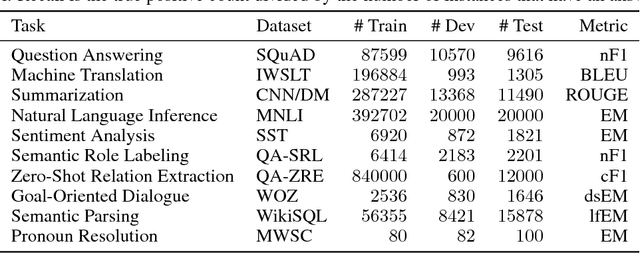
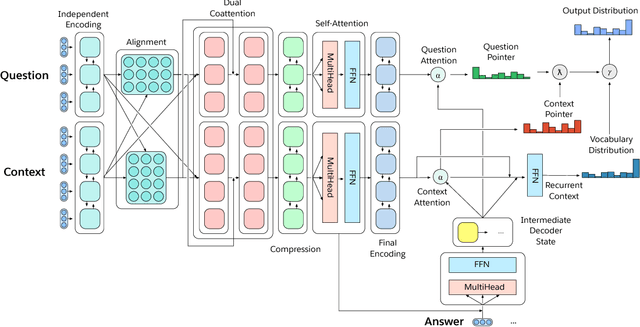
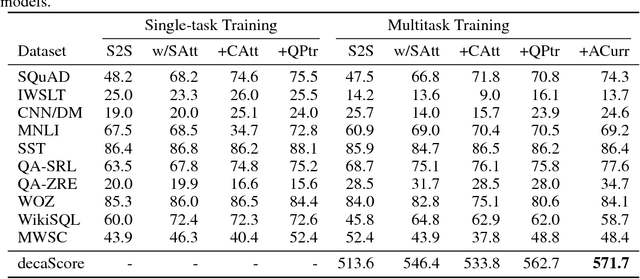
Deep learning has improved performance on many natural language processing (NLP) tasks individually. However, general NLP models cannot emerge within a paradigm that focuses on the particularities of a single metric, dataset, and task. We introduce the Natural Language Decathlon (decaNLP), a challenge that spans ten tasks: question answering, machine translation, summarization, natural language inference, sentiment analysis, semantic role labeling, zero-shot relation extraction, goal-oriented dialogue, semantic parsing, and commonsense pronoun resolution. We cast all tasks as question answering over a context. Furthermore, we present a new Multitask Question Answering Network (MQAN) jointly learns all tasks in decaNLP without any task-specific modules or parameters in the multitask setting. MQAN shows improvements in transfer learning for machine translation and named entity recognition, domain adaptation for sentiment analysis and natural language inference, and zero-shot capabilities for text classification. We demonstrate that the MQAN's multi-pointer-generator decoder is key to this success and performance further improves with an anti-curriculum training strategy. Though designed for decaNLP, MQAN also achieves state of the art results on the WikiSQL semantic parsing task in the single-task setting. We also release code for procuring and processing data, training and evaluating models, and reproducing all experiments for decaNLP.
Using Mode Connectivity for Loss Landscape Analysis
Jun 18, 2018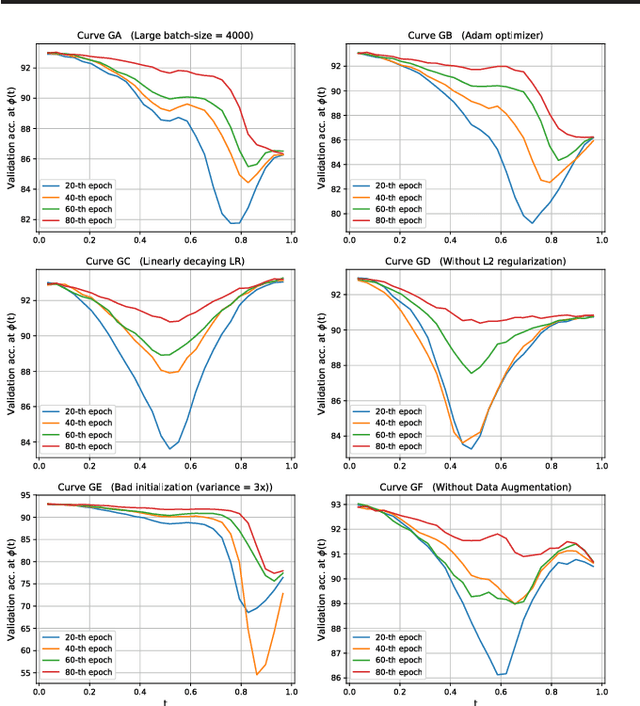
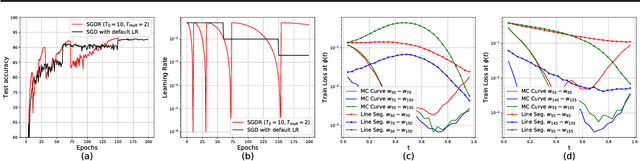
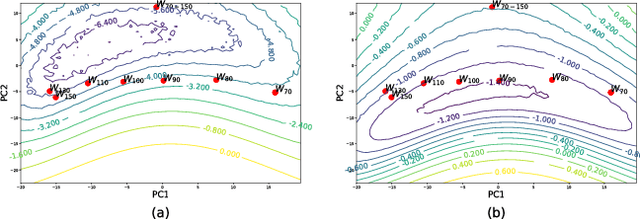
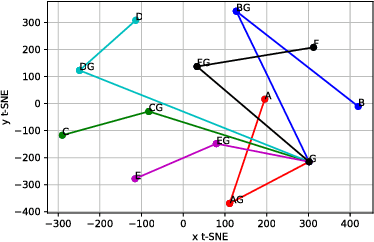
Mode connectivity is a recently introduced frame- work that empirically establishes the connected- ness of minima by finding a high accuracy curve between two independently trained models. To investigate the limits of this setup, we examine the efficacy of this technique in extreme cases where the input models are trained or initialized differently. We find that the procedure is resilient to such changes. Given this finding, we propose using the framework for analyzing loss surfaces and training trajectories more generally, and in this direction, study SGD with cosine annealing and restarts (SGDR). We report that while SGDR moves over barriers in its trajectory, propositions claiming that it converges to and escapes from multiple local minima are not substantiated by our empirical results.