 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Long-Horizon Dexterous Manipulation via Multi-View 3D-Grounded VLM Reasoning
Jun 17, 2026We present a zero-shot framework for long-horizon dexterous manipulation that grounds language instructions into executable 3D task plans from calibrated multi-view RGB images. Rather than training an end-to-end policy, our system uses a vision-language model (VLM) to produce reference-frame task grounding and primitive-level 2D keypoints, then lifts them into 3D via multi-view fusion. This lifting combines triangulation of view-wise VLM groundings with reference-view ray voting, which searches along a semantic camera ray for geometrically consistent candidates across neighboring views. The resulting 3D keypoints support both pick-and-place and tool-use: for tool-use, we retrieve an object-centric atomic action corresponding to the inferred skill category and align its stored 6D tool trajectory to the scene; for dexterous execution, we expand the lifted grasp keypoint into a task-conditioned grasp affordance region and generate feasible grasp-motion pairs with an arm-hand motion generator. Real-world experiments show improved 3D grounding accuracy and execution reliability over single-view RGB-D grounding and fine-tuned VLA baselines. We further demonstrate long-horizon manipulation through closed-loop status verification and replan, enabling zero-shot execution on unseen objects and tool-use tasks in novel scenes.
More Human, More Efficient: Aligning Annotations with Quantized SLMs
Apr 01, 2026As Large Language Model (LLM) capabilities advance, the demand for high-quality annotation of exponentially increasing text corpora has outpaced human capacity, leading to the widespread adoption of LLMs in automatic evaluation and annotation. However, proprietary LLMs often exhibit systematic biases that diverge from human expert consensus, lacks reproducibility, and raises data privacy concerns. Our work examines the viability of finetuning a quantized Small Language Model of 1.7B parameter size on limited human-annotated data to serve as a highly aligned, deterministic evaluator and annotator. By implementing a custom, multi-dimensional rubric framework and simple augmentation and regularization techniques, the proposed approach achieves higher inter-annotator agreement (0.23 points increase in Krippendorff's $α$) than the best performing state-of-the-art proprietary LLM. We also demonstrate the generalizability of the proposed training pipeline on a separate emotion classification task. The results show that task-specific alignment and efficient 4-bit quantized fine-tuning provide superior open-source alternative to using proprietary models for evaluation and annotation. Our finetuning approach is publicly available at https://github.com/jylee-k/slm-judge.
Dexterous World Models
Dec 19, 2025



Recent progress in 3D reconstruction has made it easy to create realistic digital twins from everyday environments. However, current digital twins remain largely static and are limited to navigation and view synthesis without embodied interactivity. To bridge this gap, we introduce Dexterous World Model (DWM), a scene-action-conditioned video diffusion framework that models how dexterous human actions induce dynamic changes in static 3D scenes. Given a static 3D scene rendering and an egocentric hand motion sequence, DWM generates temporally coherent videos depicting plausible human-scene interactions. Our approach conditions video generation on (1) static scene renderings following a specified camera trajectory to ensure spatial consistency, and (2) egocentric hand mesh renderings that encode both geometry and motion cues to model action-conditioned dynamics directly. To train DWM, we construct a hybrid interaction video dataset. Synthetic egocentric interactions provide fully aligned supervision for joint locomotion and manipulation learning, while fixed-camera real-world videos contribute diverse and realistic object dynamics. Experiments demonstrate that DWM enables realistic and physically plausible interactions, such as grasping, opening, and moving objects, while maintaining camera and scene consistency. This framework represents a first step toward video diffusion-based interactive digital twins and enables embodied simulation from egocentric actions.
Word and Phrase Features in Graph Convolutional Network for Automatic Question Classification
Sep 04, 2024



Effective question classification is crucial for AI-driven educational tools, enabling adaptive learning systems to categorize questions by skill area, difficulty level, and competence. This classification not only supports educational diagnostics and analytics but also enhances complex tasks like information retrieval and question answering by associating questions with relevant categories. Traditional methods, often based on word embeddings and conventional classifiers, struggle to capture the nuanced relationships in natural language, leading to suboptimal performance. To address this, we propose a novel approach leveraging graph convolutional networks (GCNs), named Phrase Question-Graph Convolutional Network (PQ-GCN) to better model the inherent structure of questions. By representing questions as graphs -- where nodes signify words or phrases and edges denote syntactic or semantic relationships -- our method allows GCNs to learn from the interconnected nature of language more effectively. Additionally, we explore the incorporation of phrase-based features to enhance classification accuracy, especially in low-resource settings. Our findings demonstrate that GCNs, augmented with these features, offer a promising solution for more accurate and context-aware question classification, bridging the gap between graph neural network research and practical educational applications.
Teamwork Dimensions Classification Using BERT
Dec 09, 2023Teamwork is a necessary competency for students that is often inadequately assessed. Towards providing a formative assessment of student teamwork, an automated natural language processing approach was developed to identify teamwork dimensions of students' online team chat. Developments in the field of natural language processing and artificial intelligence have resulted in advanced deep transfer learning approaches namely the Bidirectional Encoder Representations from Transformers (BERT) model that allow for more in-depth understanding of the context of the text. While traditional machine learning algorithms were used in the previous work for the automatic classification of chat messages into the different teamwork dimensions, our findings have shown that classifiers based on the pre-trained language model BERT provides improved classification performance, as well as much potential for generalizability in the language use of varying team chat contexts and team member demographics. This model will contribute towards an enhanced learning analytics tool for teamwork assessment and feedback.
Latte: Cross-framework Python Package for Evaluation of Latent-Based Generative Models
Jan 22, 2022

Latte (for LATent Tensor Evaluation) is a Python library for evaluation of latent-based generative models in the fields of disentanglement learning and controllable generation. Latte is compatible with both PyTorch and TensorFlow/Keras, and provides both functional and modular APIs that can be easily extended to support other deep learning frameworks. Using NumPy-based and framework-agnostic implementation, Latte ensures reproducible, consistent, and deterministic metric calculations regardless of the deep learning framework of choice.
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021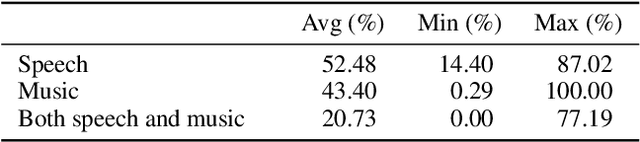
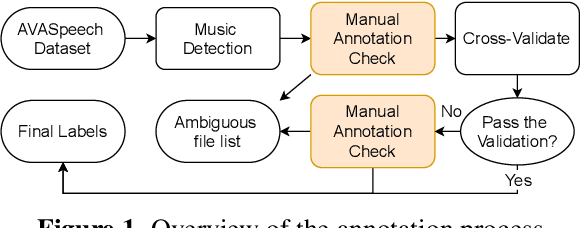

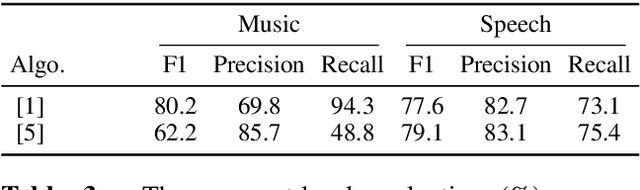
We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.