 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDEInvBench: A Comprehensive Dataset and Design Space Exploration of Neural Networks for PDE Inverse Problems
May 26, 2026Inverse problems in partial differential equations (PDEs) involve estimating the physical parameters of a system from observed spatiotemporal solution fields. Neural networks are well-suited for PDE parameter estimation due to their capability to model function-to-function space transformations. While existing benchmarks of machine learning methods for PDEs primarily focus on the forward problem, there are no similar comprehensive studies and benchmark datasets on PDE inverse problems, i.e., mapping solution fields to underlying physical parameters. We fill this gap by introducing PDEInvBench, a comprehensive benchmark dataset consisting of numerical simulations for both time-dependent and time-independent PDEs across a wide range of physical behaviors and parameters. Our dataset includes evaluation splits that assess performance in both in-distribution and various out-of-distribution settings. Using our benchmark dataset, we comprehensively explore the design space of neural networks for PDE inverse problems along three key dimensions: (1) optimization procedures, analyzing the role of supervised, self-supervised, and test-time training objectives on performance, (2) problem representations, where we study the value of architectural choices with different inductive biases and various conditioning strategies, and (3) scaling, which we perform with respect to both model and data size. Our experiments reveal several practical insights: 1) neural networks perform best with a two-stage training procedure: initial supervision with PDE parameters followed by test-time fine-tuning using the PDE residual, 2) incorporating PDE derivatives as input features consistently improves accuracy, and 3) increasing the diversity of initial conditions in the training data yields greater performance gains than expanding the range of PDE parameters. We make our dataset and codebase publicly available.
* 37 total pages, 13 main pages, 20 figures, 8 tables. Published in Transactions on Machine Learning Research (TMLR), 2026
Scaling physics-informed hard constraints with mixture-of-experts
Feb 20, 2024Imposing known physical constraints, such as conservation laws, during neural network training introduces an inductive bias that can improve accuracy, reliability, convergence, and data efficiency for modeling physical dynamics. While such constraints can be softly imposed via loss function penalties, recent advancements in differentiable physics and optimization improve performance by incorporating PDE-constrained optimization as individual layers in neural networks. This enables a stricter adherence to physical constraints. However, imposing hard constraints significantly increases computational and memory costs, especially for complex dynamical systems. This is because it requires solving an optimization problem over a large number of points in a mesh, representing spatial and temporal discretizations, which greatly increases the complexity of the constraint. To address this challenge, we develop a scalable approach to enforce hard physical constraints using Mixture-of-Experts (MoE), which can be used with any neural network architecture. Our approach imposes the constraint over smaller decomposed domains, each of which is solved by an "expert" through differentiable optimization. During training, each expert independently performs a localized backpropagation step by leveraging the implicit function theorem; the independence of each expert allows for parallelization across multiple GPUs. Compared to standard differentiable optimization, our scalable approach achieves greater accuracy in the neural PDE solver setting for predicting the dynamics of challenging non-linear systems. We also improve training stability and require significantly less computation time during both training and inference stages.
Neural Spectral Methods: Self-supervised learning in the spectral domain
Dec 08, 2023We present Neural Spectral Methods, a technique to solve parametric Partial Differential Equations (PDEs), grounded in classical spectral methods. Our method uses orthogonal bases to learn PDE solutions as mappings between spectral coefficients. In contrast to current machine learning approaches which enforce PDE constraints by minimizing the numerical quadrature of the residuals in the spatiotemporal domain, we leverage Parseval's identity and introduce a new training strategy through a \textit{spectral loss}. Our spectral loss enables more efficient differentiation through the neural network, and substantially reduces training complexity. At inference time, the computational cost of our method remains constant, regardless of the spatiotemporal resolution of the domain. Our experimental results demonstrate that our method significantly outperforms previous machine learning approaches in terms of speed and accuracy by one to two orders of magnitude on multiple different problems. When compared to numerical solvers of the same accuracy, our method demonstrates a $10\times$ increase in performance speed.
TopoAct: Exploring the Shape of Activations in Deep Learning
Dec 13, 2019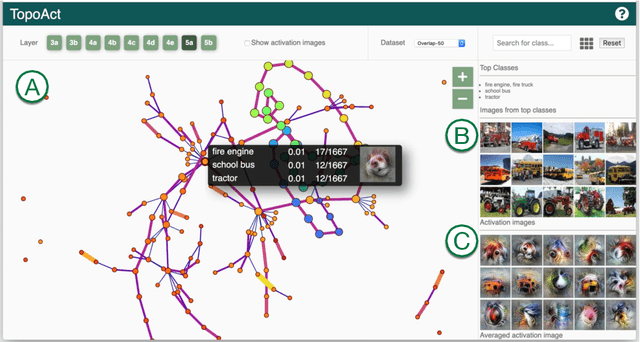
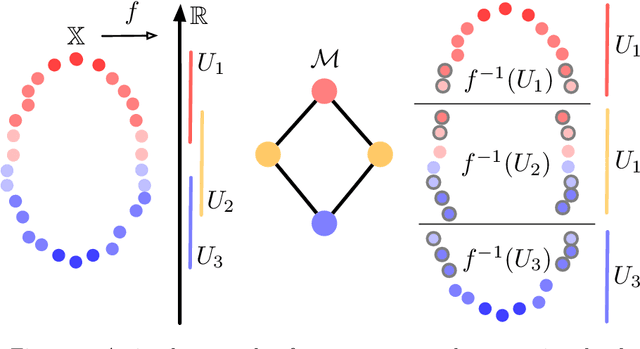
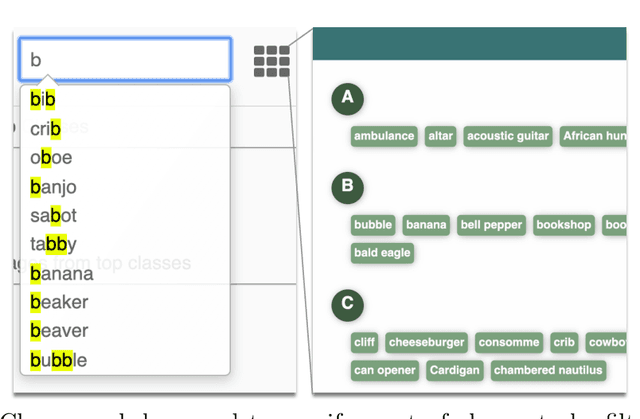
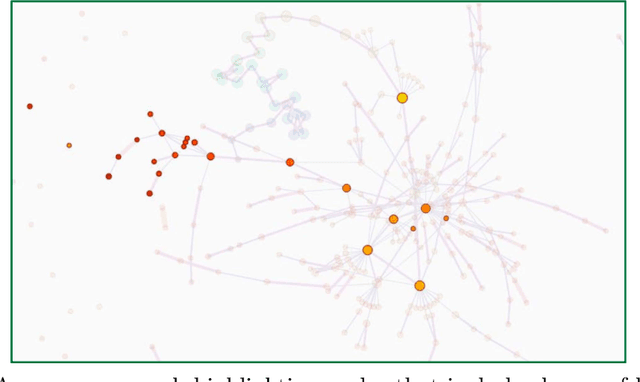
Deep neural networks such as GoogLeNet and ResNet have achieved superhuman performance in tasks like image classification. To understand how such superior performance is achieved, we can probe a trained deep neural network by studying neuron activations, that is, combinations of neuron firings, at any layer of the network in response to a particular input. With a large set of input images, we aim to obtain a global view of what neurons detect by studying their activations. We ask the following questions: What is the shape of the space of activations? That is, what is the organizational principle behind neuron activations, and how are the activations related within a layer and across layers? Applying tools from topological data analysis, we present TopoAct, a visual exploration system used to study topological summaries of activation vectors for a single layer as well as the evolution of such summaries across multiple layers. We present visual exploration scenarios using TopoAct that provide valuable insights towards learned representations of an image classifier.